







起源

事情起源于同学的一个疑惑,他在阅读Transformer论文时,看到作者在前馈神经网络部分写有这么一句话:
Another way of describing this is as two convolutions with kernel size 1.
于是他向我问道“为什么全连接层可以用1*1卷积层代替呢?”
对卷积的理解尚不深刻的我被问住了,所以我立马开始搜索资料以解决这一问题。
下面将此问题相关的内容分析整理出来,以供复习。
解决
按照我之前的理解,对于一张 5 ∗ 5 5*5 5∗5的原始图像进行 1 ∗ 1 1*1 1∗1的卷积操作,就是对原图像的每个元素乘以一个卷积核参数得到 5 ∗ 5 5*5 5∗5的特征图,那这不就是直接逐元素乘以常数嘛喂!怎么可能代替全连接呢?!
之所以会有这个误会,是因为我们平常所说的 1 ∗ 1 1*1 1∗1卷积其实省略了一个重要的东西,实际上应为 1 ∗ 1 ∗ 输 入 通 道 数 1*1*输入通道数 1∗1∗输入通道数 卷积。
更广泛来说,当我们对K个通道的输入进行 n ∗ n n*n n∗n卷积时,我们需要一个shape为 [ n , n , k ] [n, n, k] [n,n,k]的kernel。
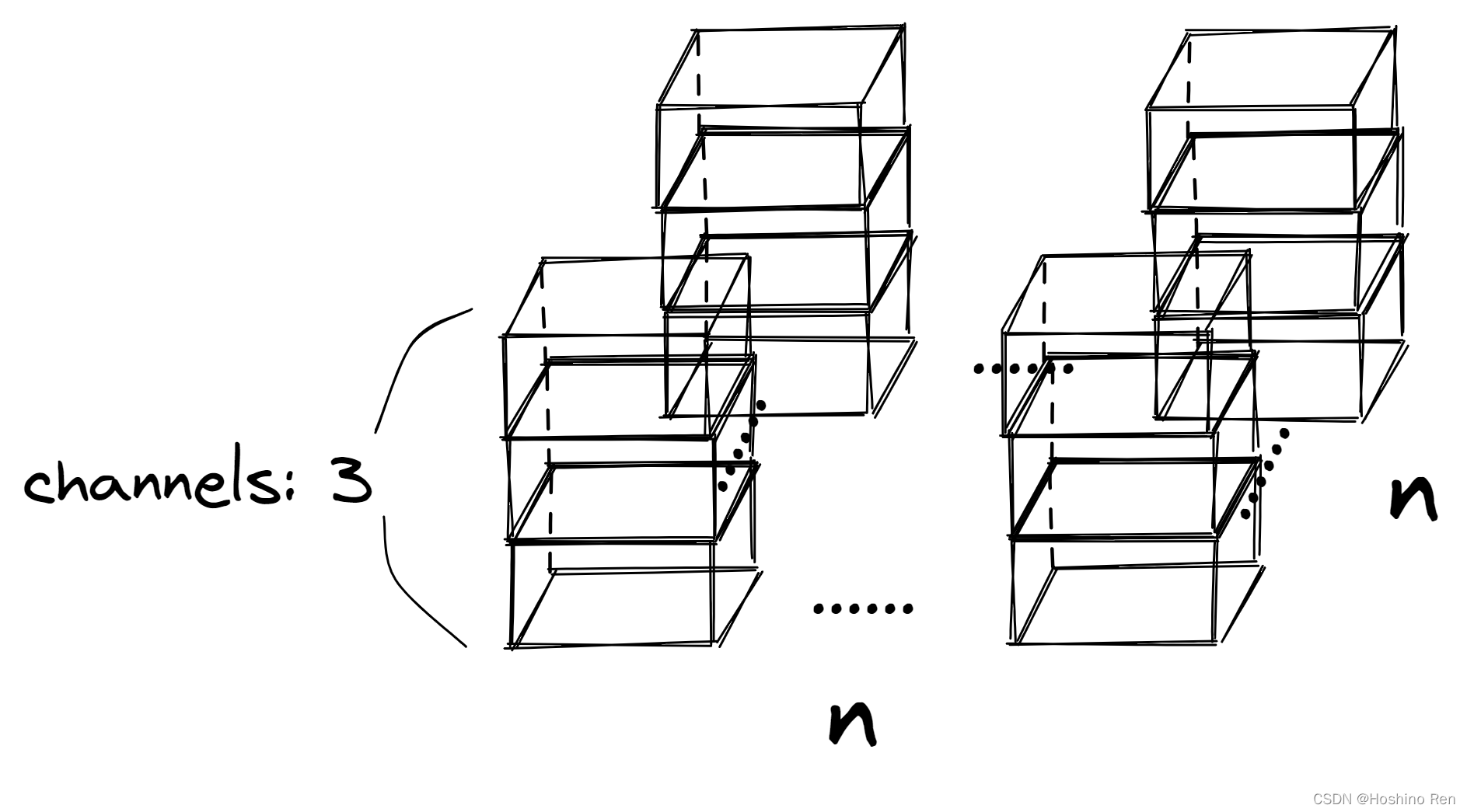
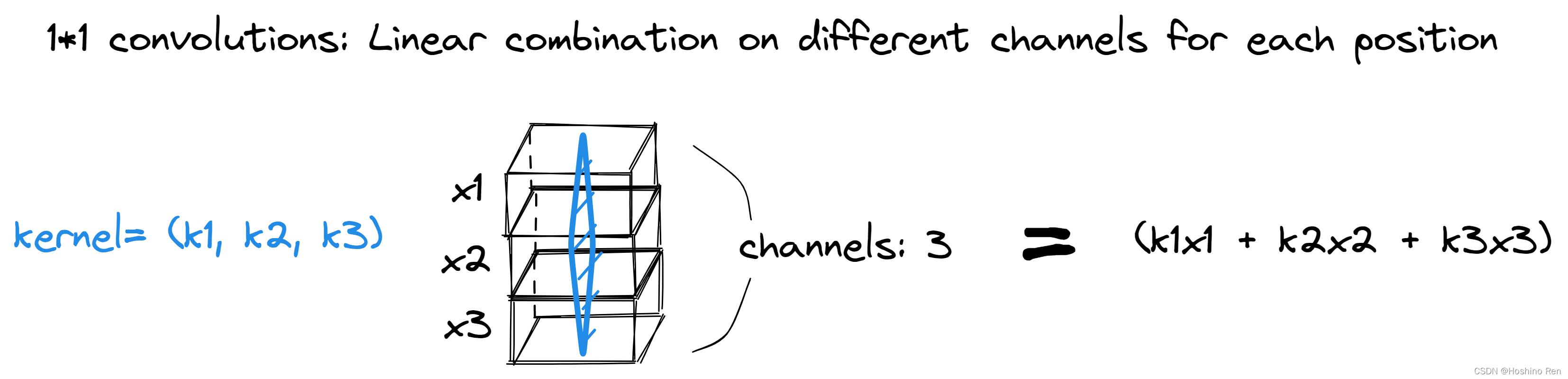
举个例子,对于一张 1 ∗ 1 1*1 1∗1的图像,它拥有RGB三个通道,我们想要执行 1 ∗ 1 1*1 1∗1的卷积操作,那么我们kernel的shape应为 [ 1 , 1 , 3 ] [1, 1, 3] [1,1,3]。
假设卷积核 k e r n e l = ( k 1 , k 2 , k 3 ) kernel = (k_1, k_2, k_3) kernel=(k1,k2,k3),同一空间位置不同通道的输入从上到下依次是 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3,那么输出特征图上对应位置应为 k 1 x 1 + k 2 x 2 + k 3 x 3 k_1x_1 + k_2x_2 + k_3x_3 k1x1+k2x2+k3x3。
所以说, 1 ∗ 1 1*1 1∗1卷积操作是在每个像素位置上,不同feature channels的线性叠加,其目的是保留原有图像平面结构的基础上,调整通道数(即depth),从而完成升维或降维的功能。
理解了这一点之后,就可以明白为什么 1 ∗ 1 1*1 1∗1卷积操作等价于一个全连接层了。
依旧举例说明,假如现在有一层全连接网络,输入层维度为3,输出层维度为2,具体参数如下:
W = ( 0 1 1 2 3 5 ) ∈ R 2 × 3 W = \begin{pmatrix} 0 & 1 & 1 \\ 2 & 3 & 5 \\ \end{pmatrix} \in R^{2 \times 3} W=(021315)∈R2×3
b = ( 8 13 ) ∈ R 2 b = \begin{pmatrix} 8 \\ 13 \\ \end{pmatrix} \in R^2 b=(813)∈R2
则可知网络 f ( x ) = R e L U ( W ⋅ x + b ) f(x) = ReLU(W\cdot x + b) f(x)=ReLU(W⋅x+b),其中 x ∈ R 3 x \in R^3 x∈R3。
此时我们将维度为3的输入展开为 [ 1 , 1 , 3 ] [1, 1, 3] [1,1,3],同样地将维度为2的输出展开为 [ 1 , 1 , 2 ] [1, 1, 2] [1,1,2],从卷积的角度可以看成是输入是空间维度为 1 ∗ 1 1*1 1∗1的3个通道的特征图,输出是空间维度为 1 ∗ 1 1*1 1∗1的2个通道的特征图。
对于空间维度 1 ∗ 1 1*1 1∗1的3通道输入,我们需要用 [ 1 , 1 , 3 ] [1, 1, 3] [1,1,3]的kernel,计算得到 1 ∗ 1 1*1 1∗1的输出特征图,那么使用两个这样的kernel便得到了两个输出通道,即 [ 1 , 1 , 2 ] [1, 1, 2] [1,1,2]。
假设每一个kernel的卷积核参数如下所示:
K 1 = ( 0 1 1 ) K 2 = ( 2 3 5 ) K_1 = (0 \ \ 1 \ \ 1 )\\ K_2 = (2 \ \ 3 \ \ 5) K1=(0 1 1)K2=(2 3 5)
可以在 1 ∗ 1 1*1 1∗1卷积操作的基础上添加ReLU函数,那么有如下公式:
f ( x ) = R e L U ( ( K 1 ⋅ x K 2 ⋅ x ) + ( b 1 b 2 ) ) f(x) = ReLU\left(\begin{pmatrix} K_1\cdot x \\ K_2\cdot x \\ \end{pmatrix} + \begin{pmatrix} b_1 \\ b_ 2 \end{pmatrix}\right) f(x)=ReLU((K1⋅xK2⋅x)+(b1b2)),其中 x ∈ R 3 x \in R^3 x∈R3。
此时 1 ∗ 1 1*1 1∗1卷积操作的公式便与全连接层一致,这就是为什么 1 ∗ 1 1*1 1∗1卷积操作可以等价于一个全连接层。
最后回到Transformer上去,如何用两个 1 ∗ 1 1*1 1∗1卷积代替MLP呢?假设 d m o d e l = 512 d_{model}=512 dmodel=512,序列长度为 n n n,那么可以将每个token看作 [ 1 , 1 , 512 ] [1, 1, 512] [1,1,512],并将其竖起来,使用shape为 [ 1 , 1 , 512 ] [1, 1, 512] [1,1,512]的kernel进行卷积,并使用 2048 2048 2048个这样的kernel,便可得到 [ n , 2048 ] [n, 2048] [n,2048]维度的张量,维度扩大四倍,等价于第一层全连接。
同理再用 512 512 512个shape为 [ 1 , 1 , 2048 ] [1, 1, 2048] [1,1,2048]的kernel便可得到 [ n , 512 ] [n, 512] [n,512]的输出,回到原维度,等价于第二层全连接。
参考
解决疑惑的主要参考
How are 1x1 convolutions the same as a fully connected layer?
辅助参考

















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









