







DDDDOCR图片验证码识别技术
在我们日常浏览网页的时候,常常会弹出一张图片让你来验证,有的是滑动验证,有的是输入相应字符来进行验证,今天我就来给大家介绍这么一个技术,可以专门用来识别图片验证码的功能。
包下载
提到包下载,我们就会想到通过命令行pip install ddddocr或者通过pycharm框架中的添加包来实现。
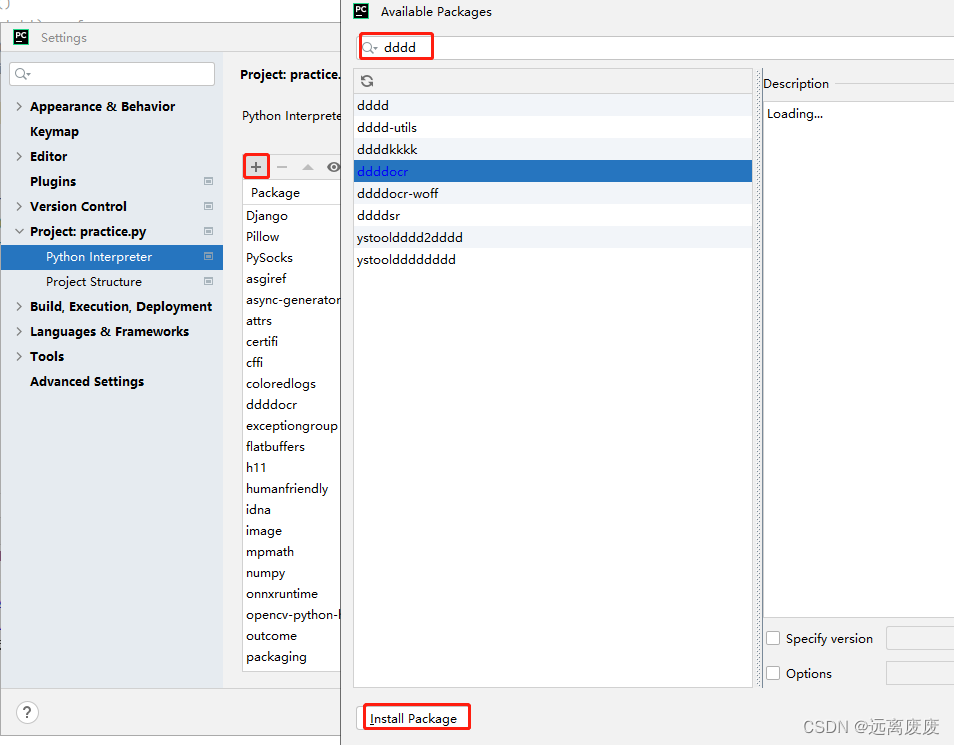
但是在下载这个包的过程中总是在提醒存在以下错误:
C:\Users\Test>pip install ddddocr
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting ddddocr
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/43/f7/febabbc3580e811accf89ca5236c7de0062b07adf535edc66587ff9149cb/ddddocr-1.0.6-py3-none-any.whl (6.9 MB)
Collecting numpy
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/73/39/f104eb30cc3da44d1e10622418c5e6eb5ac224f0f20c97dba44cf2de2af9/numpy-1.24.1-cp311-cp311-win_amd64.whl (14.8 MB)
ERROR: Ignored the following versions that require a different python version: 1.0.8 Requires-Python <3.8; 1.1.0 Requires-Python <3.9; 1.2.0 Requires-Python <3.10; 1.21.2 Requires-Python >=3.7,<3.11; 1.21.3 Requires-Python >=3.7,<3.11; 1.21.4 Requires-Python >=3.7,<3.11; 1.21.5 Requires-Python >=3.7,<3.11; 1.21.6 Requires-Python >=3.7,<3.11; 1.3.0 Requires-Python <3.10; 1.3.1 Requires-Python <3.10; 1.4.0 Requires-Python <3.10; 1.4.1 Requires-Python <3.10; 1.4.2 Requires-Python <3.10; 1.4.3 Requires-Python <3.10; 1.4.4 Requires-Python <=3.10; 1.4.5 Requires-Python <3.11; 1.4.6 Requires-Python <3.11; 1.4.7 Requires-Python <3.11
ERROR: Could not find a version that satisfies the requirement onnxruntime (from ddddocr) (from versions: none)
ERROR: No matching distribution found for onnxruntime
也是查了很多办法,指定国内镜像源,考虑版本更迭导致包名的改变等,都没啥效果,困扰了我几个小时后,沉下心来,再次打开-开发包的源地址https://github.com/sml2h3/ddddocr,此时再查看解释说明时,发现这个包目前只支持到python 3.10版本,而我目前的版本是最新的python 3.11.0。所以无法进行包的导入。

定位到了问题,那么就好解决了,这其中还遇到一个坑(也不算吧,有可能是自己没搞明白,后续在找补吧),其实按理说只需要将python版本回退到3.10就好了,但是不愿意卸载重装的我直接下了一个anaconda python管理包的一个工具,在这上面浪费了很多时间,今天暂时不做介绍了。
解决办法
1、卸载原来的Python版本,并且删除所存放Python的文件夹,我这里是D:\python,然后去官网随便找一个3.10版本下载即可,本人下载3.10.9https://www.python.org/downloads/release/python-3109/;
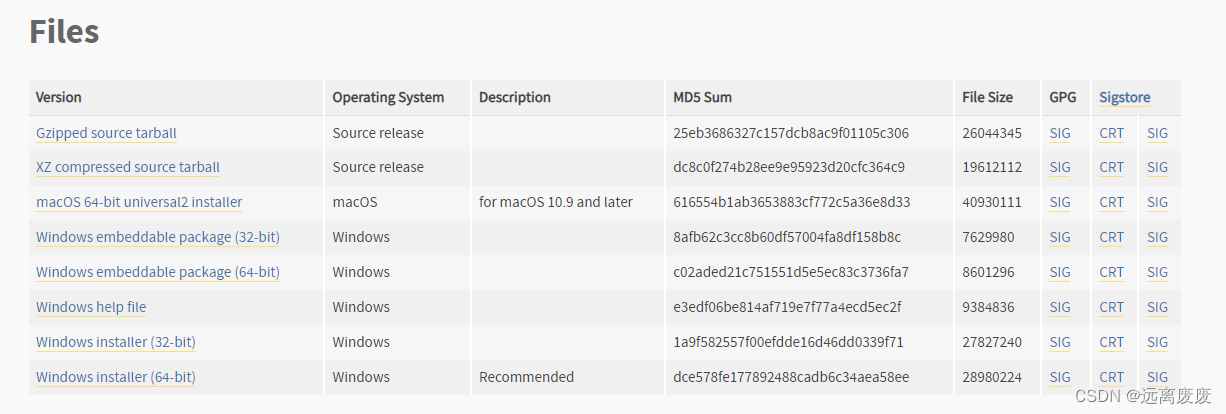
2、安装下载的python包;
C:\Users\Test>python
Python 3.10.9 (tags/v3.10.9:1dd9be6, Dec 6 2022, 20:01:21) [MSC v.1934 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
3、这时再下载ddddocr包与onnxruntime包,pip install ddddocr,pip install onnxruntime,此时可以正常下载成功,如果不能用就在pycharm中在install一遍。
C:\Users\Test>pip install ddddocr
C:\Users\Test>pip install onnxruntime
4、重新创建一个project,解释器设成刚才下载的路径即可,创建py文件,开始编译。

包的使用
这里我是用下面这张图片:

然后创建一个.py文件,并且将上面图片放在和此.py文件同一目录下。
import ddddocr
# 实例化
ocr = ddddocr.DdddOcr()
# 以二进制格式打开verf.png图片用于只读
with open('verf.png', 'rb') as f:
# 用来读取文件
img_bytes = f.read()
# 识别图片中的内容
res = ocr.classification(img_bytes)
# 输出内容
print('识别出的验证码为:' + res)
执行结果如下:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\venv\11.py
欢迎使用ddddocr,本项目专注带动行业内卷,个人博客:wenanzhe.com
训练数据支持来源于:http://146.56.204.113:19199/preview
爬虫框架feapder可快速一键接入,快速开启爬虫之旅:https://github.com/Boris-code/feapder
谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口:https://yescaptcha.com/i/NSwk7i
识别出的验证码为:jyfq
Process finished with exit code 0
这里作者将一些资料也打印出来了,如果不愿意用,可以通过CTEL+单击import ddddocr中的ddddocr,跳转至页面然后将不想看的文字注释掉:
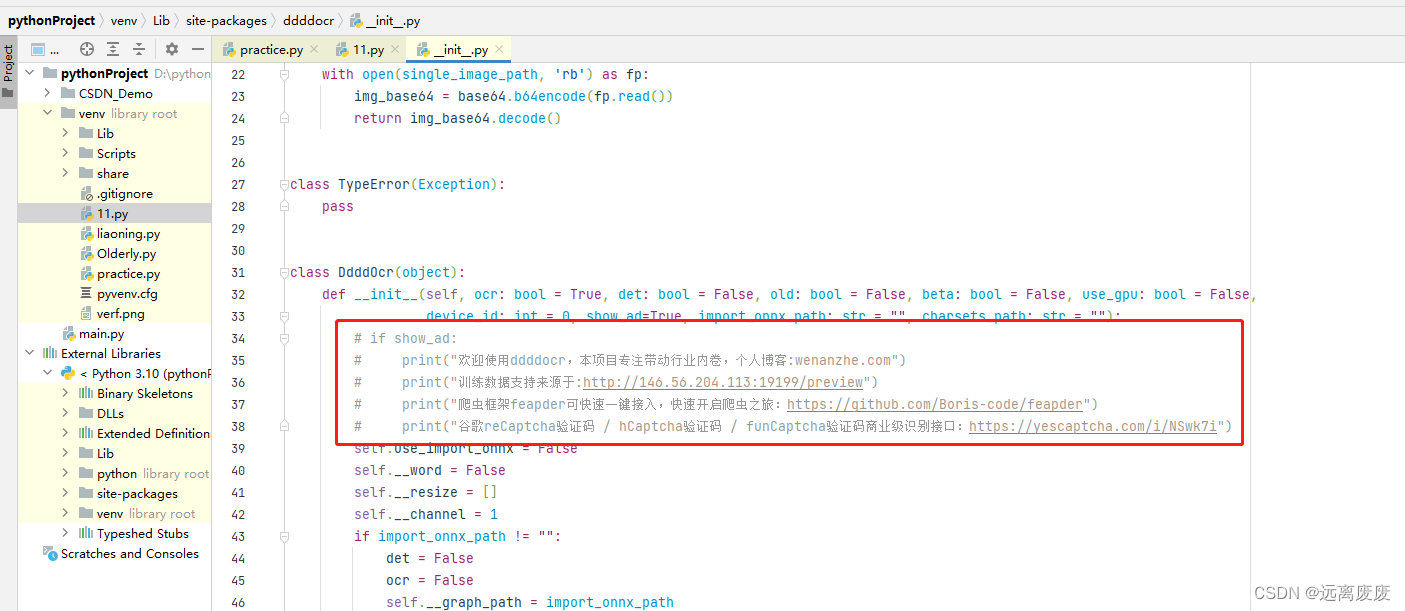
然后再返回执行,结果如下:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\venv\11.py
识别出的验证码为:jyfq
Process finished with exit code 0
总结
在遇到问题,还是要从源头查找根因,因为太过着急,没有仔细查看作者对ddddocr包的说明,因此走了很多的弯路,综上,安装ddddocr包最重要的是要关注他的版本问题,本地如果可以进行安装,那么编写,编译将会顺风顺水。















 6424
6424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









