







 文章介绍了如何使用Python通过分析网址和模拟用户登录来下载VIP音乐。首先,解析搜索音乐的网址和音乐源码地址,然后伪造用户登录界面,通过请求头绕过反爬机制。接着,提取关键字段mid,利用这个信息构造音乐源码的地址。最后,下载音乐文件,处理文件名中的特殊字符,确保能成功保存。这种方法成功避开了会员限制,实现了VIP音乐的下载。
文章介绍了如何使用Python通过分析网址和模拟用户登录来下载VIP音乐。首先,解析搜索音乐的网址和音乐源码地址,然后伪造用户登录界面,通过请求头绕过反爬机制。接着,提取关键字段mid,利用这个信息构造音乐源码的地址。最后,下载音乐文件,处理文件名中的特殊字符,确保能成功保存。这种方法成功避开了会员限制,实现了VIP音乐的下载。
VIP音乐下载,播放
在我们听歌的时候,总是被各种会员的限制,导致无法听到完整的音乐。当然有的人单单喜欢通过软件去听歌,这里面有很多优质评论可以看。但是当我们想下载一首歌的时候,不是会员就没有办法实现了。在这里给大家介绍一下如何通过python来实现软件vip音乐的下载。。
一、分析网址
(1)搜索音乐网址分析
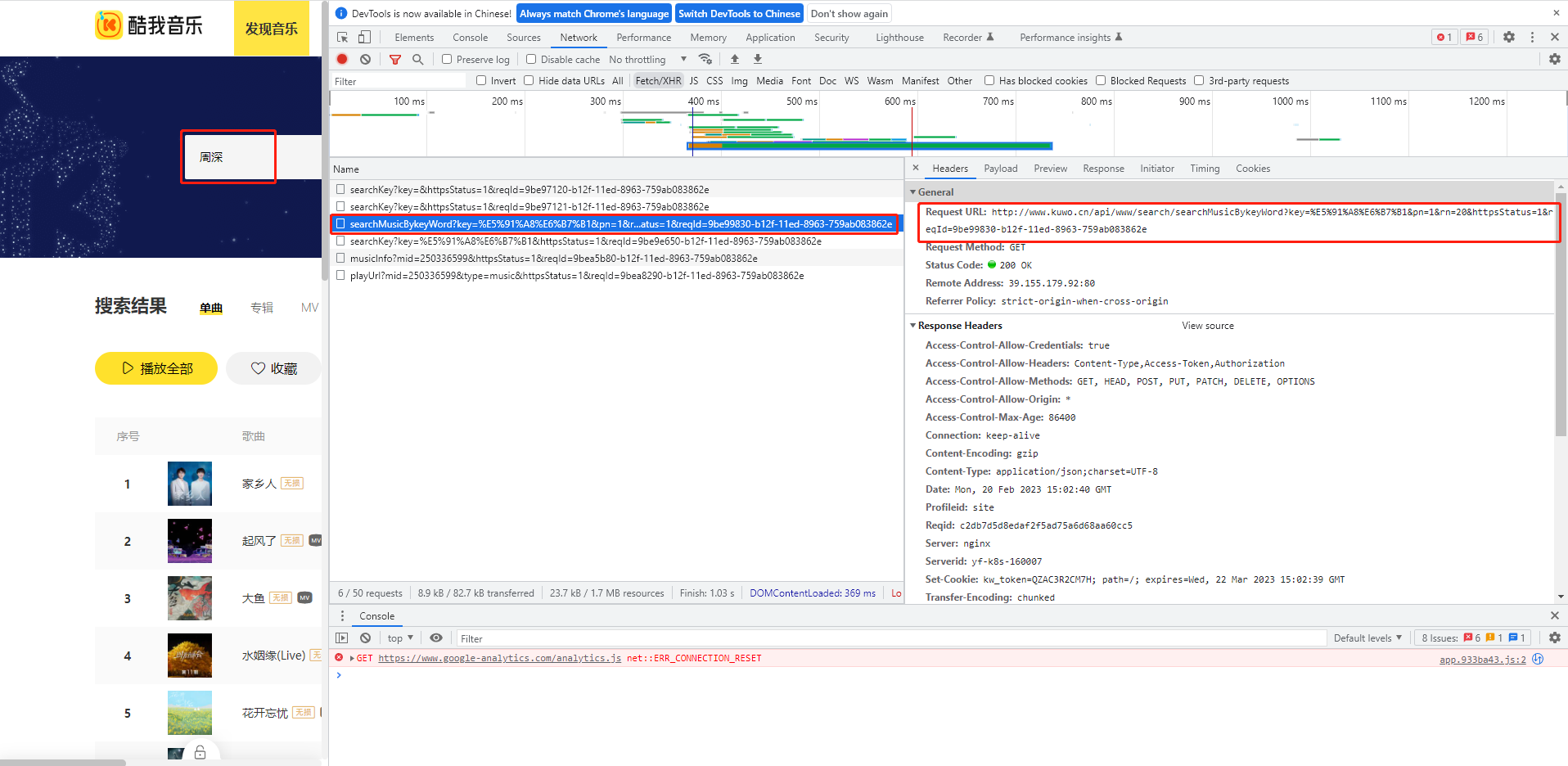
如下,我们以检索“周深”为例:通过Fetch/XHR找到网址为http://www.xxxx.cn/api/www/search/searchMusicBykeyWord?key=%E5%91%A8%E6%B7%B1&pn=1&rn=20&httpsStatus=1&reqId=8d9c7880-b12d-11ed-ae17-a1e6fcda1289,这里key后面写的就是搜索的名称,pn代表页数,rn代表每页显示的音乐条数。后面的可以不考虑,最后分析搜索的网址为http://www.xxxx.cn/api/www/search/searchMusicBykeyWord?key={}&pn={}&rn=20
(2)音乐的源址
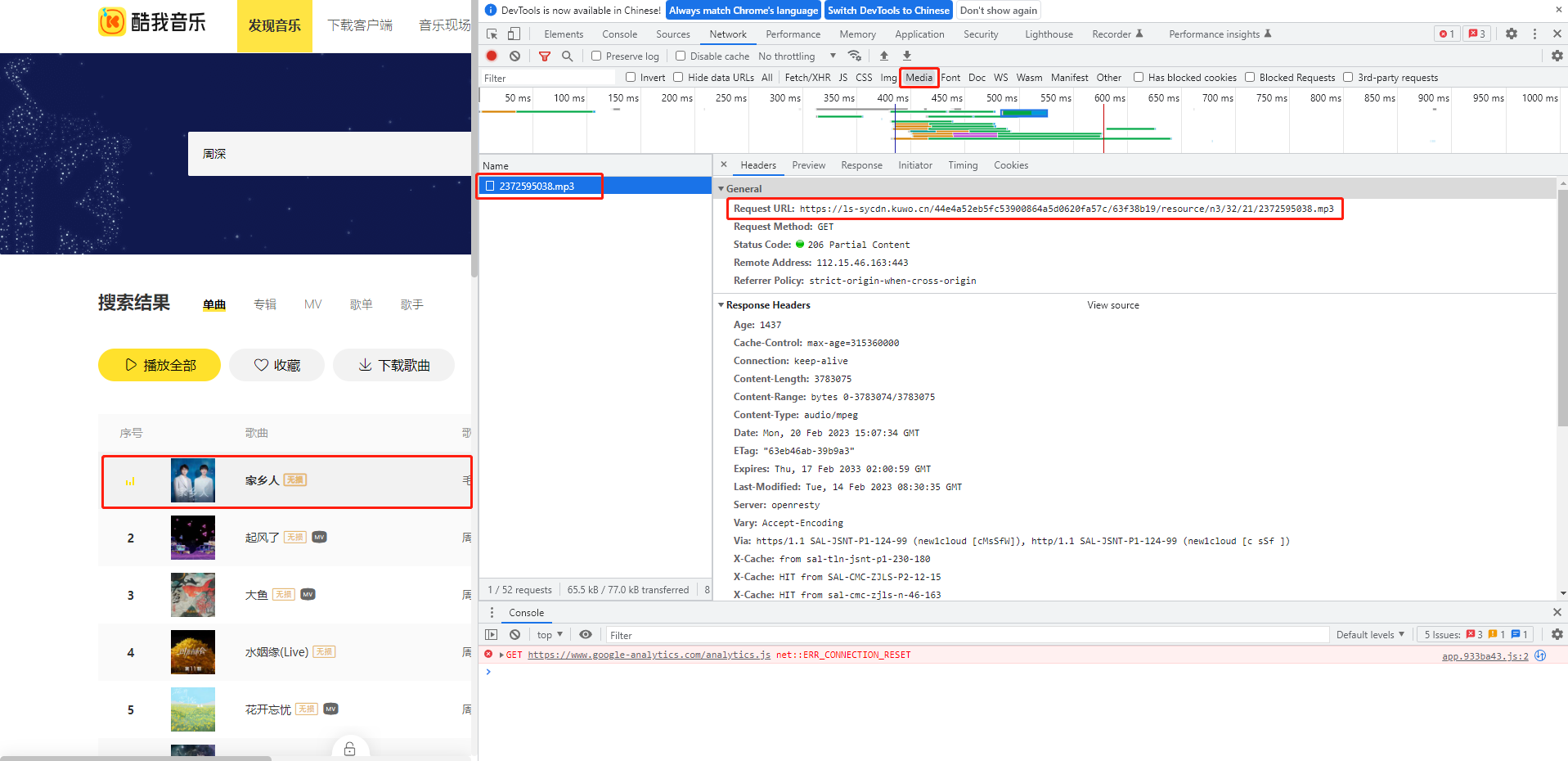
点击播放一首歌曲,然后点击network->media,可以查看播放歌曲的源码,如下:
源码地址为:https://ls-sycdn.xxxx.cn/44e4a52eb5fc53900864a5d0620fa57c/63f38b19/resource/n3/32/21/2372595038.mp3。
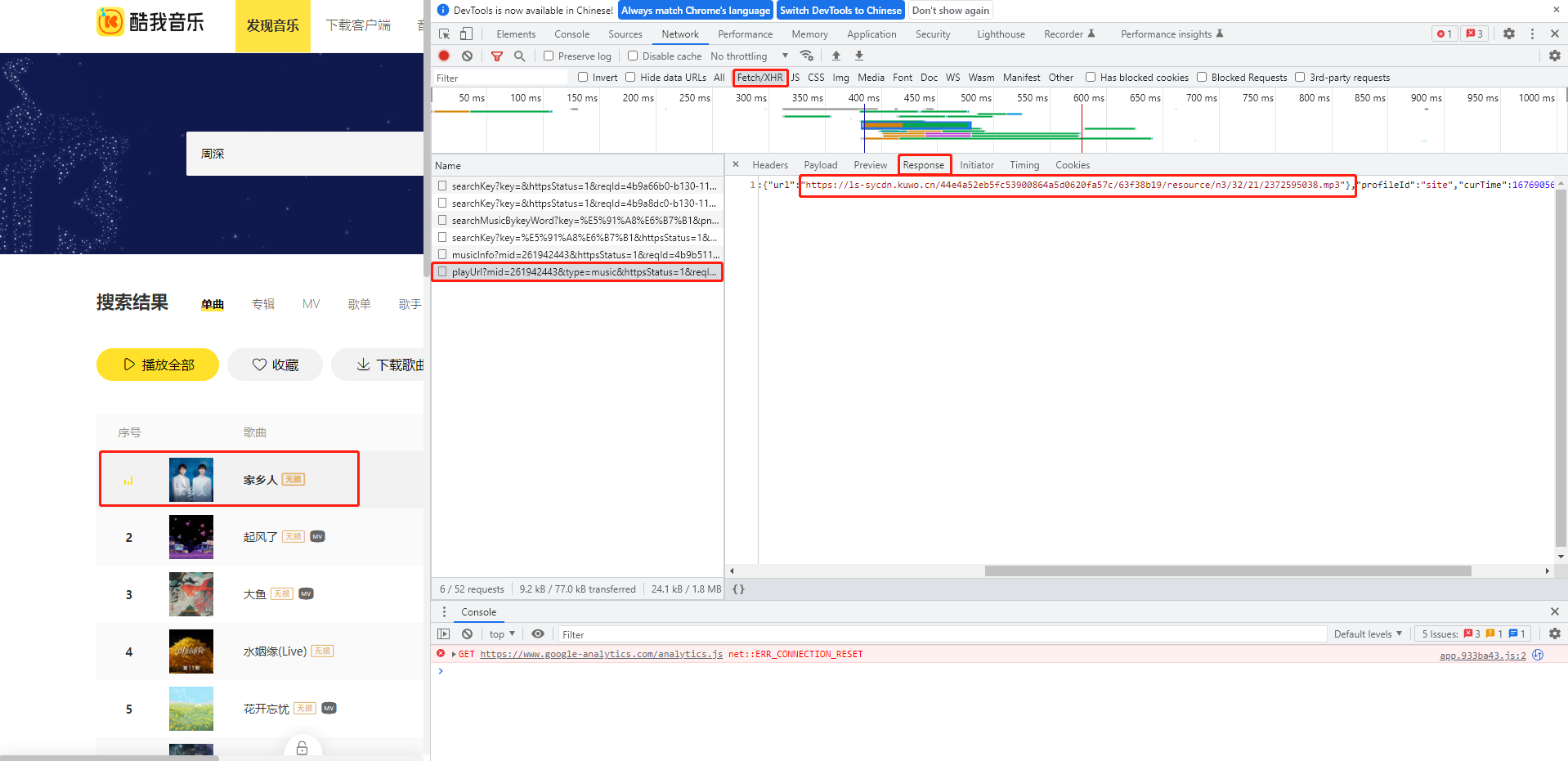
记住这个源码的格式,Ctrl+F去寻找这个源码,发现在PlayUrl这个地址中包含了这个源码从而确定信息交互时采用的地址。
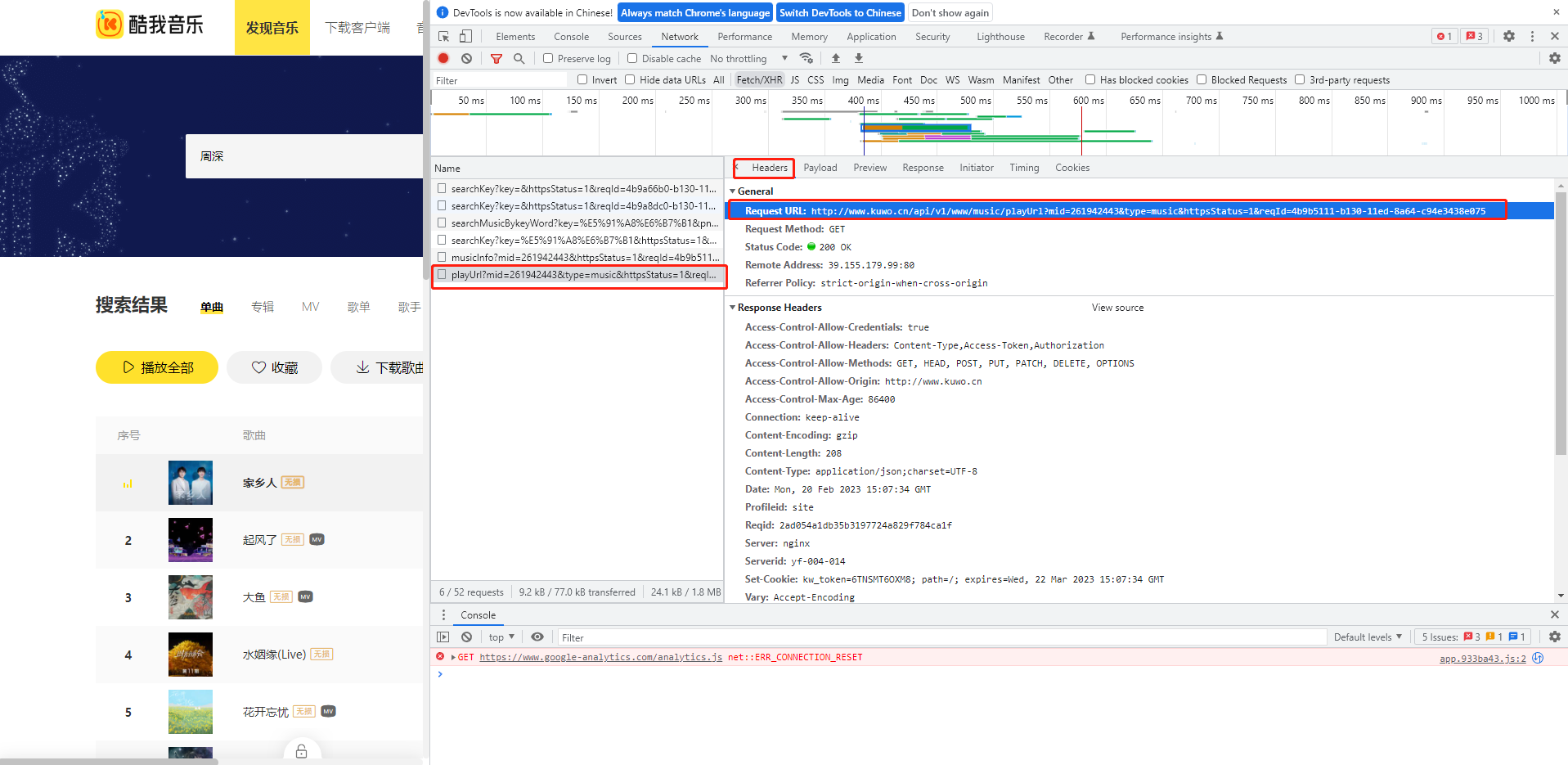
这个地址为:http://www.xxxx.cn/api/v1/www/music/playUrl?mid=261942443&type=music&httpsStatus=1&reqId=4b9b5111-b130-11ed-8a64-c94e3438e075。通过分析这个地址,我们可以得出这个网址中的关键字段mid,如果获取到它,他们所有音乐的源码地址我们都将可以获取到,从而实现VIP音乐的下载。
二、代码分析
(1)伪造用户登录界面
很多网站都是带有反爬机制,当你使用自动化一直访问一个网址,那么他就会检测出来,并做出相应处理,因此我们通过带用户表示去访问一个网址。
首先分析头headers,通过上述我们搜索界面进行分析。
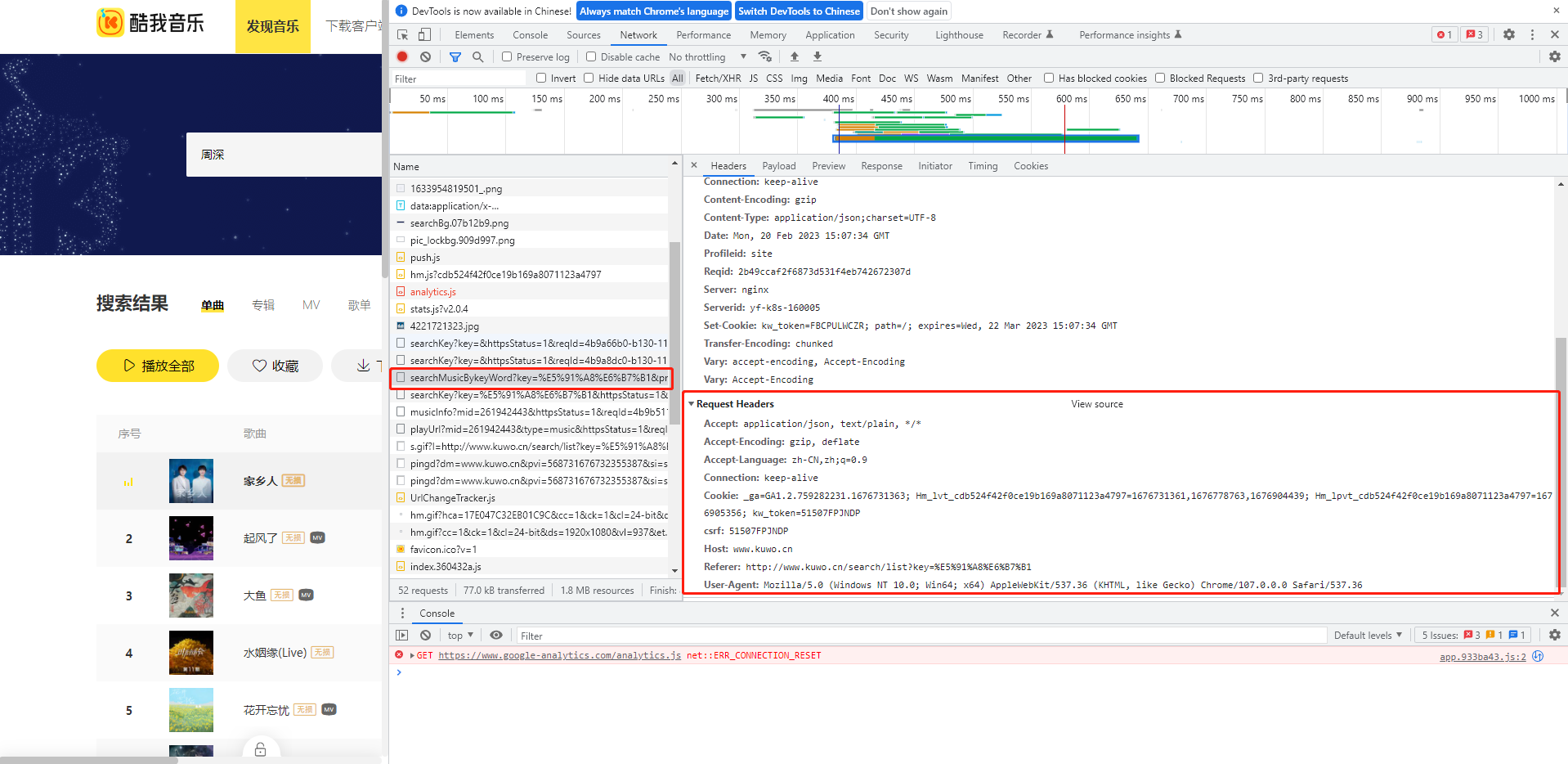
因此在这里构建一个请求头:
User-Agent:表示浏览器的版本信息。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6479
6479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











