






训练环境搭建
昇腾官方社区上已有详细教程,手把手教你在昇腾平台上搭建PyTorch训练环境,请移步:手把手教你在昇腾平台上搭建PyTorch训练环境-技术干货-昇腾社区在昇腾平台上运行PyTorch业务时,需要搭建异构计算架构CANN软件开发环境,并安装PyTorch 框架,从而实现训练脚本的迁移、开发和调试。本文就带你了解如何搭建PyTorch训练环境。![]() https://www.hiascend.com/developer/techArticles/20230526-1
https://www.hiascend.com/developer/techArticles/20230526-1
模型训练代码迁移
Pytorch是业界流行的深度学习框架,用于开发深度学习训练脚本,默认运行在CPU/GPU上。为了使这些脚本能够利用昇腾NPU的强大算力执行训练,需要对PyTorch的训练脚本进行迁移。
目前支持自动迁移、工具迁移和手动迁移三种迁移方式,推荐使用自动迁移,用户仅需在脚本中添加一行导入训练转换库的代码即可完成PyTorch训练脚本到NPU的迁移。
在训练脚本中导入脚本转换库,然后拉起脚本执行训练。训练脚本在运行的同时,会自动将脚本中的CUDA接口替换为昇腾AI处理器支持的NPU接口,整体过程为边训练边转换。具体代码实现方式如下:
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu在昇腾NPU上执行模型训练
以MLP模型为例,在昇腾NPU上进行AI模型训练的具体代码实现如下:
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
torch.cuda.set_device(0)
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
features = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0],[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]], dtype=torch.float)
labels = torch.tensor([0, 1, 0, 0, 1,0], dtype=torch.long)
custom_dataset = data.TensorDataset(features, labels)
dataloader = data.DataLoader(custom_dataset, batch_size=2, shuffle=True)
input_size = 3
hidden_size = 5
output_size = 2
model = MLP(input_size, hidden_size, output_size)
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
num_epochs = 50
experimental_config = torch_npu.profiler._ExperimentalConfig(
aic_metrics=torch_npu.profiler.AiCMetrics.PipeUtilization,
profiler_level=torch_npu.profiler.ProfilerLevel.Level1,
l2_cache=False,
data_simplification=False
)
with torch_npu.profiler.profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU,
torch_npu.profiler.ProfilerActivity.NPU
],
record_shapes=True,
profile_memory=True,
with_stack=True,
experimental_config=experimental_config,
schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=2, repeat=1,
skip_first=14),
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(
f"/home/lc/code/profiling_data")) as prof:
for epoch in range(num_epochs):
for inputs, targets in dataloader:
outputs = model(inputs.cuda())
loss = criterion(outputs, targets.cuda())
optimizer.zero_grad()
loss.backward()
optimizer.step()
prof.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
test_input = torch.tensor([[2.0, 3.0, 4.0]], dtype=torch.float)
with torch.no_grad():
output = model(test_input.cuda())
_, predicted = torch.max(output, 1)
print('Predicted class:', predicted.item())
出现如下界面,就说明代码运行成功:
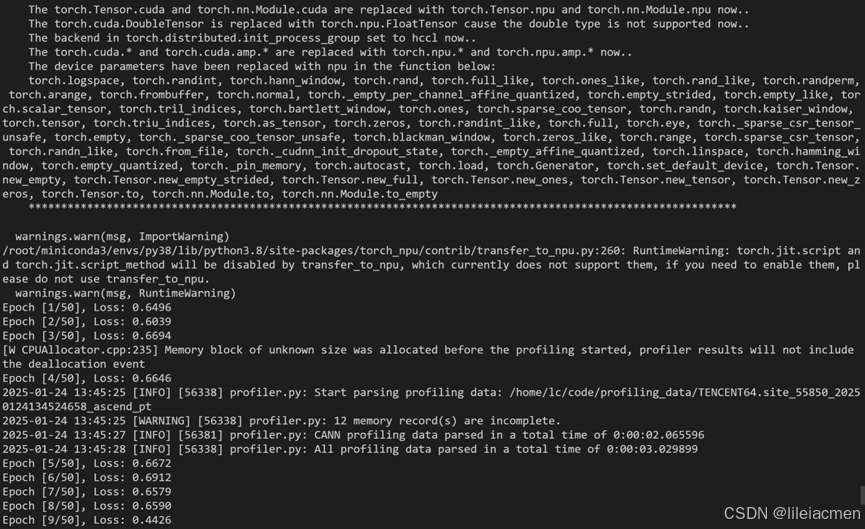
性能调优指南
进行性能调优时,可以使用性能调优工具来采集和分析运行在昇腾NPU上的AI任务各个运行阶段的关键性能指标,用户可根据输出的性能数据,快速定位软、硬件性能瓶颈,提升AI任务性能分析的效率。
Ascend PyTorch Profiler是针对PyTorch框架开发的性能分析工具,通过在PyTorch训练/在线推理脚本中添加Ascend PyTorch Profiler接口,执行训练/在线推理的同时采集性能数据,完成训练/在线推理后直接输出可视化的性能数据文件,提升了性能分析效率。Ascend PyTorch Profiler接口可全面采集PyTorch训练/在线推理场景下的性能数据,主要包括PyTorch层算子信息、CANN层算子信息、底层NPU算子信息、以及算子内存占用信息等,可以全方位分析PyTorch训练/在线推理时的性能状态。
1. 性能数据采集(torch_npu.profiler.profile)
在训练脚本/在线推理脚本内添加如下示例代码进行性能数据采集参数配置,之后启动训练/在线推理。如下示例代码:
import torch
import torch_npu
...
experimental_config = torch_npu.profiler._ExperimentalConfig(
export_type=torch_npu.profiler.ExportType.Text,
profiler_level=torch_npu.profiler.ProfilerLevel.Level0,
msprof_tx=False,
aic_metrics=torch_npu.profiler.AiCMetrics.AiCoreNone,
l2_cache=False,
op_attr=False,
data_simplification=False,
record_op_args=False,
gc_detect_threshold=None
)
with torch_npu.profiler.profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU,
torch_npu.profiler.ProfilerActivity.NPU
],
schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1, skip_first=1),
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./result"),
record_shapes=False,
profile_memory=False,
with_stack=False,
with_modules=False,
with_flops=False,
experimental_config=experimental_config) as prof:
for step in range(steps):
train_one_step(step, steps, train_loader, model, optimizer, criterion)
prof.step()
experimental_config参数说明:
| 参数 | 说明 |
|---|---|
| export_type | 设置导出的性能数据结果文件格式,Enum类型。可取值:
设置无效值或未配置均取默认值torch_npu.profiler.ExportType.Text。 |
| profiler_level | 采集的Level等级,Enum类型。可取值如下:
|
| msprof_tx | 打点控制开关,通过开关开启自定义打点功能,bool类型。可取值True(开启)或False(关闭),默认关闭。 |
| data_simplification | 数据精简模式,开启后将在导出性能数据后删除FRAMEWORK目录数据以及删除多余数据,仅保留profiler_info.json文件、ASCEND_PROFILER_OUTPUT目录和PROF_XXX目录下的原始性能数据,以节省存储空间,bool类型。可取值True(开启)或False(关闭),默认开启。 |
| aic_metrics | AI Core的性能指标采集项。可取值如下: 以下采集项的结果数据将在Kernel View呈现。 以下采集项的结果数据含义可参见op_summary(算子详细信息),但具体采集结果请以实际情况为准。
|
| l2_cache | 控制L2 Cache数据采集开关,bool类型。可取值True(开启)或False(关闭),默认关闭。该采集项在ASCEND_PROFILER_OUTPUT生成l2_cache.csv文件,结果字段介绍请参见l2_cache(L2 Cache命中率)。 |
| op_attr | 控制采集算子的属性信息开关,当前仅支持采集aclnn算子,bool类型。可取值True(开启)或False(关闭),默认关闭。该参数采集的性能数据仅支持export_type=torch_npu.profiler.ExportType.Db时解析的db格式文件。torch_npu.profiler.ProfilerLevel.None时,该参数不生效。 |
| record_op_args | 控制算子信息统计功能开关,bool类型。可取值True(开启)或False(关闭),默认关闭。开启后会在{worker_name}_{时间戳}_ascend_pt_op_args目录输出采集到算子信息文件。 说明 该参数在AOE工具执行PyTorch训练场景下调优时使用,且不建议与其他性能数据采集接口同时开启。详见《AOE工具指南》。 |
| gc_detect_threshold | GC检测阈值,float类型。取值范围为大于等于0的数值,单位ms。当用户设置的阈值为数字时,表示开启GC检测,只采集超过阈值的GC事件。 配置为0时表示采集所有的GC事件(可能造成采集数据量过大,请谨慎配置),推荐设置为1ms。 默认为None,表示不开启GC检测功能。 GC是Python进程对已经销毁的对象进行内存回收。 解析结果文件格式配置为torch_npu.profiler.ExportType.Text时,则在解析结果数据trace_view.json中生成GC层。 解析结果文件格式配置为torch_npu.profiler.ExportType.Db时,则在ascend_pytorch_profiler_{rank_id}.db中生成GC_RECORD表。可通过MindStudio Insight工具查看。 |
torch_npu.profiler.profile配置参数说明:
| 参数 | 说明 |
| activities | CPU、NPU事件采集列表,Enum类型。取值为:
默认情况下两个开关同时开启。 |
| schedule | 设置不同step的行为,Callable类型,由schedule类控制。默认不执行任何操作。 |
| on_trace_ready | 采集结束时自动执行操作,Callable类型。当前支持执行 tensorboard_trace_handler函数操作。默认不执行任何操作。 |
| record_shapes | 算子的InputShapes和InputTypes,Bool类型。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。 |
| profile_memory | 算子的内存占用情况,Bool类型。取值为:
|
| with_stack | 算子调用栈,Bool类型。包括框架层及CPU算子层的调用信息。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。 说明 开启该配置后会引入额外的性能膨胀。 |
| with_modules | modules层级的Python调用栈,即框架层的调用信息,Bool类型。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。 说明 开启该配置后会引入额外的性能膨胀。 |
| with_flops | 算子浮点操作,Bool类型(该参数暂不支持解析性能数据)。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。 |
| experimental_config | 扩展参数,通过扩展配置性能分析工具常用的采集项。 |
2. 性能数据解析
支持自动解析,参照以上示例代码中tensorboard_trace_handler
3. 性能数据分析
采集到的性能数据可以使用MindStudio Insight工具进行可视化展示和分析。MindStudio Insight是面向昇腾AI开发者的可视化调优工具,支持模型调优和算子调优的能力,使能开发者在训练、推理以及算子开发场景快速完成性能优化。
工具下载地址:社区版资源下载-资源下载中心-昇腾社区
step1:下载到本地后,双击exe文件进行安装,然后打开Insight工具会出现如下界面:
step2:点击Import Data导入采集到的性能数据
step3:可视化展示和分析
在昇腾异构计算架构中,MindStudio Insight工具以时间线(Timeline)的呈现方式将训练/推理过程中的host、device上的运行详细情况平铺在时间轴上,直观呈现host侧的API耗时情况以及device侧的task耗时,并将host与device进行关联呈现,帮助用户快速识别host瓶颈或device瓶颈,同时提供各种筛选分类、专家建议等功能,支撑用户进行深度调优。详细的使用方式请参考昇腾官方文档介绍:系统功能展示-使用说明-时间线(Timeline)-系统调优-MindStudio Insight用户指南-可视化工具-MindStudio7.0.RC3开发文档-昇腾社区
上文提到的MLP模型训练性能数据的MindStudio Insight时间线界面如下:
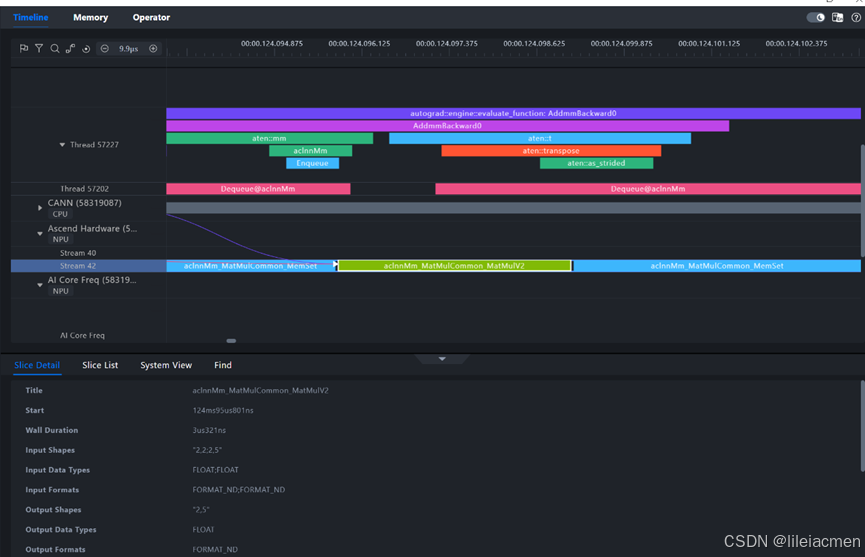
点击Operator可以看到各个算子的耗时分布情况,哪些算子消耗了大部分算力资源,一目了然:
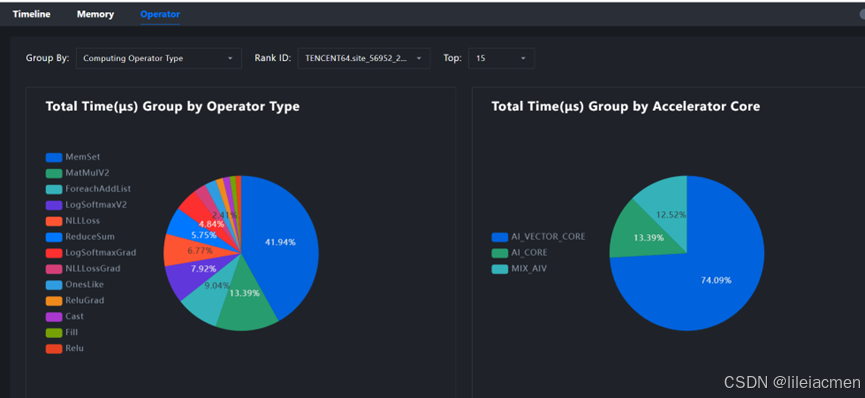
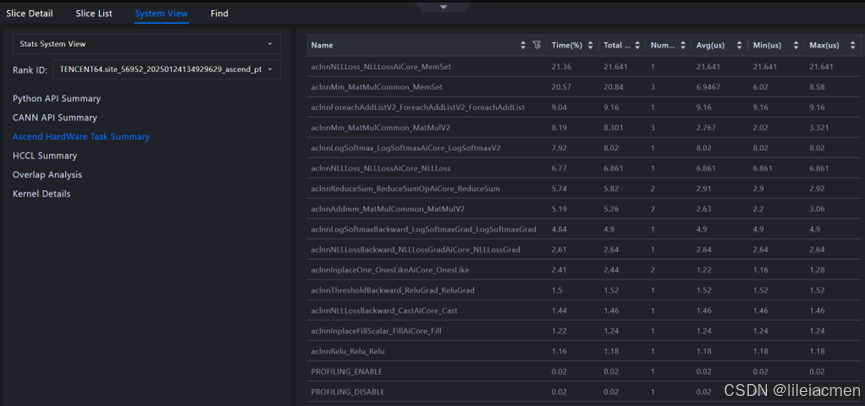
还可以点击System View查看各个算子的具体性能数据:

















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









