






介绍
MindStudio ModelSlim,昇腾模型压缩工具,一个以加速为目标、压缩为技术、昇腾为根本的亲和压缩工具。支持训练加速和推理加速,包括模型低秩分解、稀疏训练、训练后量化、量化感知训练等功能,昇腾AI模型开发用户可以灵活调用Python API接口,对模型进行性能调优,并支持导出不同格式模型,在昇腾AI处理器上运行。
基础环境
硬件要求:Atlas 800I A2/ Atlas 800T A2、Atlas 300I Duo 推理卡
基础配套镜像下载:https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f
ModelSlim工具安装参考:https://gitee.com/ascend/msit/blob/master/msmodelslim/README.md
主要步骤
开启二进制编译
可选,如果使用npu进行量化需开启二进制编译,避免在线编译算子
torch.npu.set_compile_mode(jit_compile=False)
option = {}
option["NPU_FUZZY_COMPILE_BLACKLIST"] = "ReduceProd"
torch.npu.set_option(option)
原始模型加载
max_memory:npu使用卡数及显存
model_path = '/data/Qwen2.5-72B-Instruct/'
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=model_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
max_memory={0:"0GiB",1:"0GiB",2:"0GiB",3:"0GiB",4:"25GiB",5:"25GiB",6:"25GiB",7:"25GiB"}
).eval()
获取校准数据
校准数据根据业务需求选取,建议选取比较普适的子数据集,输入数量建议为10-50条。
def get_calib_dataset(tokenizer, calib_list, device=model.device):
calib_dataset = []
for calib_data in calib_list:
inputs = tokenizer(calib_data, return_tensors='pt')
calib_dataset.append([
inputs.data['input_ids'].to(device),
inputs.data['attention_mask'].to(device)
])
return calib_dataset
#boolq数据集
entry = "/dataset/boolq_lite/dev3.jsonl"
with open(entry, 'r') as file:
calib_set = json.load(file)
dataset_calib = get_calib_dataset(tokenizer, calib_set)
离群值抑制AntiOutlier设置
通过抑制量化过程中的异常值,使能后续更好的量化
anti_method:
m1:SmoothQuant算法
m2:SmoothQuant升级版
m3:AWQ算法(适用于W8A16/W4A16)
m4:SmoothQuant优化算法
m5:CBQ算法 m6:Flex smooth量化算法
不同模型对不同离群抑制算法表现不一样
anti_config = AntiOutlierConfig(anti_method="m3", dev_type="npu", dev_id=model.device.index)
anti_outlier = AntiOutlier(model, calib_data=dataset_calib, cfg=anti_config)
anti_outlier.process()
调用QuantConfig接口,配置量化参数
w8a8
disatble_names:手动指定回退层
arc_method:激活值量化方法
act_method默认值为1,该参数可选1、2、3
1代表min-max量化方式;
2代表histogram量化方式;
3代表min-max和histogram混合的量化的方式。
LLM大模型场景下建议使用3。
fa_quant()该参数为fa3量化特性,不需要则去除
fa_quant(fa_amp=0)
quant_config = QuantConfig(
a_bit=8,
w_bit=8,
disable_names=disable_names,
dev_type='npu',
dev_id=model.device.index,
act_method=1,
pr=1.0,
w_sym=True,
mm_tensor=False)
执行并保存
disable_level:自动回退。自动回退会根据range_parm参数由大到小排序回退对精度影响比较大的Linear层。 设置disable_level=‘Lx’,x为自动回退的linear层数量,会在终端显示回退的层名称,diable_level='L0’即为不进行回退,x设置的数量超过模型层数就是全部回退,并且也不报错。
save_type:支持safe_tensor和numpy格式。
calibrator = Calibrator(model, quant_config, calib_data=dataset_calib, disable_level='L0')
calibrator.run()
calibrator.save('/data/qwen2.5-72-w8a8', save_type=["safe_tensor"])
qwen2.5-72B w8a8 fa3量化代码样例
import json
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelslim.pytorch.llm_ptq.anti_outlier import AntiOutlierConfig, AntiOutlier
from modelslim.pytorch.llm_ptq.llm_ptq_tools import Calibrator, QuantConfig
import jsonlines
SEQ_LEN_OUT = 100
batch_size = 1
#如果使用npu进行量化需开启二进制编译,避免在线编译算子
torch.npu.set_compile_mode(jit_compile=False)
option = {}
option["NPU_FUZZY_COMPILE_BLACKLIST"] = "ReduceProd"
torch.npu.set_option(option)
"""
原始模型加载
"""
model_path = '/data/Qwen2.5-72B-Instruct/'
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=model_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
max_memory={0:"0GiB",1:"0GiB",2:"25GiB",3:"25GiB",4:"25GiB",5:"25GiB",6:"25GiB",7:"25GiB"}
).eval()
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path=model_path,
trust_remote_code=True,
device_map="auto",
)
tokenizer.pad_token = tokenizer.eos_token
"""
获取校准数据
"""
def get_calib_dataset(tokenizer, calib_list, device=model.device):
calib_dataset = []
for calib_data in calib_list:
inputs = tokenizer(calib_data, return_tensors='pt')
calib_dataset.append([
inputs.data['input_ids'].to(device),
inputs.data['attention_mask'].to(device)
])
return calib_dataset
entry = "/dataset/boolq_lite/dev3.jsonl"
with open(entry, 'r') as file:
calib_set = json.load(file)
dataset_calib = get_calib_dataset(tokenizer, calib_set)
"""
回退层设置
"""
disable_names = []
num_layers = 80
disable_idx_lst = list(range(num_layers))
for layer_index in disable_idx_lst:
down_proj_name = "model.layers.{}.mlp.down_proj".format(layer_index)
disable_names.append(down_proj_name)
"""
AntiOutlier:本模型无需设置离群抑制值精度即可达标
"""
"""
配置量化参数
"""
quant_config = QuantConfig(
a_bit=8,
w_bit=8,
disable_names=disable_names,
dev_type='npu',
dev_id=model.device.index,
act_method=1,
pr=1.0,
w_sym=True,
mm_tensor=False
).fa_quant(fa_amp=0)
calibrator = Calibrator(model, quant_config, calib_data=dataset_calib, disable_level='L0') #disable_level设置为L0精度即可达标
calibrator.run()
calibrator.save('/data/qwen25-72-w8a8', save_type=["safe_tensor"])
FAQ
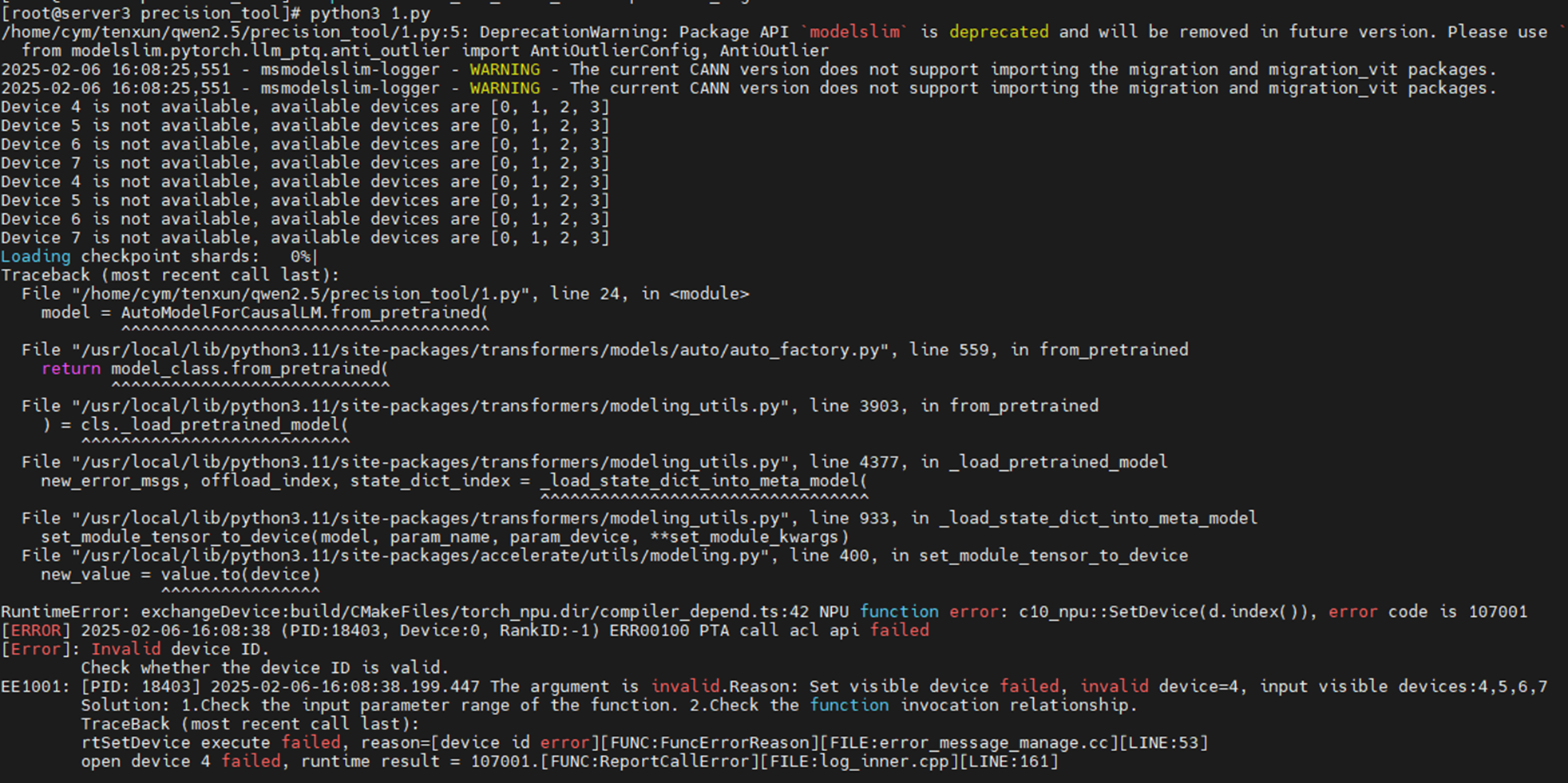
报错卡异常模型无法加载
max_memory={0:“0GiB”,1:“0GiB”,2:“25GiB”,3:“25GiB”,4:“25GiB”,5:“25GiB”,6:“25GiB”,7:“25GiB”}
800I A2,32G qwen2.5-72B量化最少使用六卡,使用四卡时报错如下图
qwen2.5量化精度支持情况
当前qwen2.5仅支持w8a8 fa3量化

















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









