







文章目录
DSP知识点记录
基本汇编的含义
#define EINT asm(" clrc INTM") //INTM置0,开全局中断
#define DINT asm(" setc INTM") //INTM置1,关全局中断
#define ERTM asm(" clrc DBGM") //使能调试事件
#define DRTM asm(" setc DBGM") //禁止调试事件
#define EALLOW __asm(" EALLOW") //关键寄存器写使能
#define EDIS __asm(" EDIS") //关键寄存器不可写
#define ESTOP0 __asm(" ESTOP0") //根据ESTOP位决定是否停止仿真
asm(" RPT #120 || NOP") //delay至少120个cycle
DBGM的含义
当DBGM置位时,仿真器无法在实时状态下访问内存或寄存器。调试器无法更新其窗口。在实时调试模式中,若DBGM = 1,则CPU忽略停止请求或硬件断点,直到DBGM清零。DBGM并不阻止CPU停止在软件断点。这点的一个影响可以在实时调试模式中看到。如果你在实时调试模式中单步执行一个指令,并且这条指令置位DBGM,CPU继续执行指令,直到DBGM被清零。
当你给TI调试器“实时”命令时(进入实时模式),DBGM强制为0。令DBGM = 0确保了允许调试和测试直接内存访问 (DT-DMAs);内存和寄存器的值可传递到主处理器,用于更新调试器窗口。
CPU在执行中断服务程序(ISR)之前将DBGM置位。当DBGM = 1时,来自主处理器和硬件断点的停止请求被忽略。如果你想要单步执行程序或在对时间要求不严格的ISR中设置断点,那么你必须在ISR的开始处增加一条CLRC DBGM指令。
DBGM主要用在时间要求严格的程序代码部分的仿真,来阻止调试事件。
当CPU响应中断时,DBGM的当前值存储到堆栈中(当ST1存储在堆栈中时),然后DBGM置位。当由中断返回时,DBGM由堆栈中恢复。
此位可分别由SETC DBGM指令和CLRC DBGM指令复位和清零。DBGM在中断操作期间被自动置位。复位时,DBGM置位。执行ABORTI (中止中断)指令也可以将DBGM置位。
ESTOP0
ESTOP0这个是2812的一个汇编指令,是用于仿真的,它有两个方面的知识:1、当用仿真器连接时如果ESTOP0置位(ESTOP0=1),那么整个DSP停止运行。2、当不用仿真程序时,在程序中写这条指令相当于NOP(空指令),只是占了CPU的一个周期而已。还有一种说法是,跑到这里就停止,需进一步论证
F28388默认的启动方式。
断电重启后会先运行固定在ROM的BOOT代码,会初始化时钟,会根据当前reset类型、配置的引脚、以及一个bootmode table选择跳转到指定的代码区域。读取配置的引脚的值,以该值为索引在boot mode table确定最终的boot方式。

程序会先跳转到f2838x_codestartbranch.asm中,code_start函数,其实就是一条跳转指令。如果WD_DISABLE置为1,就是会先执行wd_disable,最终都会跳转到_c_int00函数,这个是主程序运行前的准备函数,准备堆栈环境,及为变量分配空间等。才会跳转到main函数。
-
CPU1的bootmode table支持最多8种启动方式,刚好与3个PIN想对应。每种启动方式可以进一步配置。如flash可以配置从哪个sector启动。SCI可以配置通过哪几个引脚用来传输数据来远程配置。
-
CPU1启动CPU2和CM的流程
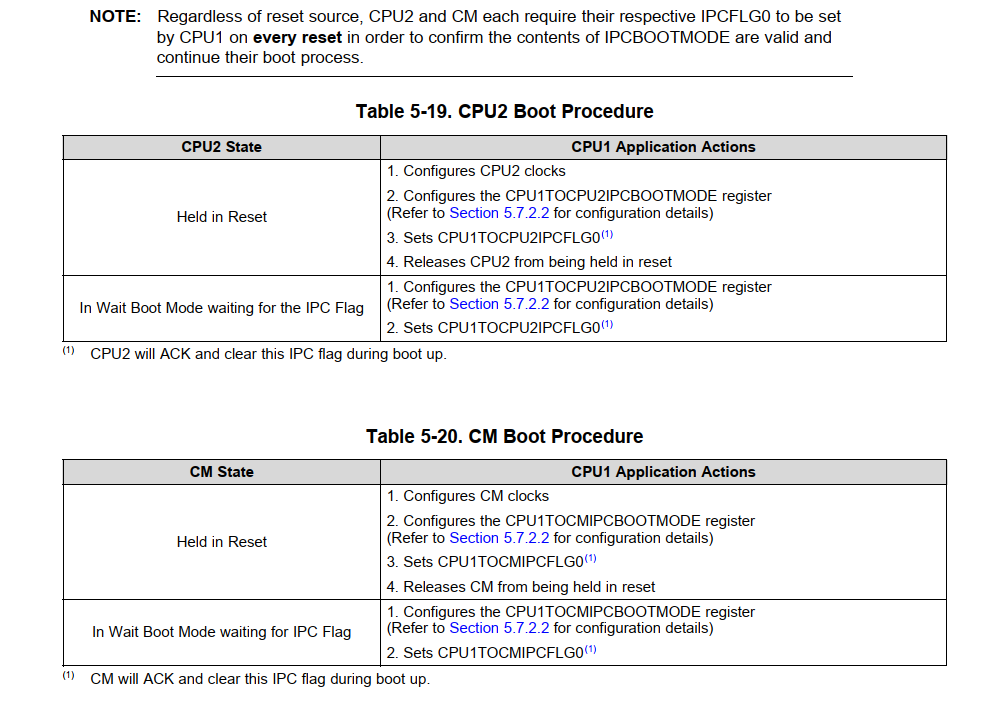
-
BOOTMODE寄存器
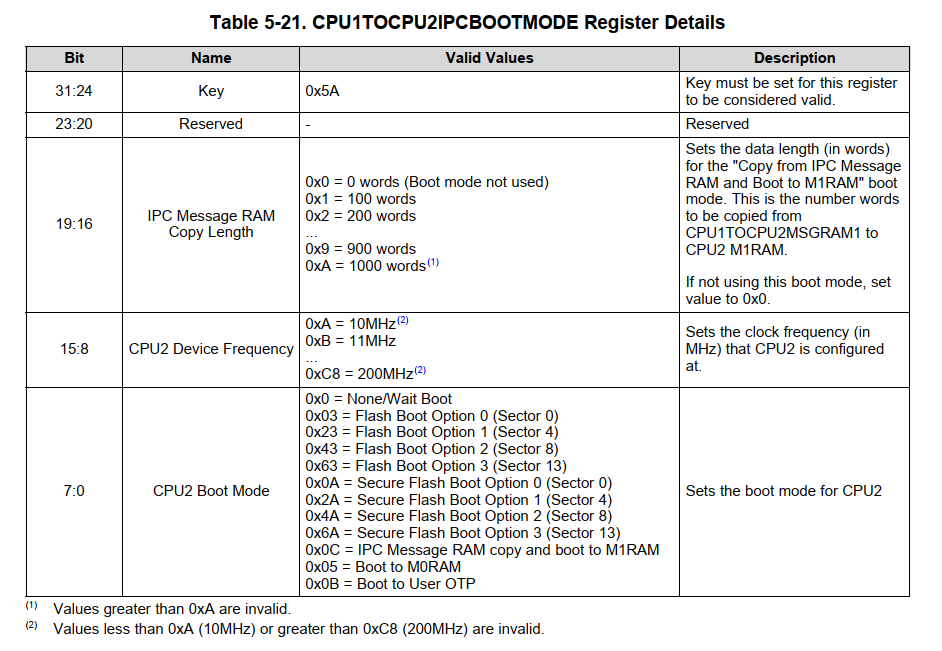

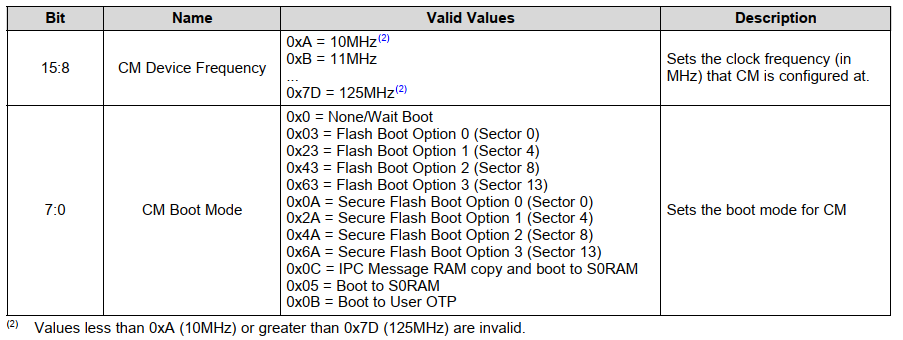
-
当CPU2或者CM发生错误,可以通过IPC Commands通知
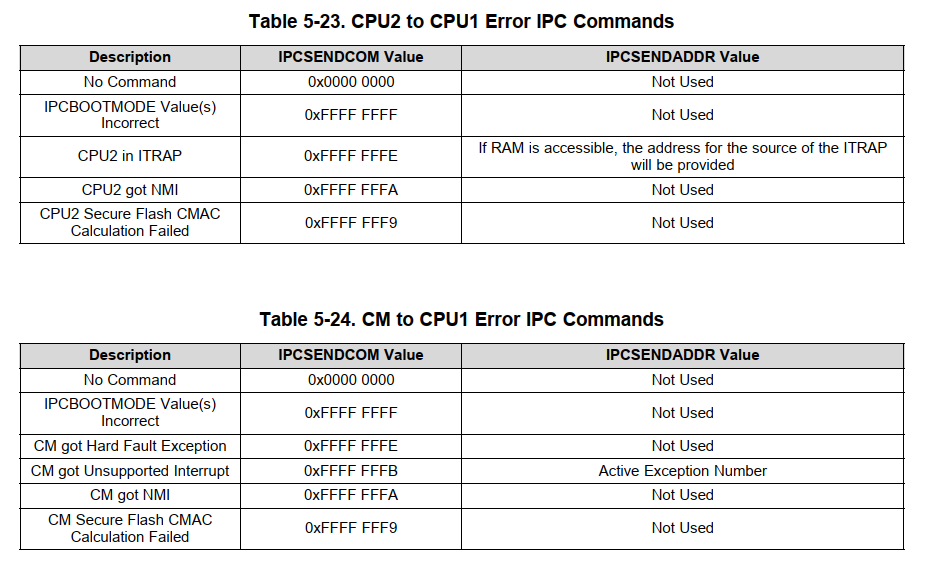
GPIO的配置
GPIO整体的框图如下图:
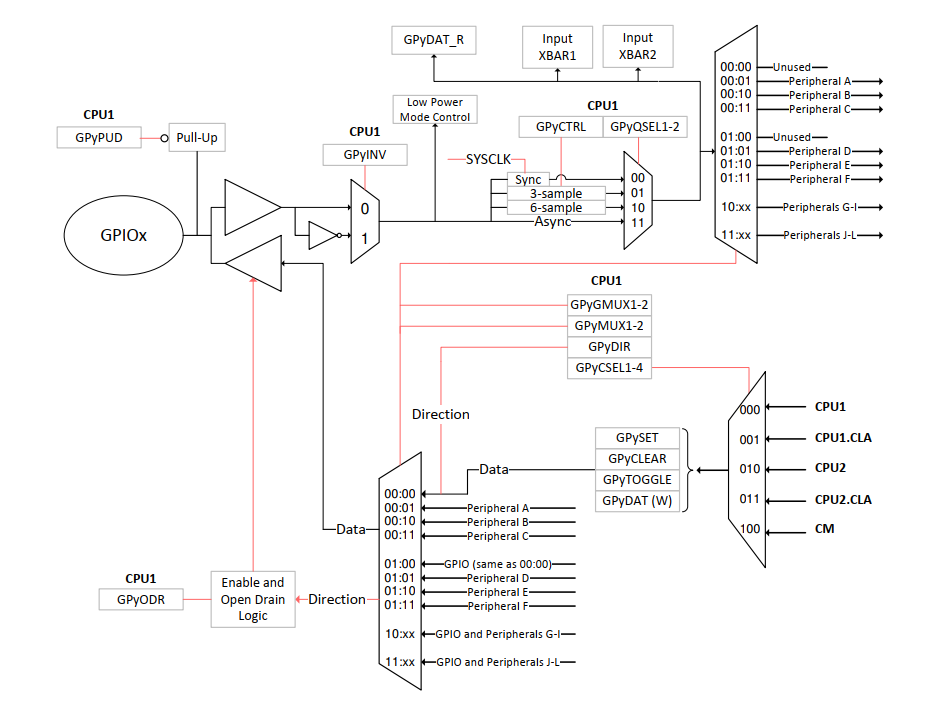
基本寄存器的含义:
//下面两个是设置GPIO干嘛用的,GPIO1是两位的数据,对应上面的选择
GpioCtrlRegs.GPAMUX1.bit.GPIO1 = 0;
GpioCtrlRegs.GPAGMUX1.bit.GPIO1 = 0;
GpioCtrlRegs.GPADIR.bit.GPIO0 = 0;//设置GPIOA的pin0为输入
GpioCtrlRegs.GPAQSEL1.bit.GPIO0 = 0;//设置IO信号的同步方式,采样周期。有4种方式
//跟SYSCLK同步
//3个采样周期保持不变,才改变信号,采样周期基于分频后的时钟
//6个采样周期不变
//异步,原始的IO信号
GpioCtrlRegs.GPACTRL.bit.QUALPRD0 = 0xFF;//采样周期为0xFF * 2个Systick,QUALPRD0设置的是pin0-pin7的采样周期,QUALPRD1等同理
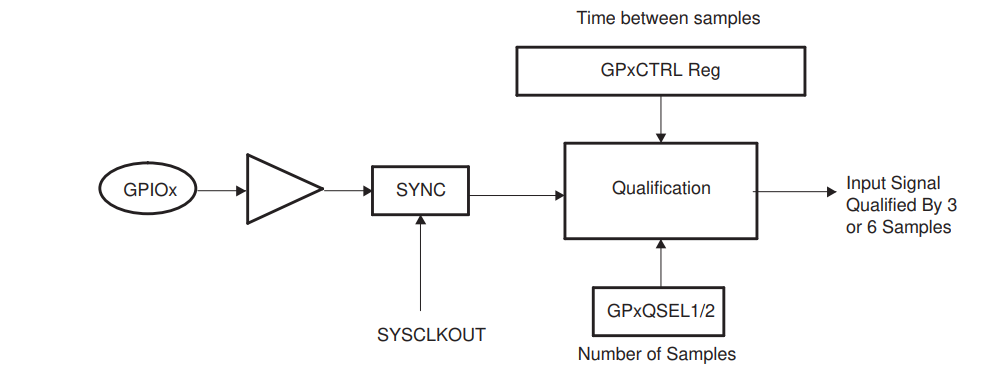
IO输入滤波逻辑见下图:先经过SYSCLK采样输出信号,然后对此信号经过GPACTRL设置的采样时间采样,采样3或者6次后进行滤波得到最终的信号。
如果需要产生IO中断,需要配置X-BAR,将IO端口连接到中断线
X-BAR外部IO中断配置
整体结构如下图:
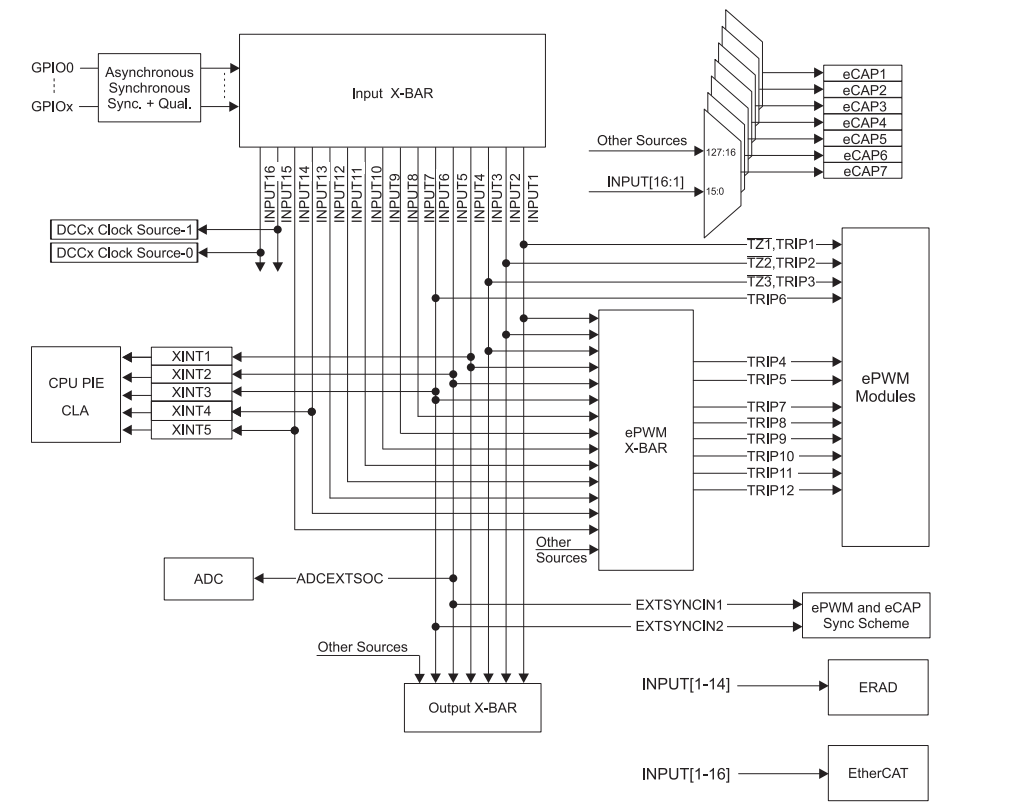
外部中断配置:
见上图可知,input-BAR的输入是所有的IO,输出只有16个,跟不同的外设绑定连接。XINT1是和INPUT4连接的。如果需要将某个IO与XINT1中断绑定起来,那么久写X-BAR的寄存器,INPUT4和指定GPIO绑定即可。由于inputbar只有一个,所以两个CPU共享这五根外部中断线。至此XINT1连接到PIE管理上,还需要配置PIE的寄存器,让其能连接到CPU上,最后配置CPU的中断寄存器。才配置完成。
PIE模块
CPU只有12根中断线对外开放,与PIE模块连接。PIE的输入可能是各种外设及IO,输出只有12个通道。具体可以映射的规则如下图:
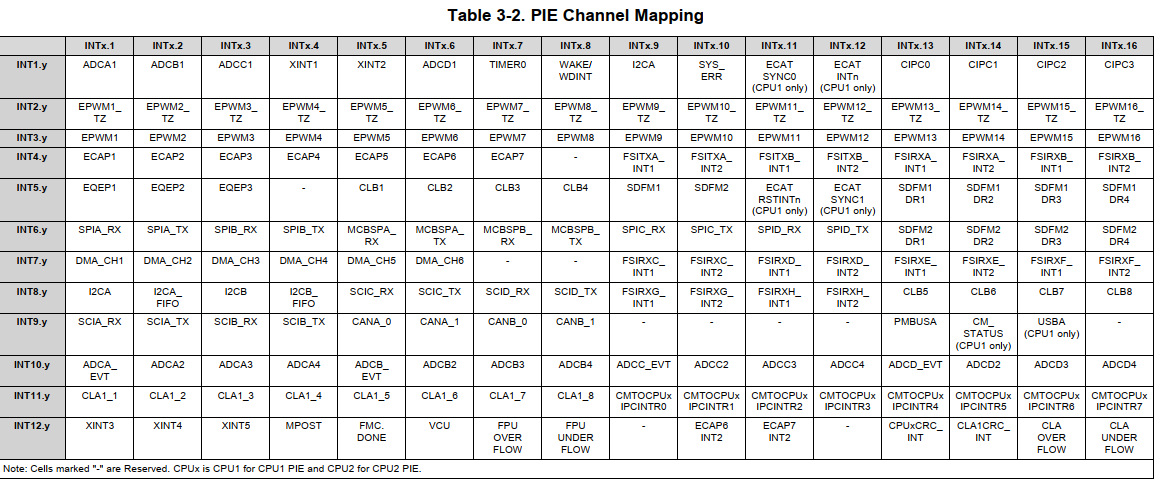
每个输出通道Group单独配置,可响应与其连接的16个外部输入中断。通过下图可知有12个通道直连CPU,所以有12个Group。
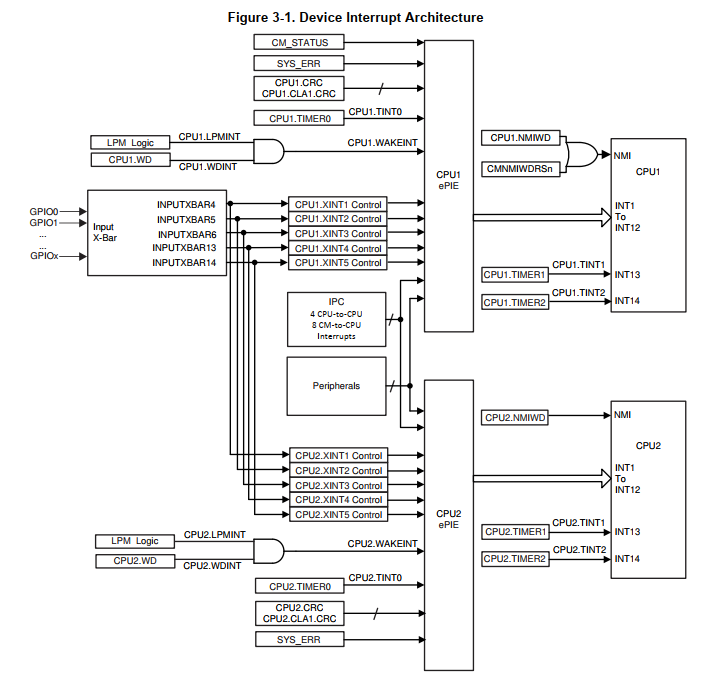 通常来说,每个Group的通道索引越低,优先级越高。Group越低,优先级越高!但是有一些特例。见下图,每个Group的中断结构如下图所示。
通常来说,每个Group的通道索引越低,优先级越高。Group越低,优先级越高!但是有一些特例。见下图,每个Group的中断结构如下图所示。
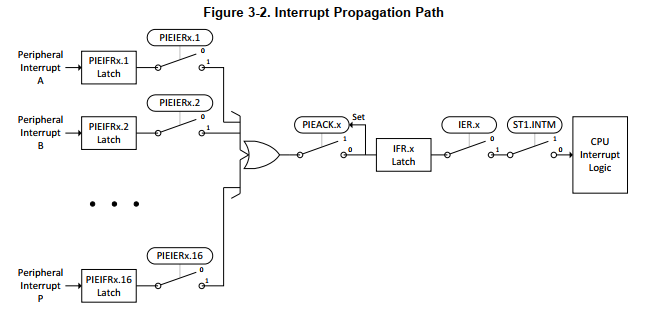
每个中断进来时都会经历如下处理过程。分析可知如果在中断不允许嵌套的情况下:
- 如果两个当前没有中断,两个group同时来到,那么CPU会选择group低的优先处理。
- 如果当前已经在处理一个Group的中断,已经到了step10,这个时候不会响应其它group的中断,但是因为在step11之后才选择具体执行这个group的哪个中断,所以同一group的不同中断低的先被执行。例如如果正在执行2.3,2.1和1.1都来了,会先执行2.1,再执行1.1

- 由step9可知,一个中断处理过程中,是不允许处理其他中断的。如果需要中断嵌套,可能需要在中断函数中重新设置IER和IFR位和全局中断INTM位。
- 中断函数中需要用户清除ACK位,下次中断来才可被执行。IER和IFR位和全局中断INTM位,硬件自动清零后,不需要用户手动恢复。中断函数执行完,自动处理。
- 如果需要嵌套,那么就需要在中断函数中,将现在的配置备份起来,同时只使能比当前优先级高的中断。然后使能全局中断,然后执行当前的中断函数,此时这个中断函数能够被设置的高优先级中断打断。中断函数执行完后,需要恢复寄存器配置,然后失能全局中断。
浮点运算指令的使用
使用浮点运算指令很简单,只要将工程属性,编译器选项中的处理器选项按照如下设置,如果支持FPU64就选fpu64即可。这个时候编译器就会自动将一些乘法指令识别出来并用相应的浮点汇编指令解析。但是有一些复杂的操作,想让编译器自动识别出来,可以调用编译器自带的intrinsics 函数。具体的文档在https://www.ti.com/lit/ug/spru514v/spru514v.pdf?ts=1614305360935&ref_url=https%253A%252F%252Fwww.ti.com%252Ftool%252FC2000-CGT下载参考。
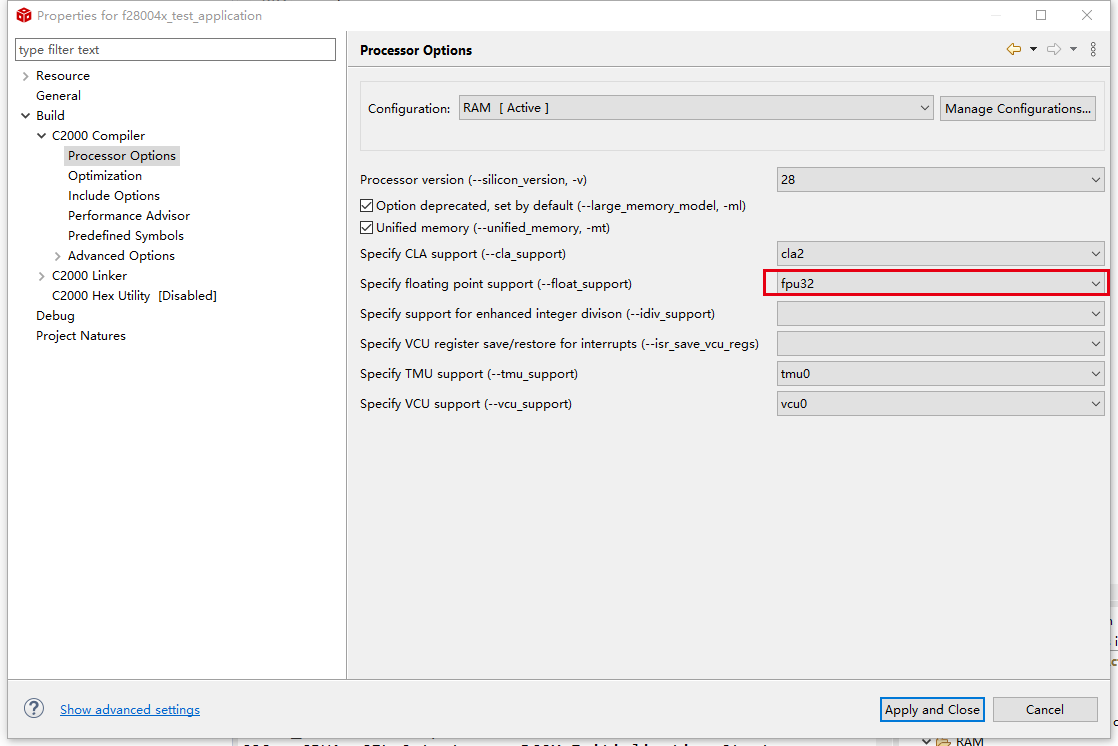
同理,TMU模块提供的三角函数运算指令、VCU提供的CRC快速计算指令,都使用相同的方式调用。
DSP的各个lib库的使用
安装TI的c2000 software support之后,在安装路径下可以找到相关的lib文件。
-
driverlib.lib
这个是外设的驱动文件库,包含了CLA、GPIO、PIE等各个外设的配置函数库。这个一般有debug和release两个版本,需要注意。
-
SFO_xxx_xxx.lib

这是用来给HRPWM进行标定的,具体干啥的现在不清楚。这些版本其实就是文件格式的差异。只要编译器支持这个格式都可以使用。
-
f28004x_diagnostic_stl_debug.lib
这个库是用来给一些模块进行self-test的,暂时用不到。貌似也没有F28388的例程。
-
c28x_fixedpoint_dsp_library.lib
这个是定点mcu的运算库。

后面的_fpu32表明mcu支持FPU32,选择哪个库看处理器是否支持FPU,库提供的接口都是一样的,参数都是定点数。主要封装了一些数字信号处理常用的函数库,例如FFT、FIR、IIR、,函数的传入值都是定点值。浮点数需要转换成定点数再调用这些函数参与运算。同时对于IIR滤波器的参数设置,提供了一个matlab的源文件,及脚本,根据想要的滤波器的带宽,采样频率等能生成一个较为合适的参数,以及选择使用几位的定点值合适。
-
c28x_fpu_dsp_library.lib

这是浮点mcu的dsp.lib区别就是支持浮点运算指令。主要提供了一些数字信号处理的常用函数。

-
C28x_SGEN_Lib_fixed.lib和C28x_SGEN_Lib_fpu32.lib
这两个lib的区别是是否支持浮点运算指令,主要提供了信号发生器的功能,Signal Generator。
-
xxx_VCRC_xxx.lib
主要应该就是对VCRC Unit的使用,协助计算CRC的库吧,暂不深究。
-
F2838x_C28x_FlashAPI.lib和F2838x_CM_FlashAPI.lib
访问flash的库,这个后面可以参考使用。不过据说这里面的函数,为了安全会关中断,这个需要注意一下
-
xxx_CLA_xxx.lib

这些都是对CLA数学运算库。之所以需要这样一个库,是因为CLA访问的内存有限,通过这个库,将常用的数学函数都定义到CLA能访问的内存中。带后缀_datarom的意思是这个库不定义数学函数需要的table,使用CLA_datarom中的table。
-
fastintdiv
这不是个库文件,在libraries 下的math文件夹中有源代码,如果需要整数快速除,可以试着用一下。
-
rts2800_fpu32_fast_supplement.lib

这个是对支持FPU的快速运算库。提供了一下atan、cordic_sin以及各种类型的除法运算,基于FPU,使用了查表法,对一些FPU不支持的指令或者比较慢的指令,进行优化来加快运算速度。
-
IQmath.lib
提供接口将浮点数转换成不同位的定点数。并提供一系列的数学函数。例如sin、cos、sqrt,乘除等。应该也是用的查表法。
-
F2838xCM_BootROM_Symbols.lib、F2838xCPU1_CLADATAROM_Symbols.lib等和BootROM的lib
BOOTROM中包含了一些函数的代码,为了节省空间,用户可以直接使用这个库以及链接文件,这部分函数代码将不会copy到生成的可执行文件,直接链接到ROM的指定地址。但是前面的浮点运算dsp库,里面也会有这些symbol的定义,如果同时使用这些库,为了使用BooTROM.lib,需要改变库的链接顺序,BootROM.lib放到前面。
-
有一个没有解决的问题,是引入BOOTROM_SYMBOL.lib,lib中symbol所在的section,并没有在cmd文件中指示链接位置,没找到section定义的位置,也能正常工作。去掉lib就会说symbol未定义。lib源文件中值定义了symbol以及section,有一个附带的链接文件,是bootrom的源工程,但是没有lib的源工程。猜测使用pragma使得地址与bootrom中的一样?这个目前就当lib使用pragma了吧,变量地址默认就在bootrom相应的地址中,不需要再额外定义。
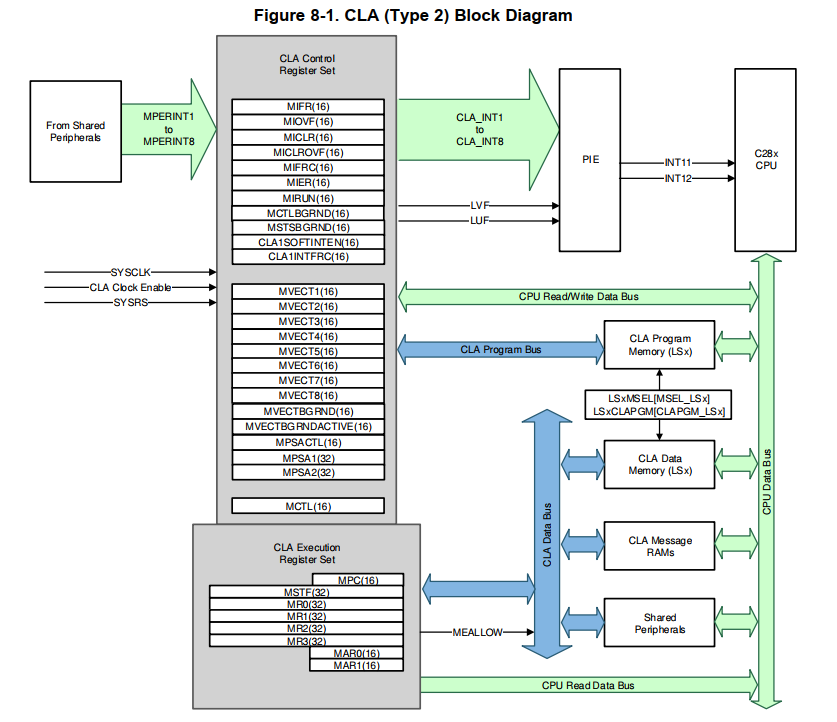
CLA的使用
-
CLA是一个支持FPU32的独立的处理器,支持特定的指令集。
-
后缀.cla的文件自动使用CLA编译器进行编译,代码会被编译到section CLA1Prog中。
-
CLA最多支持8个任务,每个时刻只能执行1个任务,一般来说,当前任务执行完才会执行其它任务,不允许嵌套,按照任务号选择下一个任务,任务号低的优先级高。但是第8个任务可以配置成后台任务,不用触发,只要CLA使能后,一直运行,后台任务可以配置成可以打断的,只有这种情况下才可以嵌套。
-
任务的执行可以选择不同的方式触发,可以软件触发,也可以使用外设触发。
-
CLA代码不允许调用非CLA模块的代码,不允许定义全局变量。
-
LS0-LS7可以用来放CLA的代码和数据。需要注意加密保护。
-
CLA Shared Message RAMs 是用来CPU和CLA通信的,CLA和DMA通信的。

共有四个RAM,CPU对CLA-CPU的写会被忽略。具体权限分配

-
CLA的每个任务完成后能生成中断给CPU
-
CLA的任务中尽量不要放分支代码,影响效率。
-
CLA只能访问有限的指令数据内存空间,并且与CPU的地址大部分一致,刚好是CPU的前面一部分空间

CLB的使用
- CLB通过单独的CLB tool配置,具体可以参考C2000WARE_INSTALL_LOCATION\utilities\clb_tool\clb_syscfg\doc
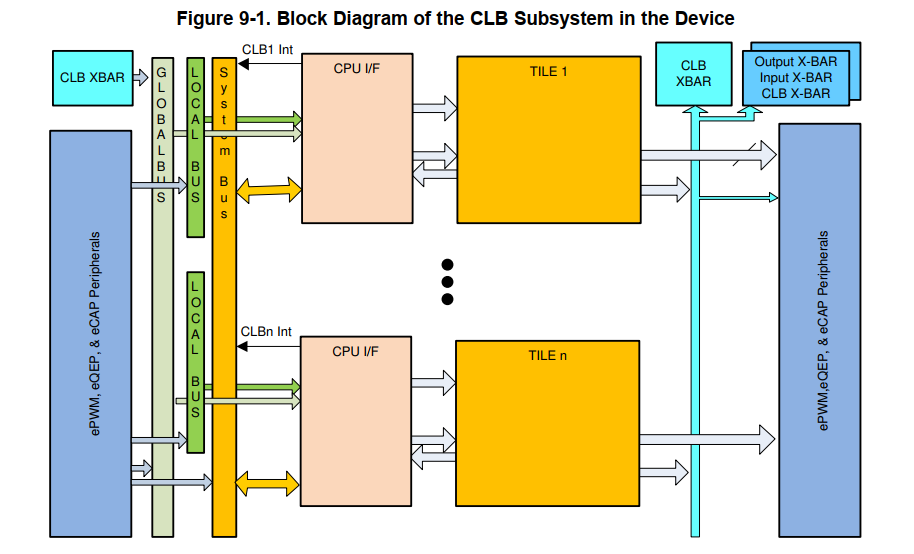
- CLB最大支持频率150MHZ
- CLB系统中总共有4个CLB,每个CLB由CPU I/F和Tile构成。每个Tile有8个输入和8个输出。但是8个输出被重复一次,所以总共有16个输出可以单独控制。对于CLB Type 2,会在重复一次,有32个输出。
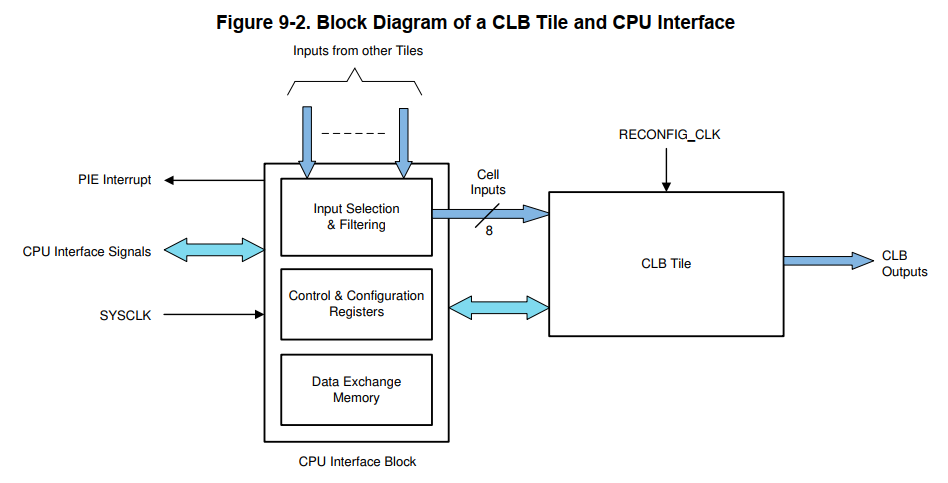
- CLB有一个预分频模块,不改变实际CLB工作的频率,但是生成的信号可以用来做CLB的输入信号
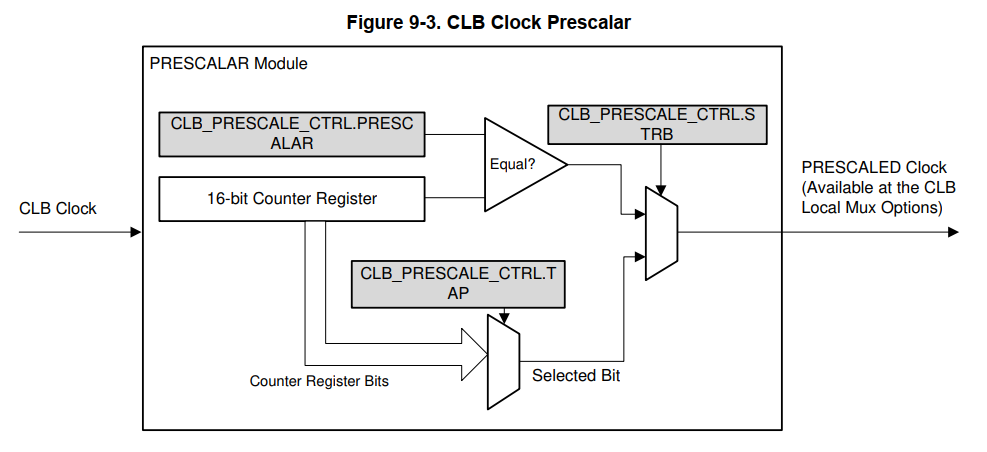
- 每个CLB有8个输入,每个输入可以被单独配置。通过配置如下图所示的寄存器可以选择最终生效的输入信号。寄存器的值与所选信号可以参考手册的Table 9-1、 Table 9-2 。
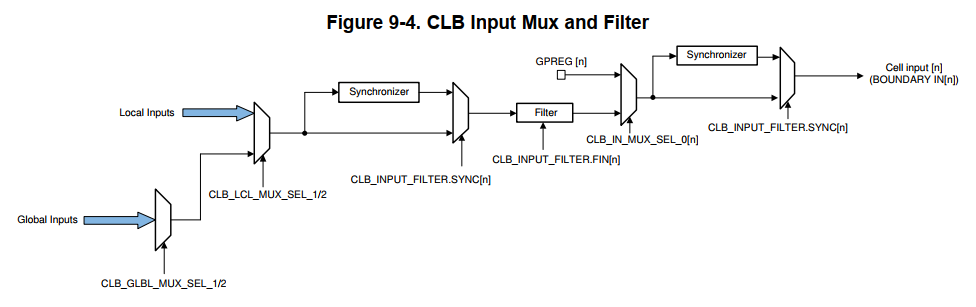
- 每个CLB的输出会和一个特定的外设信号一起经过一个多路选择器,多路选择器的输出就是最终的外设信号,例如PWMA之类的信号,默认CLB不启用时,PWM输出的信号直接输出,可以通过配置使得CLB的输出将外设原始信号覆盖。
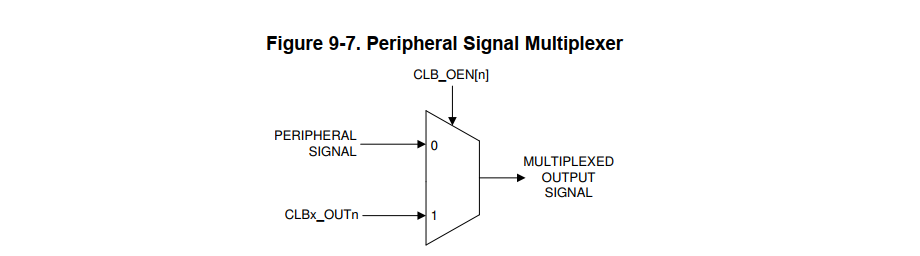
- CLB的tile结构。每个tile由3个counter、3个LUT4、3个FSM、8个Output LUT3、1个HLC、Configurable Switch Block 、Asynchronous Output Conditioning Block 组成。
- Static Switch Block。tile内部的每个输入都有这样一个block,block的输入是tile内部各个子模块的输出和8个外部输入。通过寄存器可以配置每个输入的源信号。
- Asynchronous Output Conditioning Block。这个是对output LUT的输出信号进行调节的。输出信号经过AOC block才会最终输出。AOC主要用来对输入信号进行调制的,可选择的对输入信号取反、与门控信号逻辑运算等操作。
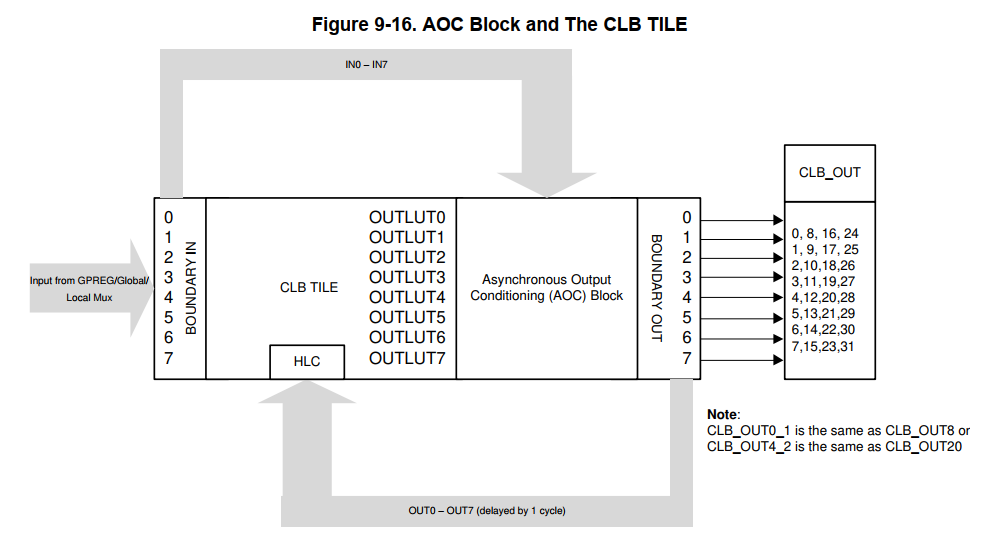 AOC对输入信号处理分为3个阶段
AOC对输入信号处理分为3个阶段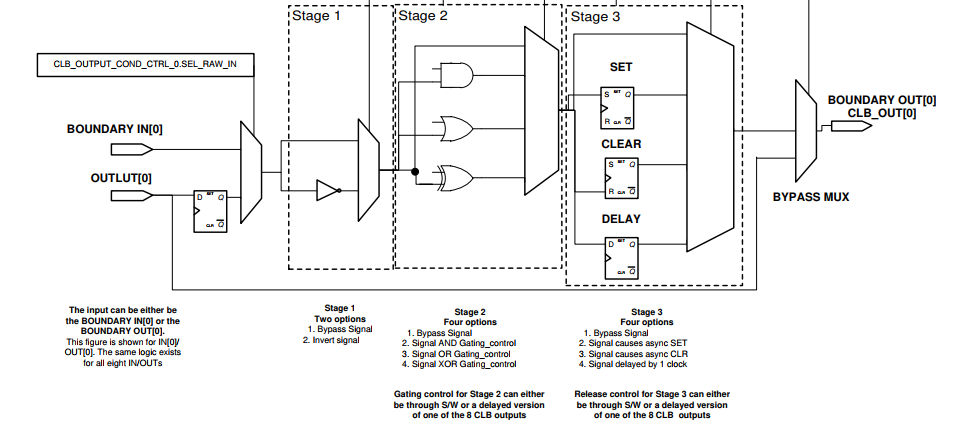
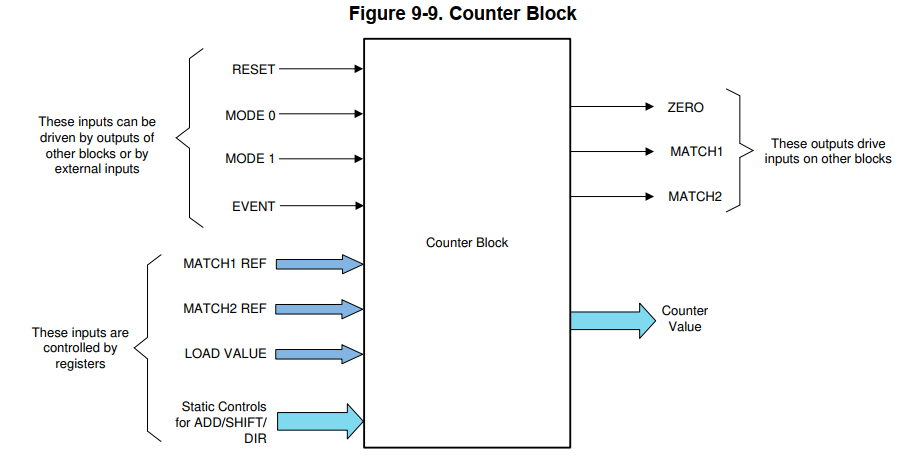
- counter block。能够运行在不同的模式,内部有个计数器,能支持递增、递减、与参考值加减、移位运算。能够输出当前计数器值,以及3个状态值。每次触发event时间会执行一个动作,load、add、sub、或者移位。
 CLB Type 2 还支持额外两种模式:Serializer Mode 、Linear Feedback Shift Register (LFSR) Mode 。
CLB Type 2 还支持额外两种模式:Serializer Mode 、Linear Feedback Shift Register (LFSR) Mode 。 - FSM Block。有限状态机,输出是当前状态的函数,函数是用寄存器表示,当前状态是寄存器的索引。就能确定某一位的输出。可以配置成单个4状态,或者两个两状态,或者是LUT4
- LUT4。就是个查找表,根据输入的索引,确定寄存器的值然后输出。
- HLC。支持4个独立的事件触发。每个事件触发将会执行一段最多8个指令。指令的编码规则在文档中有详细定义。每个事件有独立的两个存取fifo支持与CPU数据交互。CPU能配置每个事件的指令。
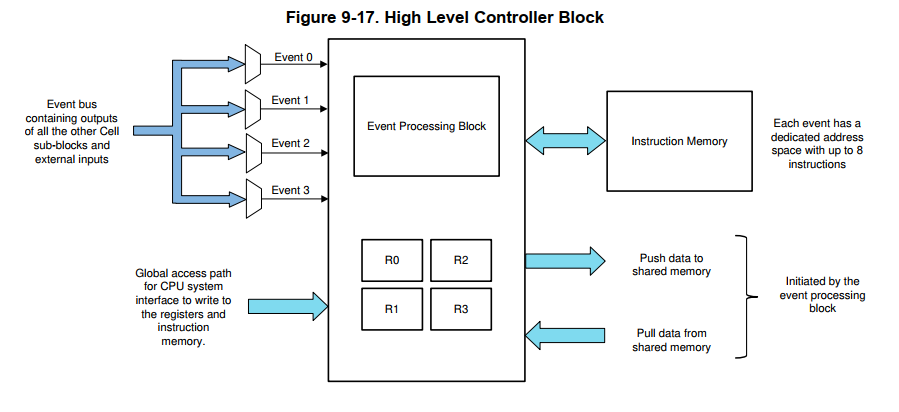
IPC
- IPC总共有3个,其实只有两个,CPU1-CPU2,CPUx-CM。
- IPC是基于事件的,每个方向上有32个事件。对CPU1-CPU2来说,CPU1能给CPU2发送的事件有32个,同理CPU2发给CPU1的也有32个事件。
- 事件可以触发中断,对CPU1和CPU2来说,IPC0-IPC3可以被配置触发中断。对CM来说IPC0-IPC7可以被配置触发中断。其它的只能通过轮询查询。
- IPC事件相关寄存器有4个
- IPCSET 主CPU用来发送事件
- IPCFLAG 当发送事件后,主CPU这个flag置1
- IPCSTS 当发送事件后,从CPU这个状态 flag置1
- IPCACK 从CPU写此寄存器,回应。同时会清除IPCFLAG、 IPCSTS
- IPCCLR 主CPU写这个寄存器,取消事件,同时会清除IPCFLAG、 IPCSTS
- IPC Command Registers 。提供一个简单的协议,两个CPU间交互。
 如上图所示。一个CPU对COM、ADDR、DATA三个寄存器有写的权限,对另一个寄存器有读的权限,相对应的另一个CPU对着三个寄存器只有读的权限,对另一个只有读的权限。每个IPC有两份,另一份寄存器类似。供两个CPU传输交换数据。
如上图所示。一个CPU对COM、ADDR、DATA三个寄存器有写的权限,对另一个寄存器有读的权限,相对应的另一个CPU对着三个寄存器只有读的权限,对另一个只有读的权限。每个IPC有两份,另一份寄存器类似。供两个CPU传输交换数据。 - Free-Running Counter 。每个IPC有一个,64位用来提供时间戳。当读低32位时,高32位被锁定。时钟PLLSYSCLK。被SYSRSn复位。debug的时候两个cpu都挂起,才会停止计数。一个还在运行,不会停止计数。
- IPCBOOTMODE 和IPCBOOTSTS 在boot过程中用到
DMA的使用
- 每个DMA有6个通道。
- DMA每个ch,能由外设触发,也可以由软件触发,触发事件执行前,可以通过软件清除。触发事件开始执行,就会清除标志位,等待下一次触发。触发事件执行中,再触发一次,会在当前事件结束后执行,如果再触发两次,就会报错。如果触发事件一开始执行,刚清除标志位,就有触发事件,这个触发事件优先级最高被执行。触发一次会执行一次内循环
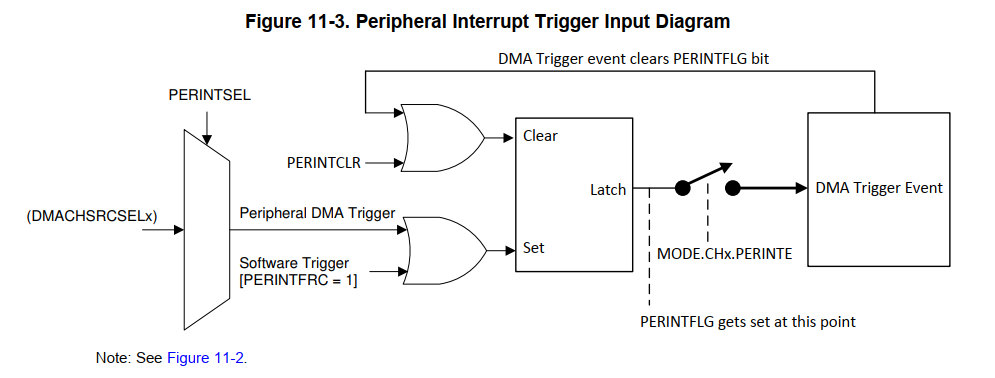
- DMA有32位的地址总线、32位的读总线、32位的写总线。可能与其他CPU的访问产生竞争。
- DMA核心是两个嵌套的循环。
- 内循环执行一次突发传输,最大支持32个16位的传输,通过BURST_SIZE、MODE.DATASIZE 寄存器设置。
- 外循环是执行多少次突发传输。通过TRANSFER_SIZE 设置。
- 一般情况下地址递增。但是地址回环模式下不是,是否地址回环是通过回环SIZE和Transfer size决定的。当突发传输完成的次数与回环设置的size相等。实际传输地址将根据回环地址以及设置的步进长度重新设置。
- 单次触发模式。使能的话,每个通道传输完所有的突发传输。才跳转到其它通道执行。否则就传输完一次突发传输,就切换到下个通道,不管是不是所有的数据传输完。避免同一个通道占用时间太久。
- 持续模式。使能,单个通道所有数据传输完成后,仍保持活跃状态,等待下一次触发。否则传输完所有数据后,就被disable,需要重新设置使能才可用。
- 当访问共享同一总线的外设时,会产生总线仲裁。

- DMA的优先级有两种方式
- 循环模式。这个模式,优先服务下一个ch。例如当前服务ch4,ch1和ch5同时触发,会选择ch5执行,当空闲的时候,ch1最先被执行。
- ch1优先级最高。其它的按照循环模式处理。
- DAM处理溢出。也就是当前触发还没开始,又来了触发事件会被丢失,这个时候会设置OVEFLG寄存器。如果中断使能的话,会触发中断。
debug和调试
- 直接使用stdio.h提供的print函数。需要给定heap的大小,cmd文件中的。sysmem用来分配内存申请的空间的。.cio section是一个buffer用来存打印数据。这个函数浪费较多资源,且不实时,顺序不确定。
电流环效率优化
#pragma CODE_ALIGN(FCL_runPICtrl_M1, 2)
#pragma FUNCTION_OPTIONS(FCL_runPICtrl_M1, "--auto_inline")
#pragma FUNCTION_OPTIONS(FCL_runPICtrl_M1, "--opt_for_speed")
#pragma FUNC_ALWAYS_INLINE(buildLevel46_M1)
查看TI的代码,所谓的快速电流环,主要在CLA执行了三个任务。用PWM触发中断,而且还是在中断里等这三个CLA任务处理完成。:
-
执行编码器电角度的计算。分为三个部分
- 找电角度为0阶段,编码器的处理。主要是清零编码器,设置周期。
- 寻相阶段。编码器的处理。初步看也像是锁不同的位置来判断方向。
- 正常运行阶段。编码器的处理
-
以及PI运算的一小部分。PI运算取巧,将状态更新的部分都放到中断的后面运算,其实也是必须的。
-
计算编码器的速度。
-
TI的电流环PI实现方式如下:将输出和状态更新分开,节省电流环运行时间。
O u t = O u t + K p ( E r r − E r r L a s t ) + K i 2 ( E r r + E r r L a s t ) Out=Out + K_p(Err-ErrLast) + \frac{K_i}{2}(Err+ErrLast) Out=Out+Kp(Err−ErrLast)+2Ki(Err+ErrLast) -
电流环函数的中间变量使用register声明。函数都使用内联函数或者宏定义。、
Hex和bin的生成
-
hex是带有地址信息的数据流,flash下载器根据地址将数据下载到指定位置。数据不连续。
-
bin文件通常能直接下载到flash里,数据连续。
-
ccs编译出来的.out文件,能够转换成hex文件以及bin文件。如果cmd文件将各个section定义的地址不连续,可能导致最终的bin文件很大,中间都是没有使用到的,会使用默认的数据填满。为了避免这个情况,应将一个程序所需要用到的空间放到一块。
-
最终的升级文件AFM文件,以前都是一片连续的空间。将hex进行解析加密,生成AFM文件。板卡收到该文件后,重启。进行MD5校验,然后解密,将解密后的数据放到指定地址,地址是连续的。所以这也是为什么需要将程序所需空间尽可能放一块的原因,避免空间资源浪费。
-
hex生成很简单,右键工程,属性
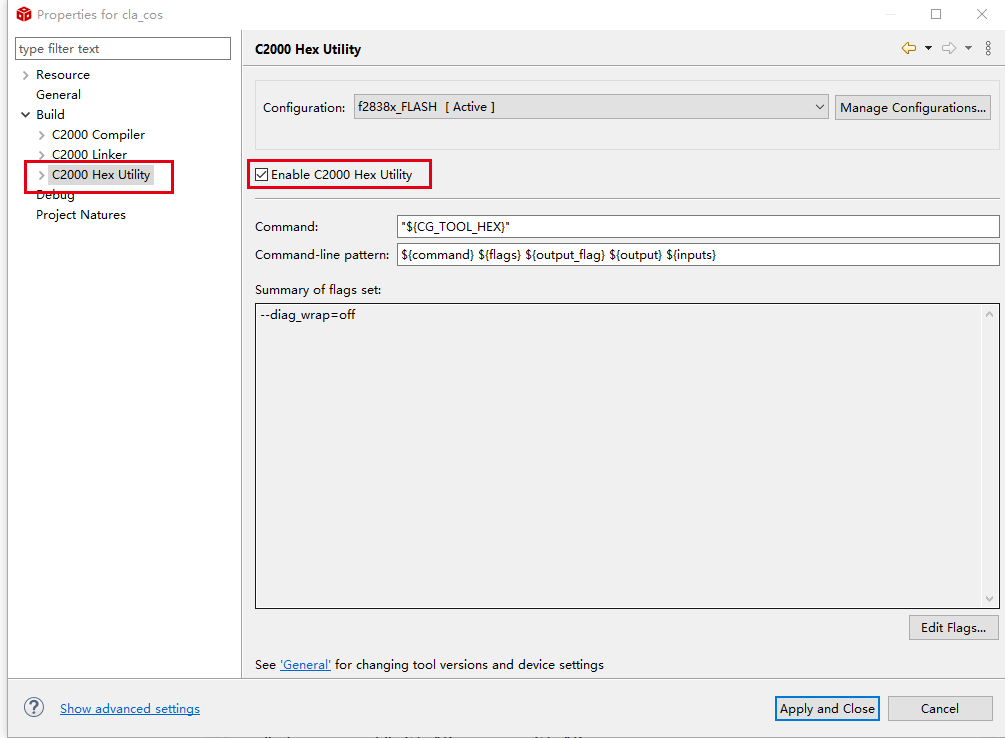
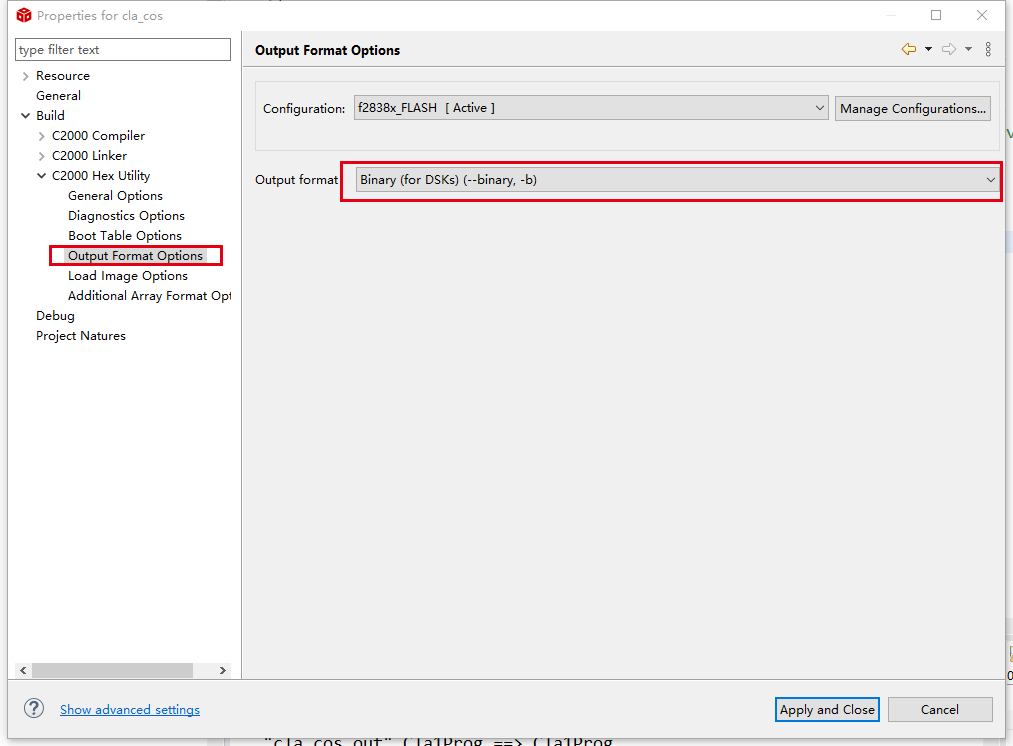
-
生成bin文件,麻烦一点,总共有三步,此方式只是用于c2000系列,其它的可能需要进一步修改脚本文件:
-
将脚本out2bin.bat复制到当前工程路径下。
-
修改脚本文件中的CCS安装目录。

-
将下面的指令复制到工程的Post-build steps中
"${CCS_PROJECT_DIR}/out2bin.bat" "${BuildArtifactFileName}" "${BuildArtifactFileBaseName}.bin" "${CG_TOOL_ROOT}/bin/ofd2000" "${CG_TOOL_ROOT}/bin/hex2000" "${CCS_UTILS_DIR}/tiobj2bin/mkhex4bin"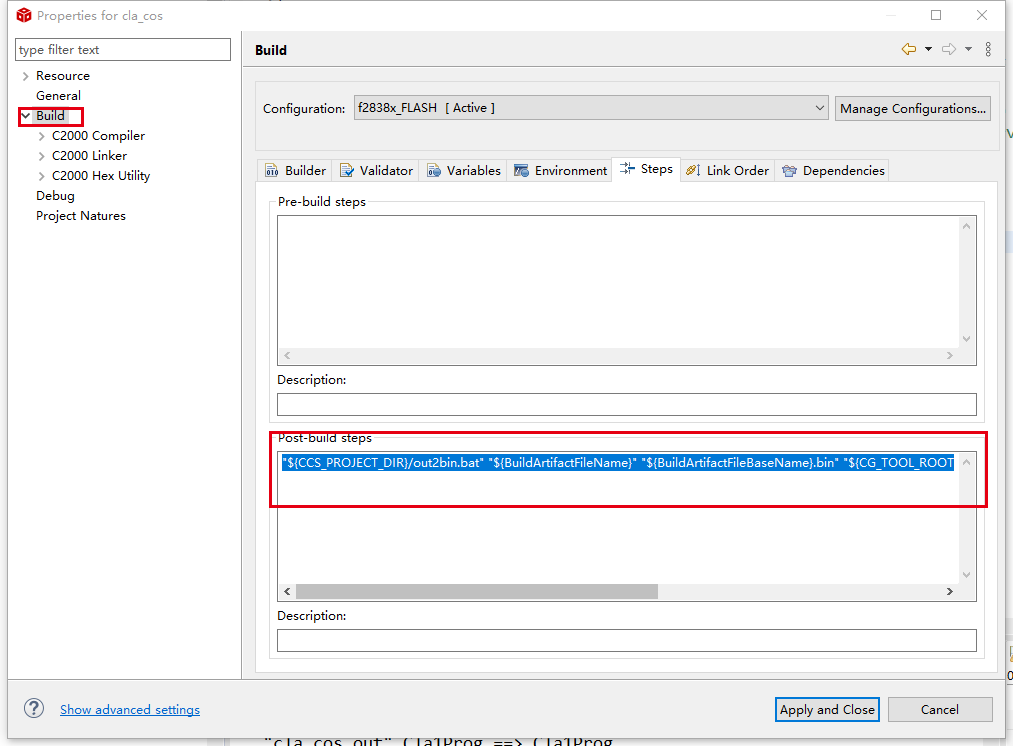
-
DCSM
- 这个安全模块限制CPU对安全区域的访问,而不发生中断和阻塞。对安全区域的读会返回0.并继续执行下一条指令。外设和jtag也是一样的。
- 安全资源有四种:
- 独有的OPT。OPT包含安全模块的配置以及密码,OPT的内容只能在ZONE通过PMF解锁后才能读
- RAM。特定的RAM可以被分配为安全资源。可以通过GRABRAM分配到ZONE1或者ZONE2
- FLASH Sectors。可以通过GRABSECT分配到ZONE1或者ZONE2。
- SECURE ROM。设备上有secure ROM,这个也是安全资源。EXE-ONLY代表CPU只能执行该区域指令,而不能读该区域数据。
- 每个ZONE的安全由自己的128位CSM密码保证。保存在OPT中。每个ZONE中有很多block,密码可以单独配置。
- 下图展示了每个RAM或者Sector怎么分配到哪个ZONE,以及是否是secure的。每个ZONE有独立的寄存器包含对所有RAM和flash的配置,配置是否是安全的,以及一些区域还可以通过EXEONLY寄存器能配置为只能执行
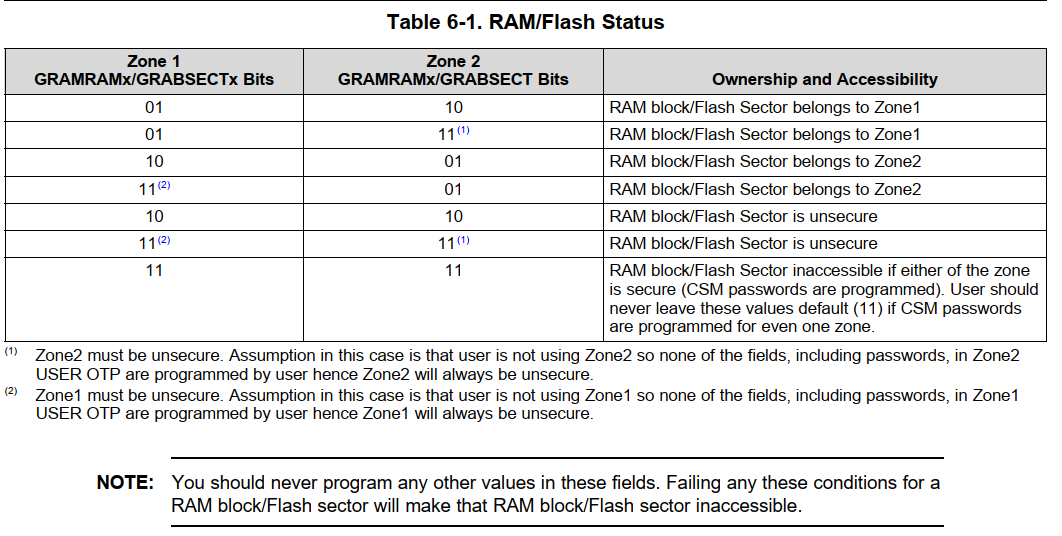
- 对资源的访问分为几种,见下图:

- 针对对安全资源的访问,当前执行的访问代码在安全资源内还是外面访问,分为以下几种安全级别。

- 不像早期的C2000设别,128位全是1的密码能用来加密。现在这样,会导致设备进入BLOCKED state。TI会根据ECC将每个block的CSMPSWD密码的第二个32位的几位置为0。用户只能将第二个32位的1置为0吗,而不能将已经置为0的置为1。密码全是0会导致设备永久锁住。正常工作情况下可以通过用户可访问的CSMKEYx寄存器来解密。
- ECSL模块,主要作用是避免没有经过验证的人单步调试代码。如果执行到了secure code,并且cpu halt,仿真就会断开连接。为了允许在安全资源debug,需要写合适的64位key到CSMKEY0/1寄存器,这个值和USER OPT中的一致。有一个问题需要注意,仿真的时候,需要一定时间控制cpu,这段时间CPU已经执行到用户的secure code,会导致连接不上。这个时候可以通过配置wait boot mode,先设置好key,再调试代码。
- CPU Secure Logic。这个防止黑客读CPU寄存器,当代码正在secure code中跑的时候,所有对寄存器的访问会被阻塞。如果CSM被unlock了,这个也不生效。
- Execute-Only Protection 。当RAM和flash设置成这个属性,任何区域的代码都不可以读这个区域的数据。
- Password Lock 。出产时OPT里的password是没有加密的,即使其他区域都是加密的。除非将PSEDLOCK的值设置成除了0xF之外的值,0xF是出厂默认的。这样password就不能被不安全的代码读到。如果没有lock,用户可以直接读到密码,然后就可以unsecure整个zone,就相当于没有secure。所以正式发布时,需要将这个password得lock一下。
- JTAGLOCK 。这个是用来防止jtag访问的。

- LINKPOINTER。这个的作用是具体选择哪一个block的密码作为最终的密码。因为OPT的linkpointer的值只能从1到0,,OPT中总共有三个,最终生效的linkpointer根据这三个值通过一个算法得到,通过寄存器读取。总共有16个block可以选择,也就是有16种密码,内存的安全资源分配方案备选。通过设置linkpointer,可以改变方案,开发时可以使用,避免误操作!
- OPT不能直接访问读取,需要通过dummy read,将值更新到寄存器中。这个还得进一步确认。
SPI
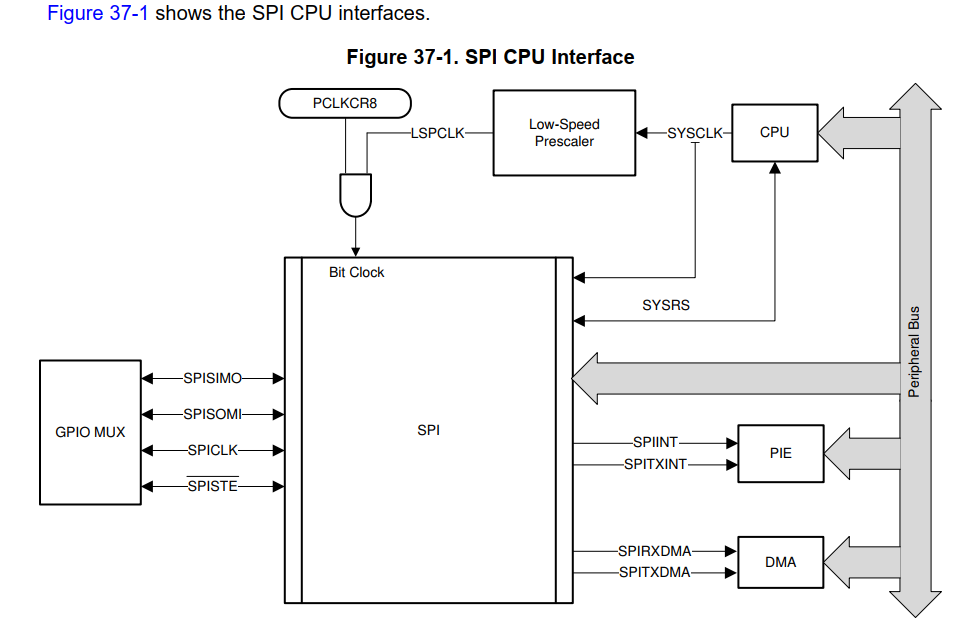
- 支持主从模式
- 125种不同的波特率,最大波特率受SPI Pins 的IO/Buffer的最大速度限制
- 数据宽度:1到16位
- 四种时钟方案,在时钟的上下沿触发传输,是否有延时
- 同时的接收和发送操作
- 发送和接收操作可以通过中断触发和查询
- 各引脚作用
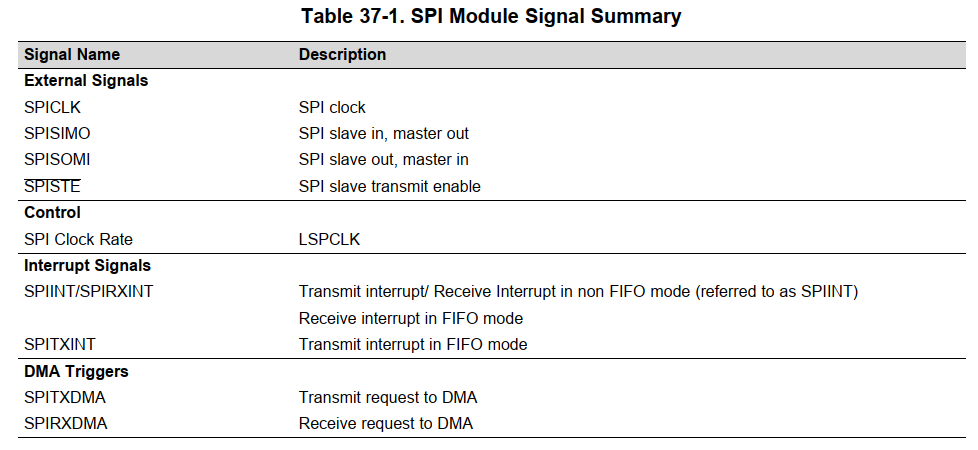
- 支持触发DMA发送和接收数据
- 有两个中断信号,fifo模式和non fifo模式能够最终生成的中断信号不一样。
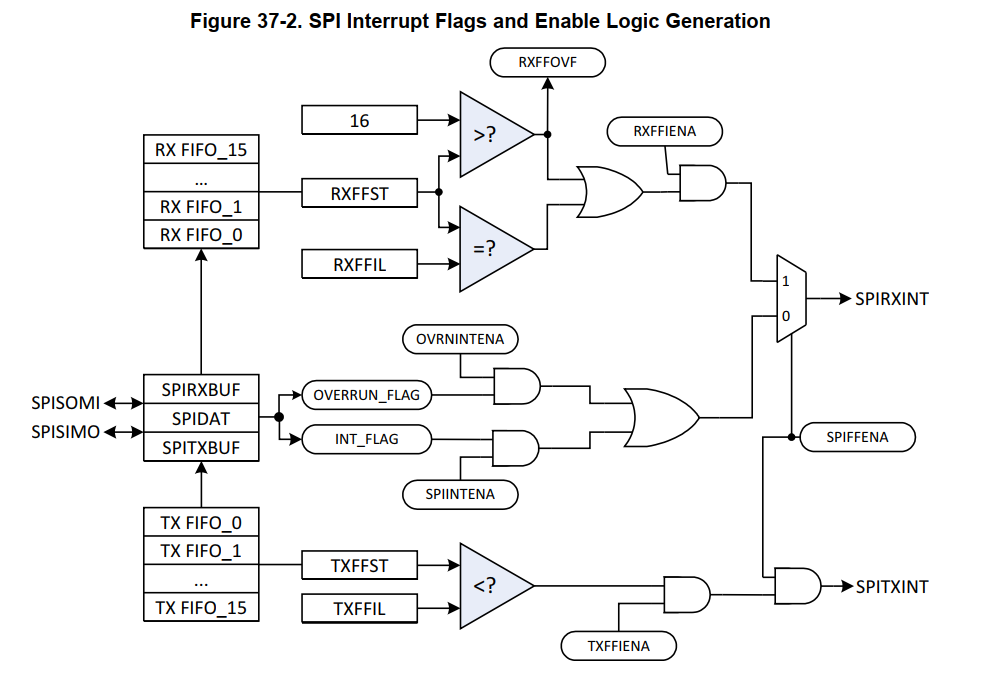

- 数据被写到SPIDAT中触发发送,同时接收的数据也在SPIDAT更新,通过移位操作完成。

- SPI支持三线模式,工作在半双工模式,也以用在loopback模式下,在master模式下
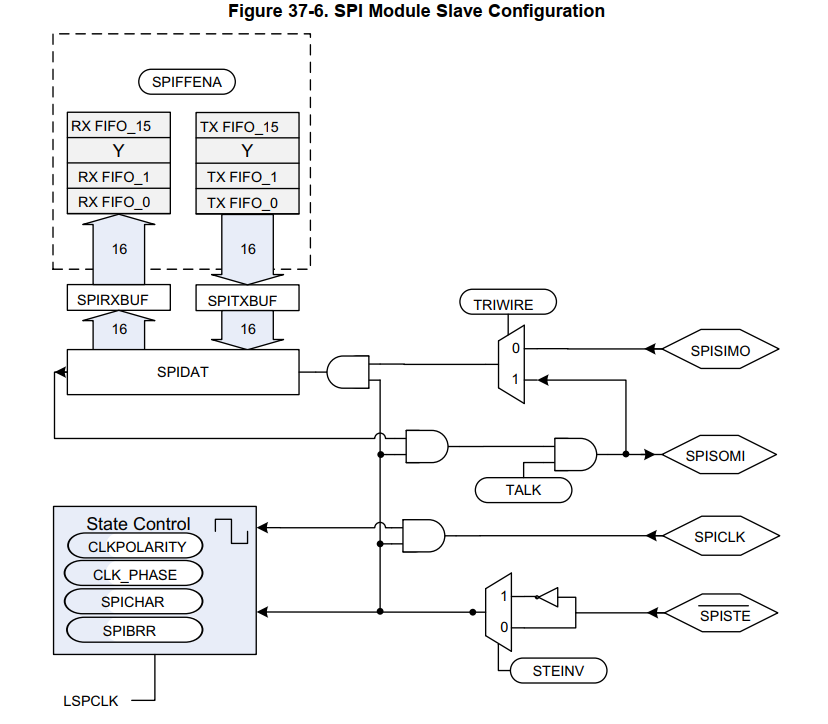
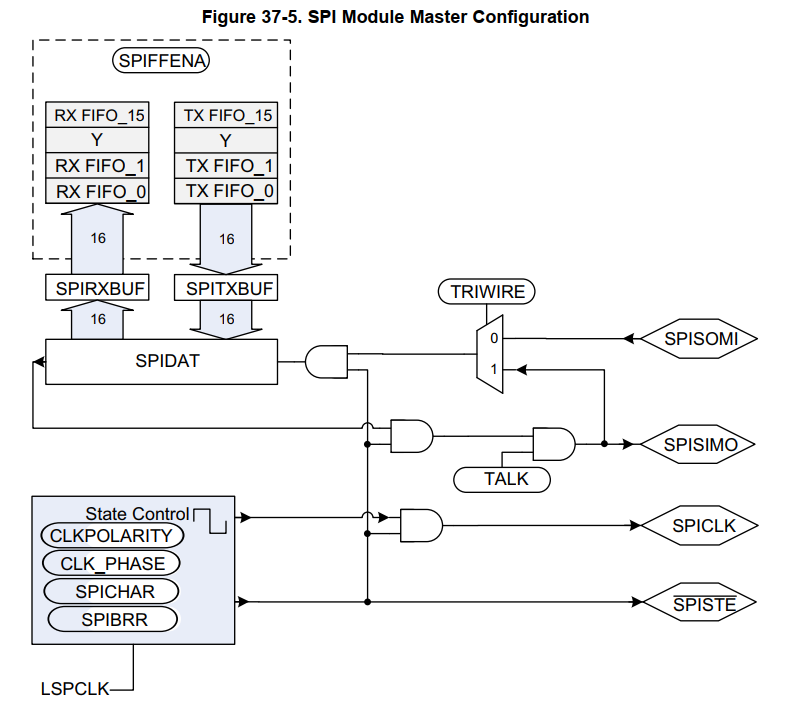
其它
- cmd文件的fill,需要type=noinit,且程序中有使用过定义在该section的变量才可生效。
- cpu2如果有初值的全局变量定义在GS里,这个值不会生效,因为cpu2没有访问gs的权限,需要cpu1分配gs给cpu2
- 目前遇到了一个现象加载loadcpu2的程序会覆盖掉cpu1全局变量的初值。理论上应该不会对gs有读写的操作才对。
- flash启动的时候cpu1配置cpu2和cm核为wait模式,是能生效的,这个时候cpu2和cm核会等待cpu1配置启动
- 发现一个现象在ram里跑的代码,如果访问flash里的常量大概率是有问题的。cm核debug版本,将const段定义在flash里,程序会跑飞。


















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









