







本博文写作参考程序员Carl 微信公众号(代码随想录),致谢!
回溯算法是一种遍历暴力穷举,时间复杂度很高。通常用于搜索一个问题所有的解,可通过深度优先遍历的思想实现。与动态规划的区别是,动态规划通常只需要求解最优解,而回溯要遍历所有解。
一、回溯是什么?
回溯法采用试错的思想,它尝试分步地去解决一个问题,当发现有分步答案不正确的时候,它将取消上一步的计算,再尝试其他可能的解答。回溯法通常用递归来实现。再反复进行上述步骤之后可能出现两种情况:
- 找到一个可能存在的正确答案
- 尝试了所有的分步方法之后,宣告该问题没有答案
1. 回溯法能解决什么问题?
回溯算法强调了回退操作对于搜索的合理性,而深度优先遍历强调的是一种遍历的思想。
为什么回溯法既难理解,又不高效,还要选择用它呢?
因为没得选,一些问题只能暴力搜索,撑死了再剪枝一下,没有更高效的解法。
那么是什么问题这么牛逼呢?通常来讲,回溯法用于解决如下几种问题:
- 组合问题:N个数字里边按照一定规律找出K个数的集合
- 排列问题:N个数字按照一定规则全排列,所有的排列方式
- 切割问题:一个字符串按照一定规则有几种切割方式
- 子集问题:一个N个数字的集合里有多少符合条件的子集
- 棋盘问题:N皇后,解数独
从上边可以看出,回溯法要解决的问题都是在集合中递归地查找子集合,所以都可以抽象为树形结构的问题。
2. 回溯法的模板
- 回溯函数模板返回值及参数:回溯算法函数返回值一般为void
参数由于不像二叉树递归的时候可以容易地一次性确定,一般是先写逻辑,然后根据需要添加参数。void backtracking(参数) - 回溯函数终止条件
既然都是树形结构,那么到叶子节点自然就要终止。if(终止条件) { 存放结果; return; } - 单步逻辑
回溯法 = 递归过程 + 嵌套for循环for(选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) { 处理节点; backtracking(路径,选择列表);//递归 回溯,撤销处理结果; }
二、回溯算法的步骤
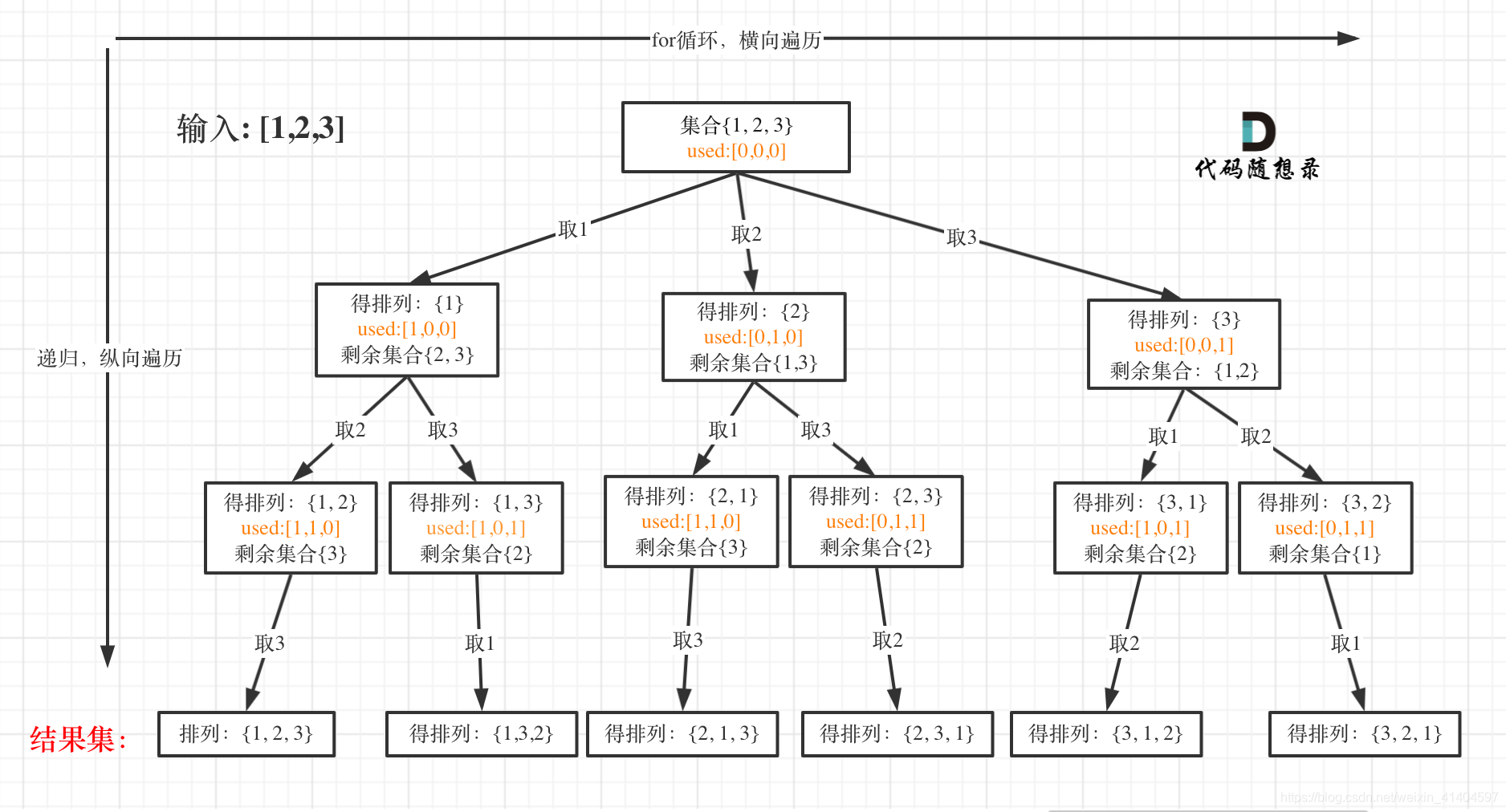
本文以Leetcode-46.全排列问题为例,讲解回溯算法的常见步骤。
0.题目描述
全排列问题 A n n A_{n}^{n} Ann
- 状态变量:每一个节点,表示了求解一个问题时所处的阶段性状态
- 状态重置:搜索“回头”时,状态变量需要设置为和以前一样。在回到上一层节点的过程中,需要撤销上一次的操作。
- 状态空间:保存状态变量的栈空间,尾部添加,尾部删除。
1.设计状态变量
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, vector<bool>& used)
2.设定递归终止条件
遍历到叶子节点就是终止的地方
当收集元素的数组path的大小和nums数组一样达到时候,说明到底
if(path.size() == nums.size())
result.push_back(path);
return;
3.单层操作
used数组:记录path里边有哪些元素被使用过了,一个path里一个元素只能用一次。
for(int i=0; i<nums.size();i++)
{
if(used[i] == true) continue;
path.push_back(nums[i]);
used[i] = true;
backtracking(nums,used);
path.pop_back();
used[i] = false;
}
4.剪枝优化(选作)
通过剪掉明显错误的分枝,优化代码的运行时间。其实就是将上一步for循环里i的范围改小。
- 直接缩减 i 的遍历范围,倒着数可以遍历到的边界
- 通过在for循环里添加判断语句跳过某些情况
- 对于求和问题,通常先排序再在回溯过程中剪枝
三、总结
最终整体代码如下:
class Solution{
public:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, vector<bool>& used){
//终止条件
if(path.size()==nums.size())
{
result.push_back(path);
return;
}
//单步操作
for(int i=0;i<nums.size();i++)
{
if(used[i]==true) continue;
path.push_back(nums[i]);
used[i]=true;
backtracking(nums,used);
path.pop_back();
used[i]=false;
}
}
vector<vector<int>> permute(vector<int>& nums)
{
result.clear();
path.clear();
vector<bool> used(nums.size());
backtracking(nums,used);
return result;
}
};
从过程可以看出,回溯三部曲和递归三部曲是一样的。
- 确定函数类型及返回参数
- 确定终止条件
- 单步操作逻辑
区别好像就是
- 回溯在单步里边有撤销操作,普通递归没有。
- 回溯在单步操作里有横向for遍历,普通递归好像没吧??
那么问题来了: - 递归和回溯的实质性区别到底是什么呢?
- 如何设计函数类型及返回参数?
- 什么时候需要回撤,什么时候不用回撤呢?
- 递归函数什么时候要返回值,什么时候不要返回值呢?
关于最后这个小问题,其实函数参数还包括两种类型,一种是void型,一种是常规数据类型(比如int)。
但是在主函数中调用的时候,有的时候后者也不赋给任何值。
设计常规数据类型的目的应该还是为了在迭代过程中记录中间数据。
那么应该怎样设计void还是普通数据类型呢?














 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









