






MySQL如何实现分页
MySQL通常使用limit关键字实现分页,有以下两种方式能够实现分页:
- limit n,m:从第n条记录开始(不包含第n条),往后捞m条数据
- limit m offset n:从第n条记录开始(不包含第n条),往后捞m条数据,n默认为零
两者只是写法不一样,实现效果一样。这两种写法在数据量较少的场景下,并不会有什么很大的问题,但是一旦当数据量在百万级甚至千万级,如果没有做特殊的处理就会出现臭名昭著的深分页问题,导致程序运行十分缓慢。
limit还有一个值的一提的用法就是:limit n,即返回n条数据。
如何高效分页
在如今的互联网企业中,别说百万级数据,亿级数据都是很常见的,那对于这么大的数据量我们如何解决深分页问题呢?
想要让SQL跑的更快,无非要借助索引,同学们思考下,limit关键字实现的就是傻瓜式的逐页往后翻,那我们能不能借助limit n实现往后翻的效果呢。答案是肯定的。我们接下来就来动手实践。看优化后的分页查询效率是如何起飞的。
我们首先创建如下表结构 :
create table t_compare
(
id bigint not null comment '主键ID'
primary key,
name varchar(64) not null comment '名称'
);
并插入十几万数据,以分页使用

既然我们是从索引的角度优化分页,那每个表必不可少的就是主键索引,我们就从主键索引入手,这里补充一个小知识:
MySQL中每个表都有主键索引,其规则如下:
如果字段显示声明了primary key,则该字段为当前表的主键,如果没有显示声明,MySQL会自动去找声明了唯一索引并且不能为空的字段作为该表的主键,如果前两者都找不到,那么MySQL就会自己隐式维护一个主键。
这里因为我们需要使用到主键进行分页,所以我们显示声明id为primary key,我们编写代码如下:
@Test
public void testManualPage() {
// 按照id升序查询第一个符合条件的数据
Long firstId = this.queryFirstId();
// 按照id分页
log.info("sumSize:{}", this.loopManualPage(firstId, 1000L, true, 0));
}
/**
* 递归手动分页
*
* @param firstId
* @param pageSize
*/
private Long loopManualPage(Long firstId, Long pageSize, boolean firstQuery, long sumSize) {
LambdaQueryWrapper<Compare> lambdaQueryWrapper = new QueryWrapper<Compare>().lambda();
lambdaQueryWrapper
.ge(firstQuery, Compare::getId, firstId)
.gt(!firstQuery, Compare::getId, firstId)
.last(" limit " + pageSize);
List<Compare> compareList = compareDao.getBaseMapper().selectList(lambdaQueryWrapper);
if (CollectionUtils.isEmpty(compareList)) {
log.info("firstId:{} loop is over", firstId);
return sumSize;
}
// 统计捞的总条数
sumSize += compareList.size();
compareList.forEach(compare -> {
// do something
log.info("compare:{}", JsonUtils.silentObject2String(compare));
});
return loopManualPage(compareList.get(compareList.size() - 1).getId(), pageSize, false, sumSize );
}
/**
* 按照id升序查询第一个符合条件的数据
*
* @return
*/
private Long queryFirstId() {
LambdaQueryWrapper<Compare> lambdaQueryWrapper = new QueryWrapper<Compare>().lambda();
// 在此补充其他查询条件,此处仅研究分页
lambdaQueryWrapper.select(Compare::getId).orderByAsc(Compare::getId).last("limit 1");
Compare compare = compareDao.getBaseMapper().selectOne(lambdaQueryWrapper);
return compare.getId();
}执行递归查询,我们得到如下结果:
2024-01-22 10:58:06.707 INFO 20128 --- [ main] com.github.OrderDaoTest : firstId:524377665847500 loop is over
2024-01-22 10:58:06.707 INFO 20128 --- [ main] com.github.OrderDaoTest : sumSize:160225我们执行以下sql语句:
select * from t_compare t order by t.id desc limit 1;得到结果如下:

可以看到loop is over对应的id就是524377665847500,总条数160225也是对应的,通过数据表明我们将数据全部通过分页的形式查询出来了。
我们再来看下我们分页时的sql对应的执行计划:
explain select * from t_compare t where t.id > 1 limit 1000;
可以看到我们的sql预计走索引,并且索引级别达到了较好的range级别,虽然目前rows看着有点多,但是当我们再执行以下操作时:
# 查询最后一页第一条
select * from t_compare t where t.id <= 524377665847500 order by t.id desc limit 1000;我们得到如下结果:

即最后一页的起始ID是:524377170406700
于是我们执行以下sql:
explain select * from t_compare t where t.id > 524377170406700 order by t.id asc limit 1000;
我们可以看到,按照我们的分页方式,查询索引不仅达到了range级别,并且越往后翻页越快,这就完完全全的解决了深分页问题。
那么我们再反观下直接使用limit分页,我们也来查询最后一页:
explain select * from t_compare t limit 160000,1000;
我们会发现走了全表扫描。当数据量达到百万级或者千万级,这个扫描行数将是灾难性的。
我们再来对比下手动分页和limit分页的耗时:
limit costTime:8620
manual costTime:4281可以看到数据量在十几万的级别下,limit分页耗时是8620毫秒,手动分页则是4281毫秒,效率直接提高百分之五十。分页效率提升十分明显。
分页进行中,数据条数减少
这里在研究如何加速分页查询时,突然想到一个问题,如果说我们一个线程中分页已经触发了,这个时候其他线程将我们预计要通过分页查询出来的数据删除了,那数据库是继续查询数据还是报错呢?
我们编写代码如下:
@Test
public void testDeleteOnPage() {
Page<Compare> page = new Page<>(1, 1000);
while (true) {
compareDao.page(page);
List<Compare> records = page.getRecords();
System.out.println(JsonUtils.silentObject2String(records));
if (CollectionUtils.isEmpty(records)) {
break;
}
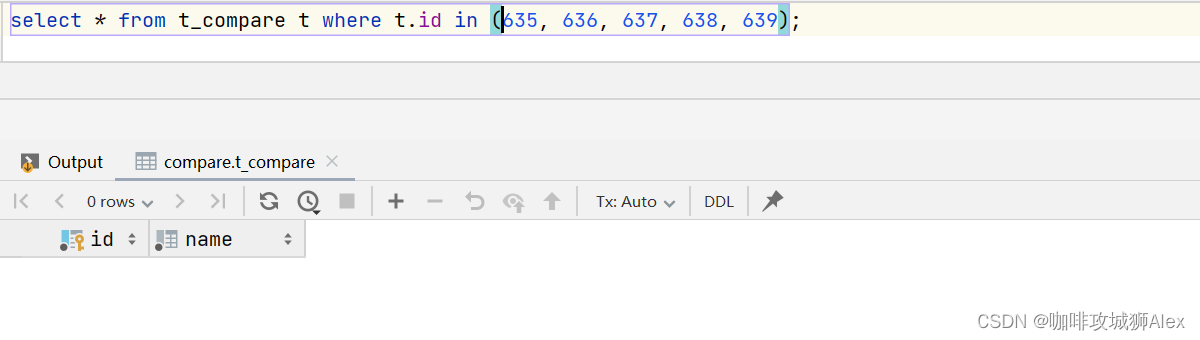
compareDao.removeBatchByIds(Arrays.asList(635, 636, 637, 638, 639));
page.setCurrent(page.getCurrent() + 1);
if (!page.hasNext()) {
break;
}
}
}我们在执行分页时,删除第二页中的635, 636, 637, 638, 639这五条数据,执行程序结果如下:
各位同学可以发现单元测试正常执行,并没有报错,查看日志并没有查询出来这五条数据,查询数据库也发现这五条数据已经被删除了。
分页进行中,数据条数增加
数据减少我们已经验证了,那如果数据增加呢,分页的后续永远有最后一页,那是不是就死循环了?
我们编写代码如下
@Test
public void testSaveOnPage() {
Page<Compare> page = new Page<>(1, 1000);
AtomicInteger atomicInteger = new AtomicInteger();
while (true) {
compareDao.page(page);
List<Compare> records = page.getRecords();
if (CollectionUtils.isEmpty(records)) {
break;
}
System.out.println(JsonUtils.silentObject2String(records));
new Thread(()->{
for (int i = 0; i < 100; i++) {
Compare compare = new Compare();
long id = System.nanoTime() + atomicInteger.getAndIncrement();
System.out.println("id:" + id);
compare.setId(id);
compare.setName("额外添加,分页永远结束不了");
compareDao.save(compare);
}
}).start();
page.setCurrent(page.getCurrent() + 1);
if (!page.hasNext()) {
break;
}
}
}执行后我们会发现程序并不是像我们预想的那样,它不仅把我们存量的数据分页查询出来,还把我们添加线程插入的数据也查询出来了,我们可以看下图:
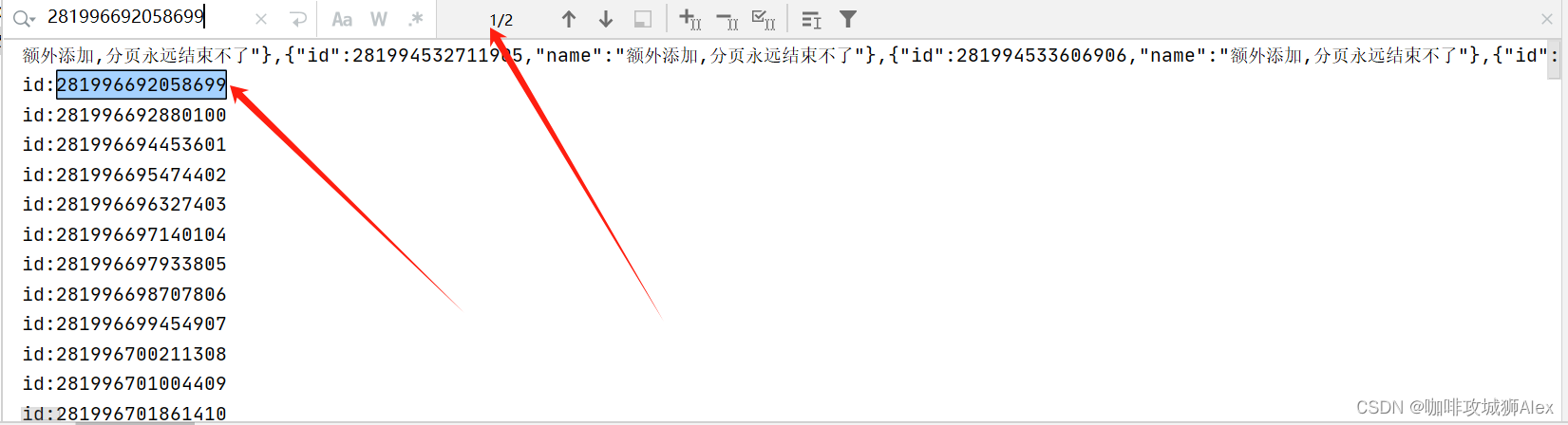
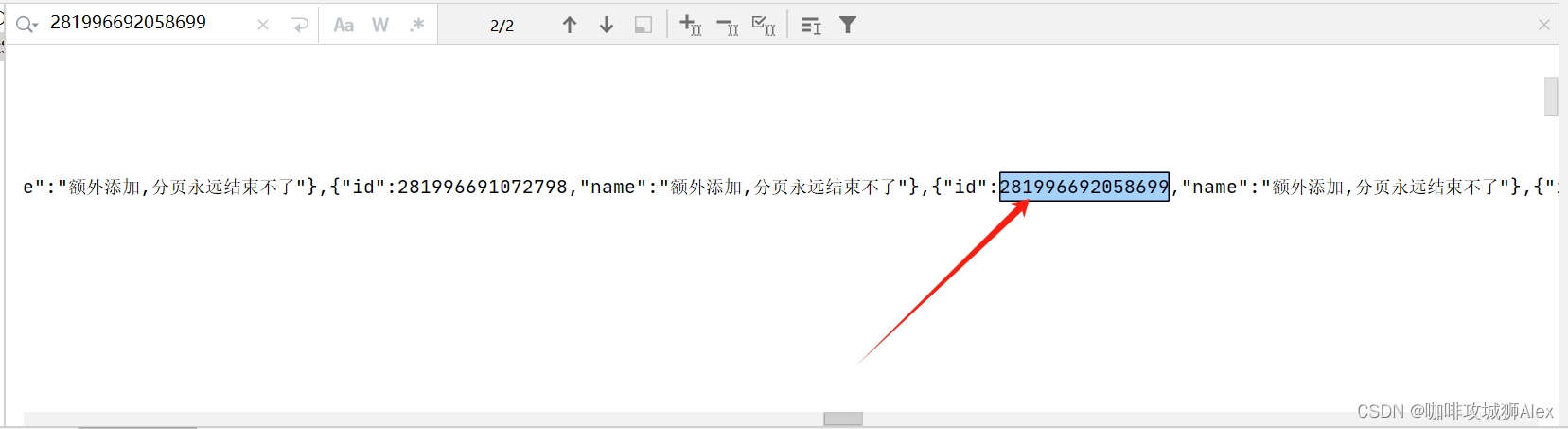
我们以这个生成的id:281996692058699为例,我们发现全局匹配了两次,一次是插入时输出的,还有紧接的一次查询获取到的。
我们小结一下,MySQL执行分页时,不管数据是增加还是减少,分页都会正常进行,数据减少,MySQL分页会自动跳过删除的数据,获取后续的数据,但是数据增加就会有一个很大的风险,就是如果分页过慢,慢于数据生成的速度,那MySQL分页永远不会结束,也就是会分页死循环,所以同学们一定要提高分页的速度。
MybatisPlus的分页
这里谈到MySQL分页时数据增加的问题,那MybatisPlus分页插件是如何做的呢?
这里我们在配置中开启MybatisPlus的日志打印:
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl我们执行分页查询后发现如下:
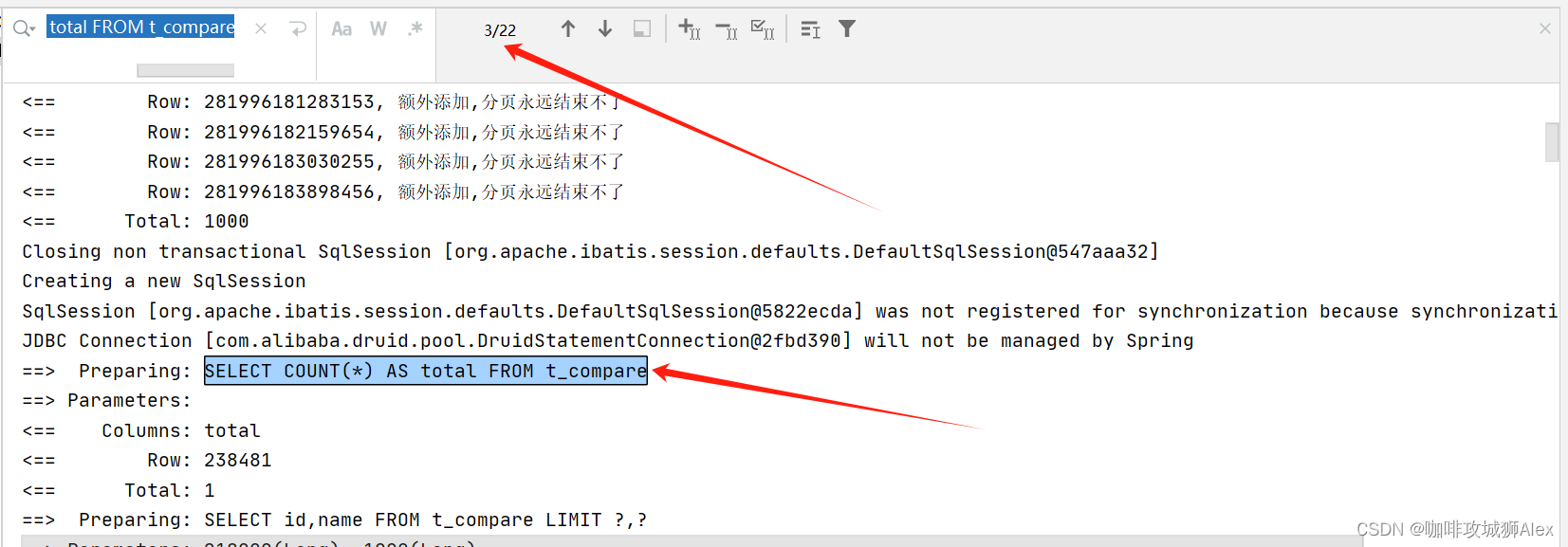
如图,发现MybatisPlus每次执行查询都执行了 SELECT COUNT(*) AS total FROM t_compare 语句以获得到最新的条数。
那如果有同学在分页中就是需要忽略新增的数据如何处理呢,MybatisPlus也早给咱们想好了,咱们在创建page对象的时候设置searchCount为false就可以了,那么MybatisPlus就不会再去统计了。那么自然page.hasNext()就失效了,这个需要注意。
page.setSearchCount(false);以上就是关于MySQL分页相关知识点的分享,如果大家有更好的优化MySQL分页的方式,或者说优化SQL的好点子。希望通过此文抛砖引玉,大家有好想法都抛出来,一起交流,一起进步。如果各位同学觉得对你有所帮助,请关注、点赞、评论、收藏来支持我,手头宽裕的话也可以赞赏来表达各位的认可,各位同学的支持是对我最大的鼓励。未来为大家带来更好的创作。
分享一句非常喜欢的话:把根牢牢扎深,再等春风一来,便会春暖花开。
版权声明:以上引用信息以及图片均来自网络公开信息,如有侵权,请留言或联系
504401503@qq.com,立马删除。

















 2316
2316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











