






1、数据集准备
微调大型语言模型(LLM)通常涉及指令微调,这是一种特定的数据准备和训练过程。在指令微调中,数据集由一系列包含指令、输入和输出的条目组成,例如:
在这个例子中,`instruction` 是给予模型的任务指令,明确告知模型需要完成的具体任务;`input` 是为了完成任务所需的用户提问或相关信息;而 `output` 则是模型应产生的预期回答。
我们的目标是训练模型,使其能够准确理解并遵循用户的指令。因此,在构建指令集时,必须针对特定的应用目标精心设计。例如,如果我们的目标是创建一个能够模仿特定对话风格的个性化LLM,我们就需要构建与之相应的指令集。
以使用开源的甄嬛传对话数据集为例,如果我们希望模型能够模拟甄嬛的对话风格,我们可以构造如下形式的指令:

在此示例中,我们省略了 `input` 字段,因为模型的回答是基于预设的角色背景知识,而非用户的直接提问。通过这种方式,我们可以训练模型学习并模仿特定角色的语言风格和对话模式,从而在实际应用中提供更加个性化和情景化的交互体验。
2、导入依赖包
3、读取数据集
输出:
4、处理数据集
1)定义分词器
2)消息格式查看
输出:
3)数据处理函数
4)数据处理
输出:

5)解码查看input_ids
输出:
6)解码查看labels
输出:
5、定义模型
输出如下:
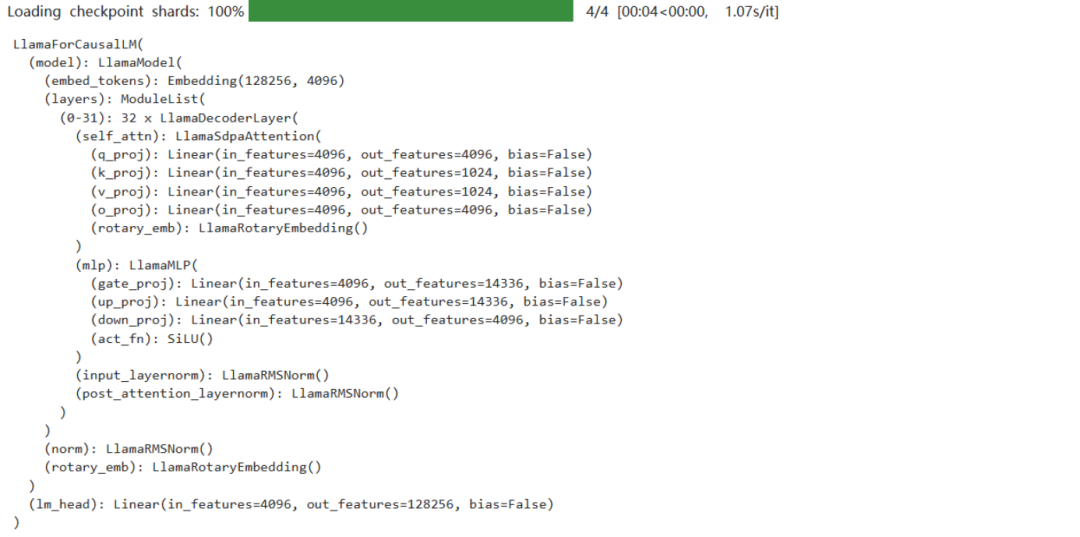
查看模型加载的精度
输出:
6、Lora配置
LoraConfig这个类中可以设置很多参数,但主要的参数如下
- task_type:模型类型
- target_modules:需要训练的模型层的名字,主要就是attention部分的层,不同的模型对应的层的名字不同,可以传入数组,也可以字符串,也可以正则表达式。
- r:lora的秩,
- 具体可以看Lora原理lora_alpha:Lora alaph,具体作用参见 Lora 原理
Lora的缩放是啥?不是r(秩),这个缩放就是lora_alpha/r, 在这个LoraConfig中缩放就是4倍。
输出:
加载微调配置
输出:
查看可训练的参数
输出:
7、配置训练参数
TrainingArguments这个类的源码也介绍了每个参数的具体作用,当然大家可以来自行探索,这里就简单说几个常用的。
- output_dir:模型的输出路径
- per_device_train_batch_size:顾名思义 batch_size
- gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些。
- logging_steps:多少步,输出一次log
- num_train_epochs:顾名思义 epoch
- gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads()
8、开始Trainer训练
训练完成如下:

9、合并模型
将训练后的权重文件合并到基础模型中,产生新的模型文件
合并完成如下:

10、模型推理
推理结果输出:
文章最后
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









