








百川公司宣布,其最新研发的Baichuan-M1系列模型正式面世,包括国内首个全场景深度思考模型Baichuan-M1-preview与行业首个开源医疗增强大模型Baichuan-M1-14B,两款模型均展现了卓越的性能与创新的技术特点。
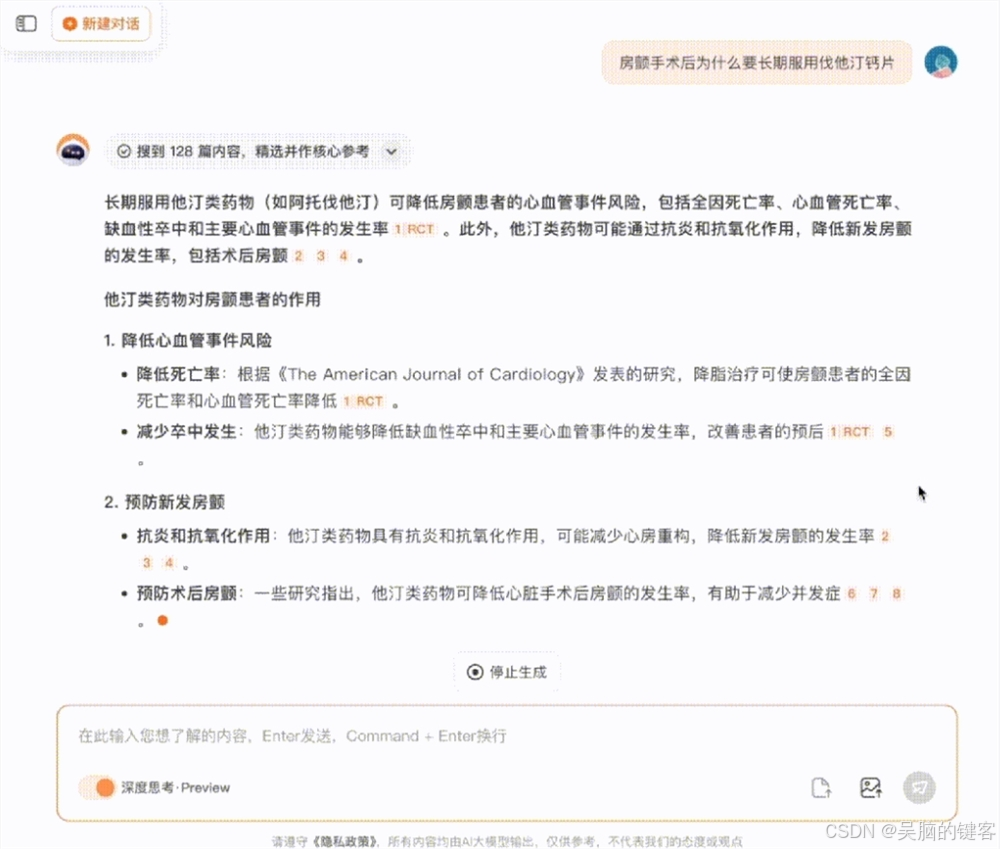
Baichuan-M1-preview作为国内唯一同时具备语言、视觉和搜索三大领域推理能力的模型,其表现尤为亮眼。在数学、代码等多个权威评测中,Baichuan-M1-preview超越了包括o1-preview在内的多个竞品,展现出强大的深度思考能力。更令人瞩目的是,该模型解锁了“医疗循证模式”,通过引入海量可靠的医学知识库,实现了从证据检索到深度推理的完整端到端服务,能够快速、精准地回答医疗临床、科研问题。这一模式的推出,不仅为医生提供了强大的辅助工具,也极大地提升了普通用户对医疗信息的理解和管理能力。
与此同时,Baichuan-M1-14B作为Baichuan-M1-preview的小尺寸版本,其医疗能力同样不容小觑。该模型在多个权威医学知识和临床能力评测中,成绩超越了更大参数量的Qwen2.5-72B-Instruct,与o1-mini不相上下。百川公司为了提升Baichuan-M1-14B的医疗能力,进行了大量的数据收集、合成与模型训练工作,确保了模型能够学习到有价值且全面的医疗知识。
Baichuan-M1系列模型的发布,是百川公司在AI医疗领域的又一次重要突破。这两款模型不仅展现了百川公司在技术创新方面的实力,更为推动AI技术在医疗领域的广泛应用提供了有力支持。通过开源Baichuan-M1-14B,百川公司希望能够激发更多创新力量,共同推动中国医疗健康生态的持续进步,助力实现更公平、更高效的高质量医疗服务。
Baichuan-14B-M1
Baichuan-14B-M1 是百川智能从零开始开发的业界首个开源大语言模型,专门针对医疗场景进行了优化。 它不仅在通用能力方面表现出色,在医疗领域也有强大的性能。 在大多数通用基准评估中,它取得了与类似规模的模型相当的结果,而在医疗场景中,它的表现则超过了比它大五倍的模型。 以下是该模型的核心特点:
- 在 20 万亿字节的高质量医疗和通用数据上从头开始训练。
- 为 20 多个具有细粒度医疗专业知识的医疗科室提供专业建模。
- 引入创新模型架构,显著提高上下文理解能力和长序列任务性能。
- 提供 🤗 基础模型和 🤗 指导模型。
📊 基准结果
我们的评估涵盖了所有主流基准,在开源和闭源评估中都取得了优异的指标,展示了出色的医疗场景能力,同时保持了强大的一般性能。
| Category | Benchmark | Baichuan-M1-14B-Instruct | Qwen2.5-14B-Instruct | Qwen2.5-72B-Instruct | claude-3.5-sonnet-20241022 | gpt-4o |
|---|---|---|---|---|---|---|
| Average Score | 72.23 | 65.39 | 70.51 | 74.85 | 75.00 | |
| Clinical Practice | cmbclin | 77.40 | 71.51 | 75.36 | 78.37 | 75.36 |
| clinicalbench_diag | 70.90 | 68.85 | 72.23 | 75.00 | 73.05 | |
| clinicalbench_hos | 70.05 | 68.83 | 70.53 | 65.58 | 69.38 | |
| clinicalbench_treat | 56.38 | 55.03 | 57.30 | 64.03 | 59.35 | |
| rarearena_rdc | 81.80 | 66.40 | 76.20 | 89.60 | 88.40 | |
| rarearena_rds | 54.00 | 42.60 | 49.80 | 59.80 | 57.20 | |
| rarebench | 59.60 | 52.80 | 60.60 | 65.30 | 62.80 | |
| Exams | cmexam | 80.10 | 77.70 | 82.70 | 77.50 | 78.00 |
| Pediatric Qualification Exam | 78.48 | 74.68 | 84.81 | 76.58 | 78.48 | |
| Internal Medicine Qualification Exam | 83.42 | 86.10 | 87.17 | 87.70 | 83.42 | |
| General Practice Qualification Exam | 87.07 | 88.44 | 88.44 | 81.63 | 84.35 | |
| USMLE | 78.00 | 67.20 | 76.70 | 85.90 | 87.10 | |
| medbullets | 66.88 | 54.22 | 64.29 | 72.40 | 75.97 | |
| mediq | 83.40 | 66.80 | 79.90 | 88.80 | 90.20 | |
| nejmqa | 49.75 | 45.69 | 50.76 | 69.54 | 54.31 | |
| pubmedqa | 75.20 | 76.40 | 75.60 | 77.00 | 77.60 | |
| redisqa | 74.50 | 69.70 | 75.00 | 83.20 | 82.80 | |
| Basic Capabilities | mednli_dis | 80.40 | 68.90 | 74.90 | 58.30 | 79.80 |
| medcalc | 56.00 | 31.40 | 37.90 | 52.60 | 49.00 | |
| MMLU-anatomy | 80.00 | 67.41 | 71.11 | 86.67 | 91.11 | |
| MMLU-virology | 54.82 | 56.02 | 53.01 | 54.22 | 57.23 | |
| MMLU-genetics | 91.00 | 82.00 | 87.00 | 97.00 | 95.00 | |
代码
我们建议使用最新版本的 Transformers 库(至少 4.47.0)。 下面的代码片段演示了如何使用 Baichuan-M1-14B-Instruct 模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 1. Load pre-trained model and tokenizer
model_name = "baichuan-inc/Baichuan-M1-14B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name,trust_remote_code=True,torch_dtype = torch.bfloat16).cuda()
# 2. Input prompt text
prompt = "May I ask you some questions about medical knowledge?"
# 3. Encode the input text for the model
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 4. Generate text
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 5. Decode the generated text
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 6. Output the result
print("Generated text:")
print(response)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









