







阿里巴巴刚刚发布了迄今为止最先进的人工智能模型 Qwen2.5-Max。 它不像 DeepSeek R1 或 OpenAI 的 o1 那样是一个推理模型,这意味着你无法看到它的思考过程。 最好把 Qwen2.5-Max 看作是一个通用模型,是 GPT-4o、Claude 3.5 Sonnet 或 DeepSeek V3 的竞争对手。 在这篇博客中,我将介绍 Qwen2.5-Max 是什么、它是如何开发的、它在竞争中的优势以及你如何获取它。
什么是 Qwen2.5-Max?

Qwen2.5-Max 是阿里巴巴迄今为止最强大的人工智能模型,旨在与 GPT-4o、Claude 3.5 Sonnet 和 DeepSeek V3 等顶级模型竞争。
阿里巴巴是中国最大的科技公司之一,以其电子商务平台而闻名,但它在云计算和人工智能领域也拥有强大的实力。 从较小的开放式模型到大规模的专有系统,"Qwen "系列都是阿里巴巴更广泛的人工智能生态系统的一部分。

与之前的一些Qwen模型不同,Qwen2.5-Max没有开源,这意味着它的权重不对外公开。
Qwen2.5-Max以20万亿个代币为基础进行训练,拥有庞大的知识库和强大的通用人工智能能力。 不过,它并不像 DeepSeek R1 或 OpenAI 的 o1 那样是一个推理模型,这意味着它不会明确显示自己的思考过程。 不过,考虑到阿里巴巴正在进行的人工智能扩张,我们可能会在未来看到一个专门的推理模型–有可能是 Qwen 3。
Qwen2.5-Max 的工作原理是什么?
Qwen2.5-Max 采用专家混合(MoE)架构,DeepSeek V3 也采用了这种技术。 这种方法既能扩大模型规模,又能控制计算成本。 让我们以一种易于理解的方式来分解其关键组成部分。
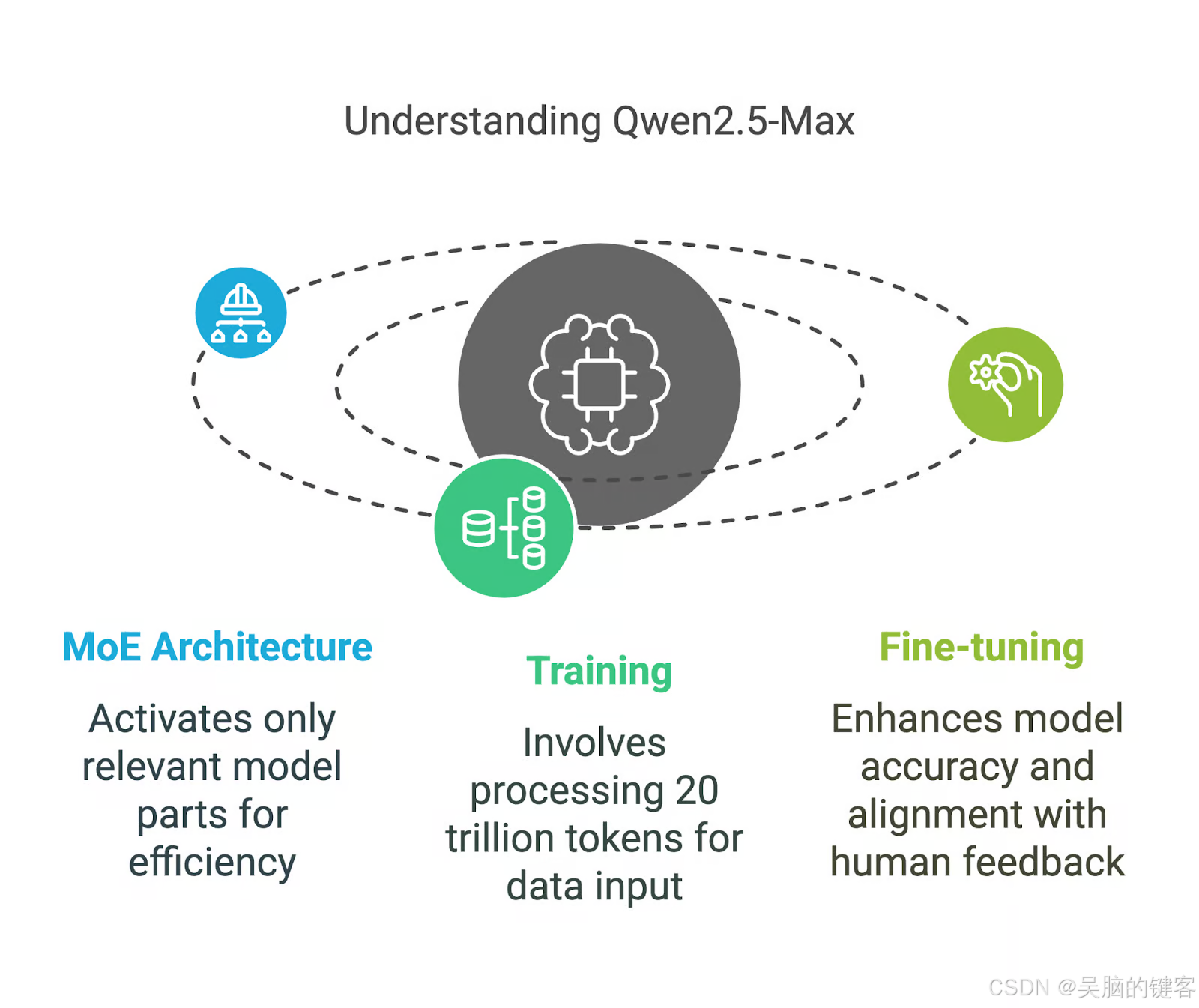
Mixture-of-Experts (MoE) 架构
传统的人工智能模型会在每项任务中使用所有参数,与之不同的是,Qwen2.5-Max 和 DeepSeek V3 等 MoE 模型在任何时候都只激活模型中最相关的部分。
你可以把它想象成一个由专家组成的团队:如果你提出一个复杂的物理问题,只有物理方面的专家才会做出回应,而团队的其他成员则会保持沉默。 这种选择性激活意味着模型可以更高效地处理大规模处理,而不需要极高的计算能力。
这种方法使 Qwen2.5-Max 不仅功能强大,而且具有可扩展性,使其能够与 GPT-4o 和 Claude 3.5 Sonnet 等密集模型竞争,同时更节省资源–密集模型是指对每个输入激活所有参数的模型。
训练和微调
Qwen2.5-Max 在 20 万亿个词库上进行了训练,涵盖了大量的主题、语言和语境。
从 20 万亿个代币的角度来看,这大约相当于 15 万亿个单词–数量之大难以估量。 相比之下,乔治-奥威尔的《1984》包含约 89,000 个单词,这意味着 Qwen2.5-Max 已经在相当于 1.68 亿本《1984》的基础上进行了训练。
然而,仅靠原始训练数据并不能保证建立高质量的人工智能模型,因此阿里巴巴进一步完善了训练数据:
- 监督微调(SFT): 人工标注员提供高质量的回复,以指导模型生成更准确、更有用的输出结果。
- 从人类反馈中强化学习(RLHF): 对模型进行训练,使其答案与人类偏好保持一致,确保回答更自然、更贴近情境。
Qwen2.5-Max 基准测试
Qwen2.5-Max 已与其他领先的人工智能模型进行了测试,以衡量其在各种任务中的能力。 这些基准测试同时评估了指导模型(针对聊天和编码等任务进行了微调)和基础模型(微调前的原始基础)。 了解这一区别有助于明确这些数字的真正含义。
指令模型基准
指导模型针对实际应用进行了微调,包括对话、编码和常识任务。 这里将 Qwen2.5-Max 与 GPT-4o、Claude 3.5 Sonnet、Llama 3.1 405B 和 DeepSeek V3 等模型进行比较。
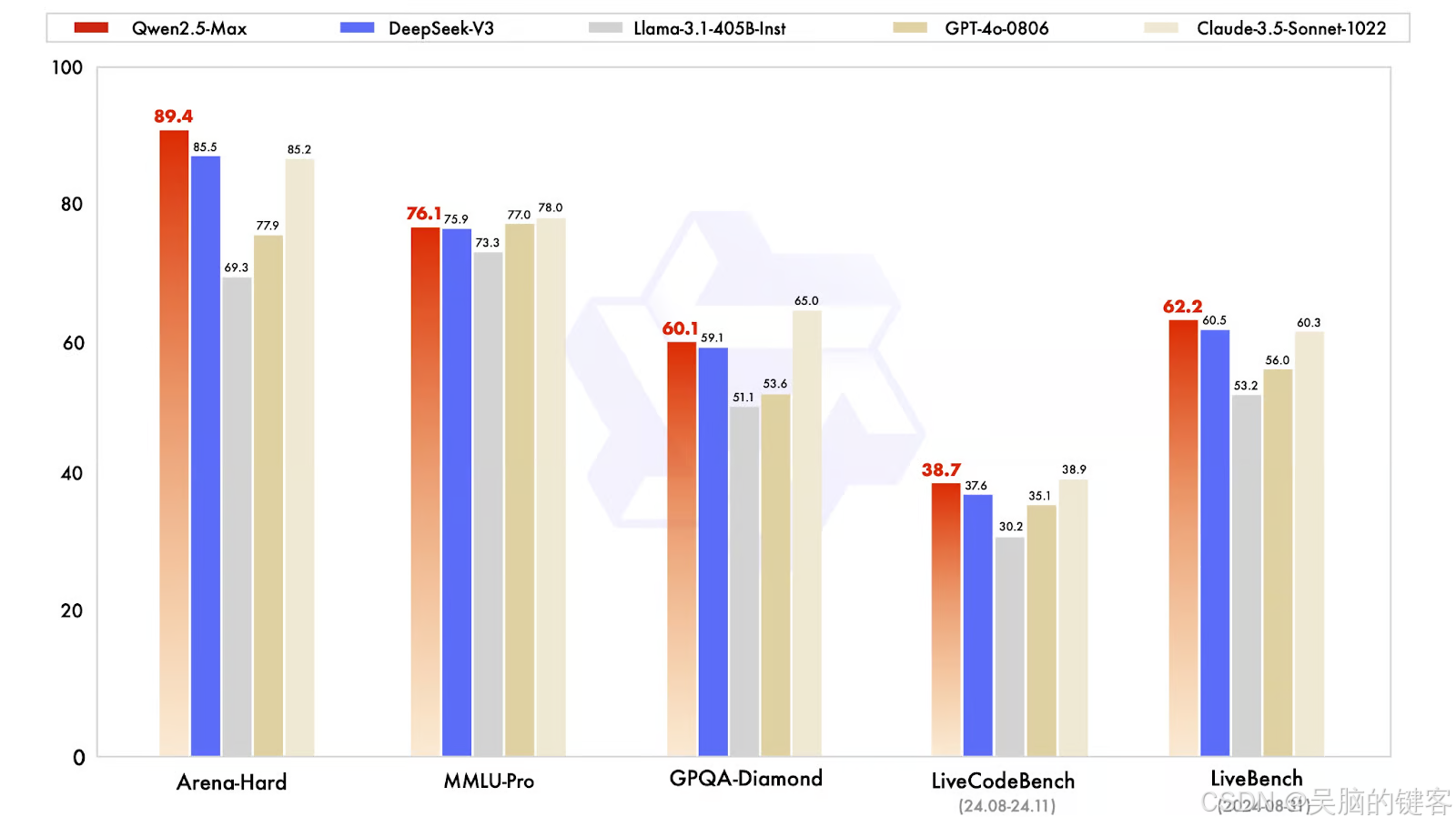
指令模型的比较。 来源:QwenLM
让我们快速分析一下结果:
- Arena-Hard(偏好基准): Qwen2.5-Max 得分为 89.4,领先于 DeepSeek V3(85.5)和 Claude 3.5 Sonnet(85.2)。 该基准近似于人类对人工智能生成的反应的偏好。
- MMLU-Pro(知识与推理): Qwen2.5-Max 得分为 76.1,略高于 DeepSeek V3(75.9),但也略低于领先者 Claude 3.5 Sonnet(78.0)和亚军 GPT-4o(77.0)。
- GPQA-Diamond(常识问答): Qwen2.5-Max的得分为60.1,超过了DeepSeek V3(59.1),而Claude 3.5 Sonnet则以65.0领先。
- LiveCodeBench(编码能力):Qwen2.5-Max的得分为38.7,超过了DeepSeek V3(59.1): Qwen2.5-Max的编码能力为38.7,与DeepSeek V3(37.6)大致相当,但落后于Claude 3.5 Sonnet(38.9)。
- LiveBench(整体能力): Qwen2.5-Max 以 62.2 分遥遥领先,超过了 DeepSeek V3(60.5 分)和 Claude 3.5 Sonnet(60.3 分),这表明 Qwen2.5-Max 在实际人工智能任务中具有广泛的能力。
总之,Qwen2.5-Max 被证明是一个全面的人工智能模型,在基于偏好的任务和一般人工智能能力方面表现出色,同时还保持了竞争知识和编码能力。
基本模型基准
由于 GPT-4o 和 Claude 3.5 Sonnet 是没有公开基础版本的专有模型,因此比较对象仅限于 Qwen2.5-Max、DeepSeek V3、LLaMA 3.1-405B 和 Qwen 2.5-72B 等开放重量模型。 这样就能更清楚地了解 Qwen2.5-Max 与领先的大型开放模型之间的差距。
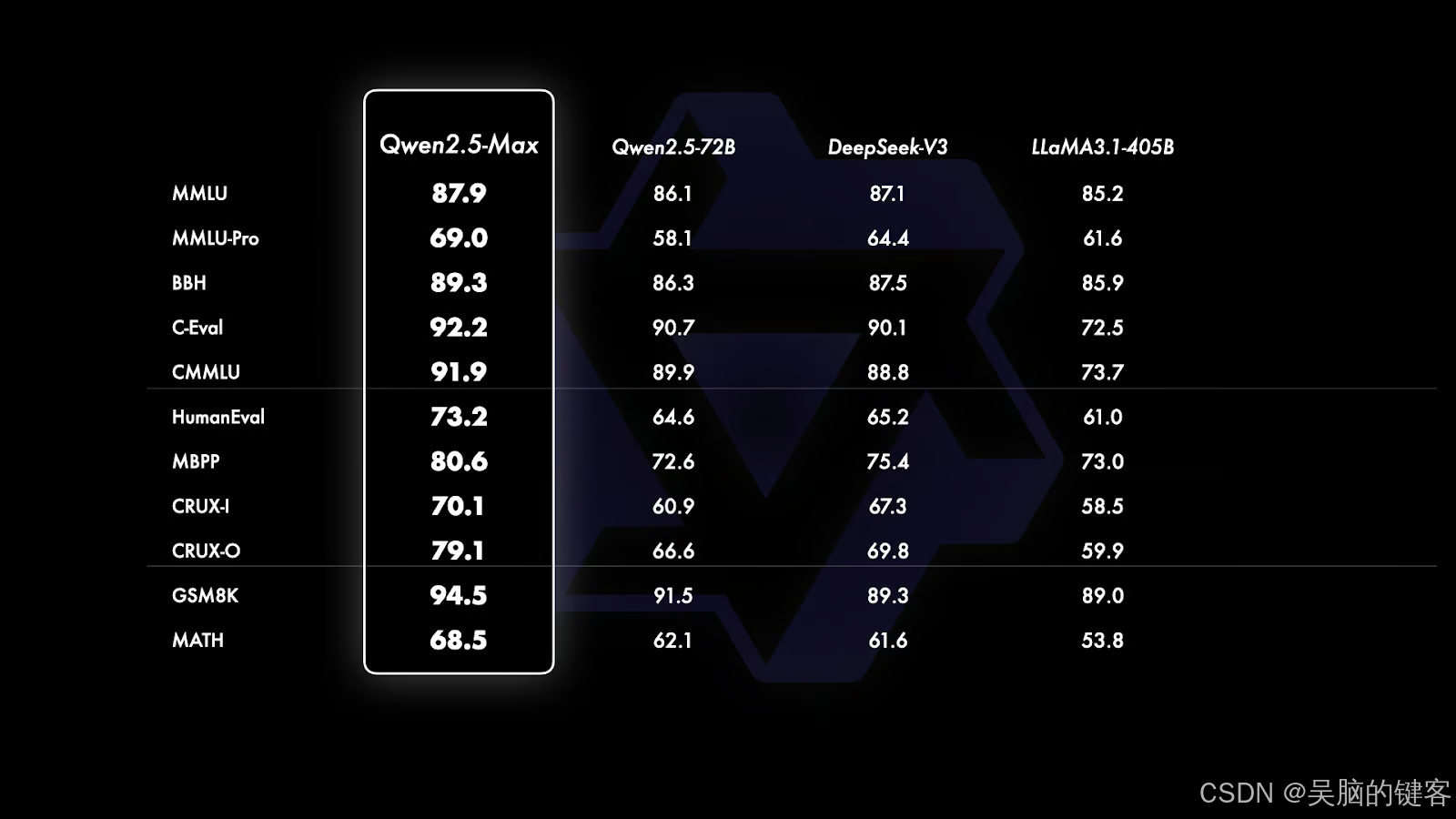
基本模型对比。 来源:QwenLM
如果仔细观察上图,它根据评估基准的类型分为三个部分:
- 常识和语言理解(MMLU、MMLU-Pro、BBH、C-Eval、CMMU): Qwen2.5-Max 在这一类别的所有基准中均处于领先地位,在 MMLU 和 C-Eval 中的得分分别为 87.9 和 92.2,超过了 DeepSeek V3 和 Llama 3.1-405B。 这些基准主要考察知识的广度和深度,以及在推理中应用这些知识的能力。
- 编码和问题解决(HumanEval、MBPP、CRUX-I、CRUX-O): Qwen2.5-Max 在所有基准测试中均遥遥领先,在编码相关任务中表现出色,HumanEval 得分为 73.2,MBPP 得分为 80.6,略高于 DeepSeek V3,大幅领先于 Llama 3.1-405B。 这些基准衡量的是编码技能、解决问题的能力,以及遵循指令或独立生成解决方案的能力。
- 数学问题解决(GSM8K、MATH): 数学推理是 Qwen2.5-Max 的强项之一,在 GSM8K 中获得 94.5 分,远远超过 DeepSeek V3(89.3 分)和 Llama 3.1-405B (89.0 分)。 不过,在侧重于解决更复杂问题的数学计算中,Qwen2.5-Max 的得分为 68.5,略微超过竞争对手,但仍有改进空间。
如何访问 Qwen2.5-Max 访问
Qwen2.5-Max 非常简单,无需任何复杂设置即可免费试用。
Qwen Chat
体验Qwen2.5-Max的最快方法是通过Qwen Chat平台。 这是一个基于网络的界面,允许您直接在浏览器中与模型互动,就像在浏览器中使用 ChatGPT 一样。
要使用 Qwen2.5-Max 模型,请单击模型下拉菜单并选择 Qwen2.5-Max:

通过阿里云访问 API
对于开发者来说,Qwen2.5-Max 可通过阿里云 Model Studio API 访问。 要使用它,你需要注册一个阿里云账户,激活 Model Studio 服务,并生成一个 API 密钥。 由于 API 遵循 OpenAI 的格式,因此如果你已经熟悉 OpenAI 模型,整合起来应该很简单。 有关详细设置说明,请访问 Qwen2.5-Max 官方博客。
结论
Qwen2.5-Max 是阿里巴巴目前能力最强的人工智能模型,可与 GPT-4o、Claude 3.5 Sonnet 和 DeepSeek V3 等顶级模型竞争。 与之前的一些 Qwen 模型不同,Qwen2.5-Max 没有开源,但可通过 Qwen Chat 或阿里云上的 API 访问进行测试。 鉴于阿里巴巴在人工智能领域的持续投资,未来出现一个以推理为重点的模型也不足为奇——有可能是 Qwen 3。


















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









