







智谱AI最新开源文生图模型CogView4正式亮相,CogView4不仅在参数数量上达到了6亿,还全面支持中文输入和中文文本到图像的生成,被称其为“首个能在画面中生成汉字的开源模型”。

CogView4以支持中英双语提示词输入为核心亮点,尤其擅长理解和遵循复杂的中文指令,成为中文内容创作者的福音。作为首个能在图像中生成汉字的开源文生图模型,它填补了开源领域的一大空白。此外,该模型支持生成任意宽高图片,并能处理任意长度的提示词输入,展现出极高的灵活性。
CogView4的双语能力得益于技术架构的全面升级。其文本编码器升级为GLM-4,支持中英双语输入,彻底打破了此前开源模型仅支持英文的局限。据悉,该模型使用中英双语图文对进行训练,确保其在中文语境下的生成质量。
在文本处理上,CogView4摒弃了传统的固定长度设计,采用动态文本长度方案。当平均描述文本为200-300个词元时,相较于固定512词元的传统方案,冗余减少约50%,训练效率提升5%-30%。这一创新不仅优化了计算资源,也让模型能更高效地处理长短不一的提示词。
CogView4支持生成任意分辨率的图像,背后是多项技术突破。模型采用混合分辨率训练,结合二维旋转位置编码和内插位置表示,适应不同尺寸需求。此外,其基于Flow-matching扩散模型和参数化线性动态噪声规划,进一步提升了生成图像的质量和多样性。
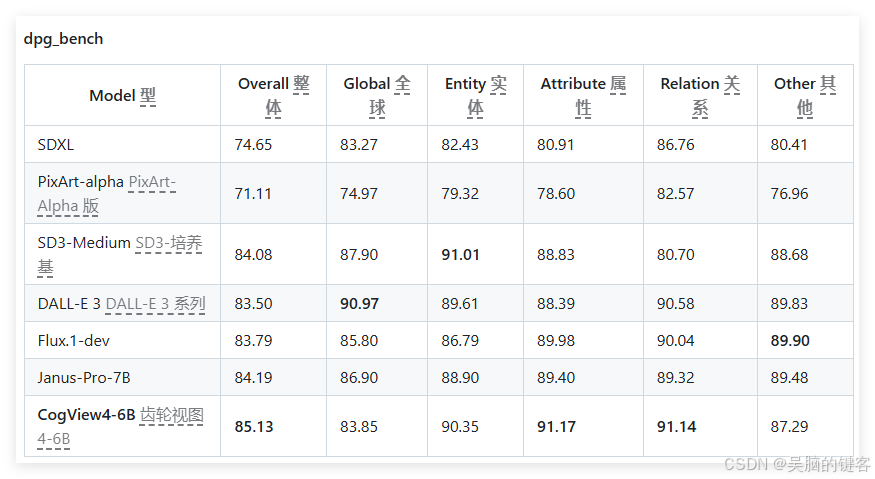
CogView4的训练流程分为多个阶段:从基础分辨率训练开始,到泛分辨率适配,再到高质量数据微调,最后通过人类偏好对齐优化输出。这一过程保留了Share-param DiT架构,同时为不同模态引入独立的自适应层归一化,确保模型在多种任务中的稳定性与一致性。
项目:https://github.com/THUDM/CogView4
快速上手
首先,确保从源代码中安装了 diffusers 。
pip install git+https://github.com/huggingface/diffusers.git
cd diffusers
pip install -e .
然后,运行以下代码:
from diffusers import CogView4Pipeline
pipe = CogView4Pipeline.from_pretrained("THUDM/CogView4-6B", torch_dtype=torch.bfloat16)
# Open it for reduce GPU memory usage
pipe.enable_model_cpu_offload()
# pipe.vae.enable_slicing()
# pipe.vae.enable_tiling()
prompt = "A vibrant cherry red sports car sits proudly under the gleaming sun, its polished exterior smooth and flawless, casting a mirror-like reflection. The car features a low, aerodynamic body, angular headlights that gaze forward like predatory eyes, and a set of black, high-gloss racing rims that contrast starkly with the red. A subtle hint of chrome embellishes the grille and exhaust, while the tinted windows suggest a luxurious and private interior. The scene conveys a sense of speed and elegance, the car appearing as if it's about to burst into a sprint along a coastal road, with the ocean's azure waves crashing in the background."
image = pipe(
prompt=prompt,
guidance_scale=3.5,
num_images_per_prompt=1,
num_inference_steps=50,
width=1024,
height=1024,
generator=torch.Generator().manual_seed(random.randint(0, 65536))
).images[0]
image.save("cogview4.png")
这样 4090 就能运行了

像CogVideo一样支持AO量化,但是不支持BnB。建议内存准备到32GB,现在的 Diffusers 模型都比较大,以后可能会是趋势。
import torch
from diffusers import CogView4Pipeline, CogView4Transformer2DModel, TorchAoConfig
import random
quant_config = TorchAoConfig("int8wo")
transformer = CogView4Transformer2DModel.from_pretrained(
"THUDM/CogView4-6B",
subfolder="transformer",
quantization_config=quant_config,
torch_dtype=torch.bfloat16,
)
pipe = CogView4Pipeline.from_pretrained("THUDM/CogView4-6B",
transformer=transformer,
torch_dtype=torch.bfloat16,
)
# Open it for reduce GPU memory usage
pipe.enable_model_cpu_offload()
# pipe.vae.enable_slicing()
# pipe.vae.enable_tiling()
prompt = "A vibrant cherry red sports car sits proudly under the gleaming sun, its polished exterior smooth and flawless, casting a mirror-like reflection. The car features a low, aerodynamic body, angular headlights that gaze forward like predatory eyes, and a set of black, high-gloss racing rims that contrast starkly with the red. A subtle hint of chrome embellishes the grille and exhaust, while the tinted windows suggest a luxurious and private interior. The scene conveys a sense of speed and elegance, the car appearing as if it's about to burst into a sprint along a coastal road, with the ocean's azure waves crashing in the background."
image = pipe(
prompt=prompt,
guidance_scale=3.5,
num_images_per_prompt=1,
num_inference_steps=50,
width=1024,
height=1024,
generator=torch.Generator().manual_seed(random.randint(0, 65536))
).images[0]
image.save("cogview4_2.png")




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









