








我们介绍了 BAGEL,这是一个开源的多模态基础模型,拥有 7B 活动参数(共 14B 参数),在大规模交错多模态数据上经过训练。在标准多模态理解排行榜上,BAGEL 的表现优于 Qwen2.5-VL 和 InternVL-2.5 等当前顶级开源 VLM,其文本到图像的质量可与 SD3 等强大的专业生成器相媲美。此外,BAGEL 在经典图像编辑场景中的质量结果也优于领先的开源模型。更重要的是,它扩展到了自由形式的视觉操作、多视图合成和世界导航,这些功能构成了 "世界建模 "任务,超出了以往图像编辑模型的范围。
该仓库托管了BAGEL的模型权重。有关安装、使用说明和更多文档,请访问我们的GitHub仓库。

🧠 方法
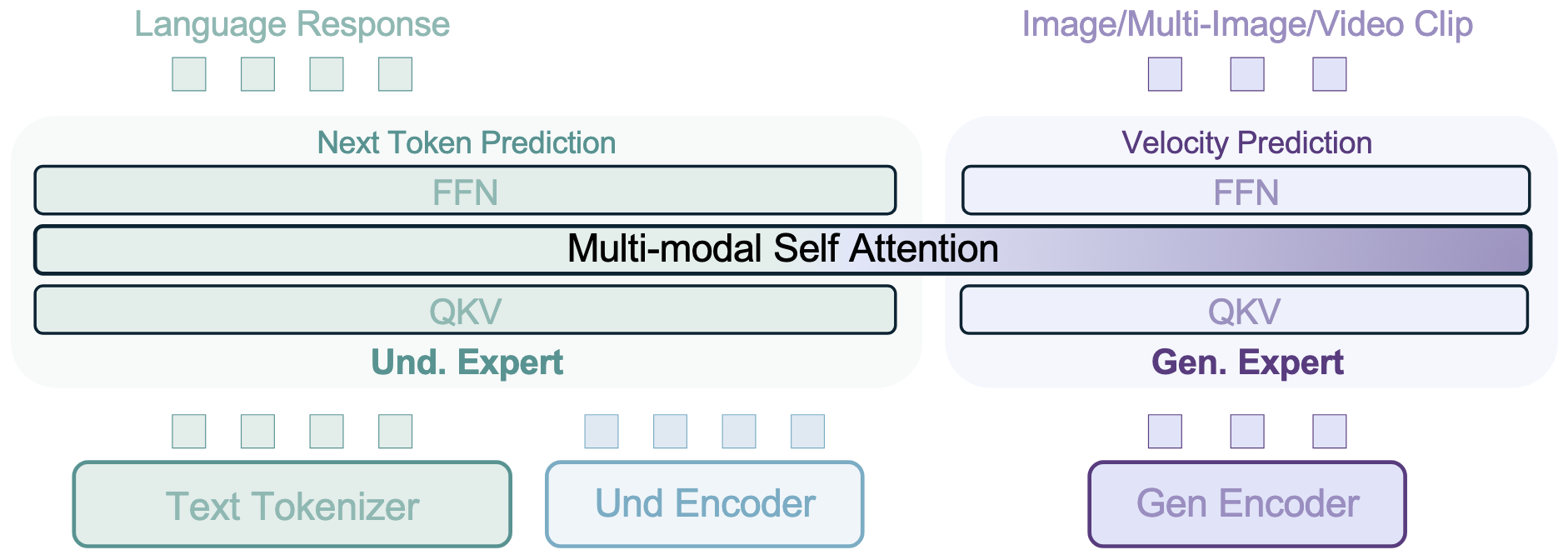
BAGEL采用混合专家Transformer架构(MoT),以最大化模型从丰富多样的多模态信息中学习的能力。基于相同的容量最大化原则,它利用两个独立的编码器来捕捉图像的像素级和语义级特征。总体框架遵循"下一组令牌预测"范式,模型通过预测下一组语言或视觉令牌作为压缩目标进行训练。
BAGEL通过在跨越语言、图像、视频和网络数据的数万亿交错多模态令牌上进行预训练、持续训练和监督微调,扩展了MoT的能力。它在标准理解和生成基准测试中超越了开源模型,并展现出先进的上下文多模态能力,如自由形式图像编辑、未来帧预测、3D操作、世界导航和顺序推理。
🌱 涌现特性
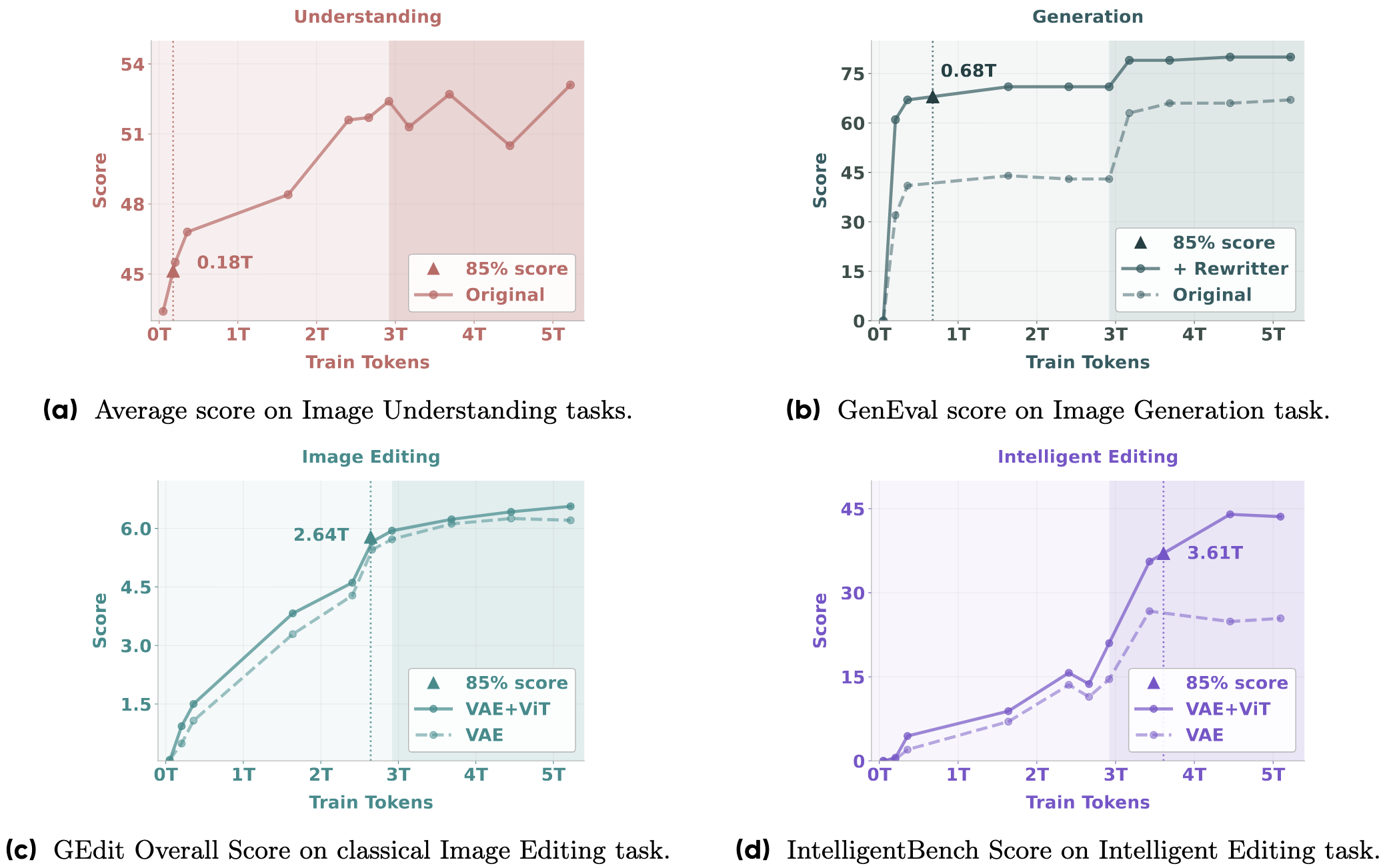
随着我们使用更多多模态标记对BAGEL进行预训练规模扩展,观察到在理解、生成和编辑任务上均取得持续性能提升。不同能力会在不同训练阶段涌现——多模态理解和生成能力较早出现,随后是基础编辑能力,而复杂智能编辑能力则较晚显现。这种阶段性发展表明存在涌现模式,高级多模态推理能力建立在完善的基础技能之上。消融实验进一步证明,结合VAE和ViT特征能显著提升智能编辑性能,这既凸显了视觉语义上下文对实现复杂多模态推理的重要性,也为高级能力涌现机制提供了佐证。
📊 基准测试
1. Visual Understanding
| Model | MME ↑ | MMBench ↑ | MMMU ↑ | MM-Vet ↑ | MathVista ↑ |
|---|---|---|---|---|---|
| Janus-Pro-7B | - | 79.2 | 41.0 | 50.0 | – |
| Qwen2.5-VL-7B | 2347 | 83.5 | 58.6 | 67.1 | 68.2 |
| BAGEL | 2388 | 85.0 | 55.3 | 67.2 | 73.1 |
2. Text-to-Image Generation · GenEval
| Model | Overall ↑ |
|---|---|
| FLUX-1-dev | 0.82 |
| SD3-Medium | 0.74 |
| Janus-Pro-7B | 0.80 |
| BAGEL | 0.88 |
3. Image Editing
| Model | GEdit-Bench-EN (SC) ↑ | GEdit-Bench-EN (PQ) ↑ | GEdit-Bench-EN (O) ↑ | IntelligentBench ↑ |
|---|---|---|---|---|
| Step1X-Edit | 7.09 | 6.76 | 6.70 | 14.9 |
| Gemini-2-exp. | 6.73 | 6.61 | 6.32 | 57.6 |
| BAGEL | 7.36 | 6.83 | 6.52 | 44.0 |
| BAGEL+CoT | – | – | – | 55.3 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









