







1. 简介
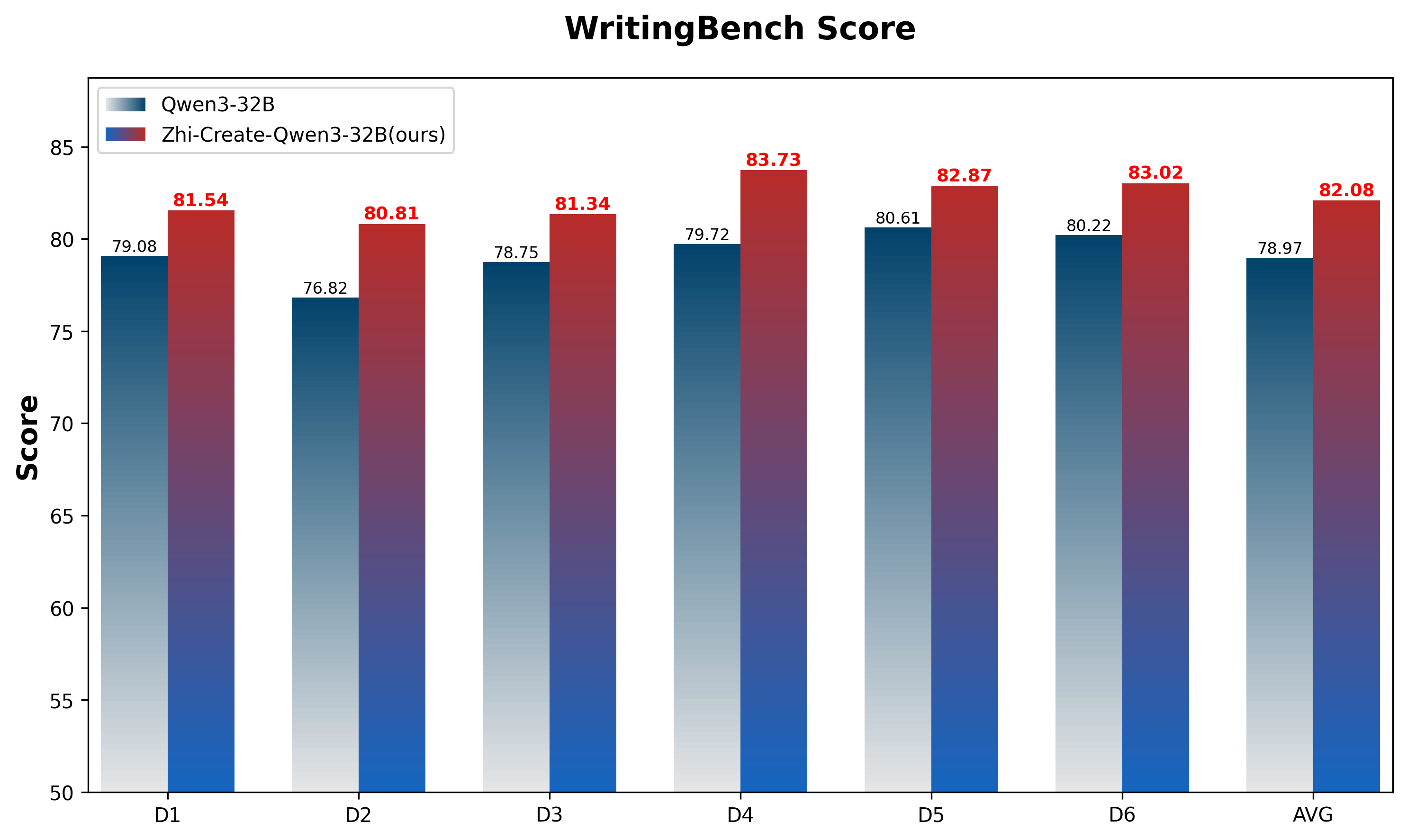
Zhi-Create-Qwen3-32B 是基于Qwen/Qwen3-32B微调的模型,重点增强了创意写作能力。通过精心优化,该模型在创意写作表现上展现出显著提升。使用WritingBench进行评估时,模型获得了82.08分,较基础版Qwen3-32B模型的78.97分有明显进步。
此外,为保持模型在通用知识、推理等方面的能力,我们通过混合通用知识、数学、代码等多种数据类型进行了细粒度数据配比实验。最终评估结果显示,模型的通用能力保持稳定,与基础模型相比未出现明显下降。
2. 训练流程
数据
模型的训练语料包含三大核心数据来源:经过严格筛选的开源数据集、人工合成的思维链推理语料以及知乎精选问答对。
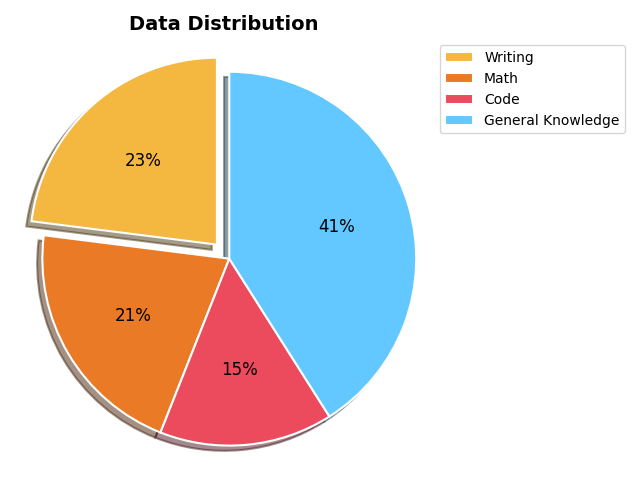
为实现最佳领域覆盖,我们通过数据混合优化实验精心平衡了各类数据集的配比。这些数据集包括Dolphin-r1、Congliu/Chinese-DeepSeek-R1-Distill-data-110k、a-m-team/AM-DeepSeek-R1-0528-Distilled,以及知乎平台的高质量内容。所有数据集均通过奖励模型(RM)过滤流程完成全面质量把控。为确保模型的基础知识与推理能力,创意写作类数据约占训练数据的23%,其余部分由数学、代码和基础通识类数据构成。训练数据中的思维链(CoT)推理组件是使用deepseek-ai/DeepSeek-R1-0528等同类模型合成的。
具体数据分布如下图所示:
训练方法
监督微调(SFT):我们采用课程学习策略进行监督微调。这种系统性方法在保持核心能力、避免灾难性遗忘的同时,通过融合多领域数据来持续增强创意写作能力。采用多阶段渐进迭代法,筛选前几轮训练不足的样本,并按推理复杂度与上下文长度分级,从而逐步提升训练样本难度,实现模型能力的阶梯式增强。
直接偏好优化(DPO):结合RAFT(奖励排序微调)方法,通过规则系统与大模型评判相结合的方式识别正负样本,构建DPO偏好样本对。该方法有效改善模型中英混杂编码、不良重复等问题,同时提升推理能力。
3. 评估结果
我们使用WritingBench(一个评估大语言模型写作能力的综合框架)对我们的模型进行了评估。Zhi-Create-Qwen3-32B模型获得了82.08分(使用Claude Sonnet 3.7作为评估法官),在创意写作表现上展现出显著提升。相比基础版Qwen3-32B模型78.97分的表现,这是一个重大改进。
下图展示了六个不同领域的性能对比:
4. 本地运行指南
智创千问3-32B可适配多种硬件配置,包括80GB显存GPU及单张H20/A800/H800显卡。为降低部署门槛,我们同步提供量化版本:FP8量化模型(Zhi-Create-Qwen3-32B-FP8)支持双RTX 4090运行,Q4_K_M量化版本可部署于单张RTX 4090显卡。
Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
MODEL_NAME = "Zhihu-ai/Zhi-Create-Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map="auto",
trust_remote_code=True
).eval()
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
# model.generation_config = GenerationConfig.from_pretrained(MODEL_NAME, trust_remote_code=True)
generate_configs = {
"temperature": 0.6,
"do_sample": True,
"top_p": 0.95,
"max_new_tokens": 4096
}
prompt = "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
**generate_configs
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
vllm
例如,你可以轻松地使用vLLM启动一个服务
# install vllm
pip install vllm>=0.6.4.post1
# huggingface model id
vllm serve Zhihu-ai/Zhi-Create-Qwen3-32B --served-model-name Zhi-Create-Qwen3-32B --port 8000
# local path
vllm serve /path/to/model --served-model-name Zhi-Create-Qwen3-32B --port 8000
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Zhi-Create-Qwen3-32B",
"prompt": "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章",
"max_tokens": 4096,
"temperature": 0.6,
"top_p": 0.95
}'
SGLang
你也可以使用 SGLang 轻松启动一个服务
# install SGLang
pip install "sglang[all]>=0.4.5" --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer-python
# huggingface model id
python -m sglang.launch_server --model-path Zhihu-ai/Zhi-Create-Qwen3-32B --served-model-name Zhi-Create-Qwen3-32B --port 8000
# local path
python -m sglang.launch_server --model-path /path/to/model --served-model-name Zhi-Create-Qwen3-32B --port 8000
# send request
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Zhi-Create-Qwen3-32B",
"prompt": "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章",
"max_tokens": 4096,
"temperature": 0.6,
"top_p": 0.95
}'
# Alternative: Using OpenAI API
from openai import OpenAI
openai_api_key = "empty"
openai_api_base = "http://127.0.0.1:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base
)
def get_answer(messages):
response = client.chat.completions.create(
messages=messages,
model="Zhi-Create-Qwen3-32B",
max_tokens=4096,
temperature=0.3,
top_p=0.95,
stream=True,
extra_body = {"chat_template_kwargs": {"enable_thinking": True}}
)
answer = ""
reasoning_content_all = ""
for each in response:
each_content = each.choices[0].delta.content
if hasattr(each.choices[0].delta, "content"):
each_content = each.choices[0].delta.content
else:
each_content = None
if hasattr(each.choices[0].delta, "reasoning_content"):
reasoning_content = each.choices[0].delta.reasoning_content
else:
reasoning_content = None
if each_content is not None:
answer += each_content
print(each_content, end="", flush=True)
if reasoning_content is not None:
reasoning_content_all += reasoning_content
print(reasoning_content, end="", flush=True)
return answer, reasoning_content_all
prompt = "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章"
messages = [
{"role": "user", "content": prompt}
]
answer, reasoning_content_all = get_answer(messages)
ollama
您可以通过此链接下载ollama
- 量化版本: Q4_K_M
ollama run zhihu/zhi-create-qwen3-32b
- bf16版本
ollama run zhihu/zhi-create-qwen3-32b:bf16
5. 使用建议
为了获得最佳性能,我们建议将temperature参数设置在0.5-0.7之间(推荐0.6),并将top-p设为0.95,以平衡创造性和连贯性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









