







百度飞桨paddlepaddle深度学习7日打卡 总结及学后感
这几日很少去看学校的课程,终于完成了百度飞桨paddlepaddle深度学习7日打卡,也算是有所收获。
AI学习之路,道阻且长。永远相信:路漫漫其修远兮,吾将上下而求所。
Day1-Python基础练习
作业1:1、输出 9*9 乘法口诀表(注意格式);2、查找特定名称文件,遍历"Day1-homework”目录下文件;找到文件名包含“2020”的文件;将文件名保存到数组result中;按照序号、文件名分行打印输出。注意:提交作业时要有代码执行输出结果。
第一天的任务比较简单,打印乘法口诀表以及文件的搜索,这对于有基本python知识的同学来说,还是比较容易完成的。贴出部分关键代码:
#打印乘法口诀表
def table():
str = '\n'
print(str.join(['\t'.join(['%s*%s=%s' % (j, i, i * j) for j in range(1, i + 1)]) for i in range(1, 10)]))
#递归搜索文件
def findfiles(path):
if filename in os.path.split(path)[1]:
result.append(os.path.relpath(path))
if os.path.isfile(path):
return
for dire in os.listdir(path):
findfiles(os.path.join(path,dire))
在这里,使用递归遍历文件夹,方便快捷。
Day2-《青春有你2》选手信息爬取
作业2:1.请在代码中提示位置,补充代码,完成《青春有你2》选手图片爬取,将爬取图片进行保存,保证代码正常运行 2.打印爬取的所有图片的绝对路径,以及爬取的图片总数,此部分已经给出代码。请在提交前,一定要保证有打印结果。
第二天的任务是爬虫获取百度百科-青春有你2的各位小姐姐们的照片,感觉一下就上了难度,特别是对于我这种小白来说,感觉无从下手,之前虽然也爬过其他网站的信息,但是这是我第一次爬虫百度,老师也说,爬虫无固定套路可言,必须要检查和分析网页源代码,这次的任务需要爬两层才能将图片爬下来。首先是爬第一层,根据已获取的每个选手的百科网页url,鼠标右键-检查,找到summary-pic,这个标签里面的内容即对应选手的图集,下面以安崎为例
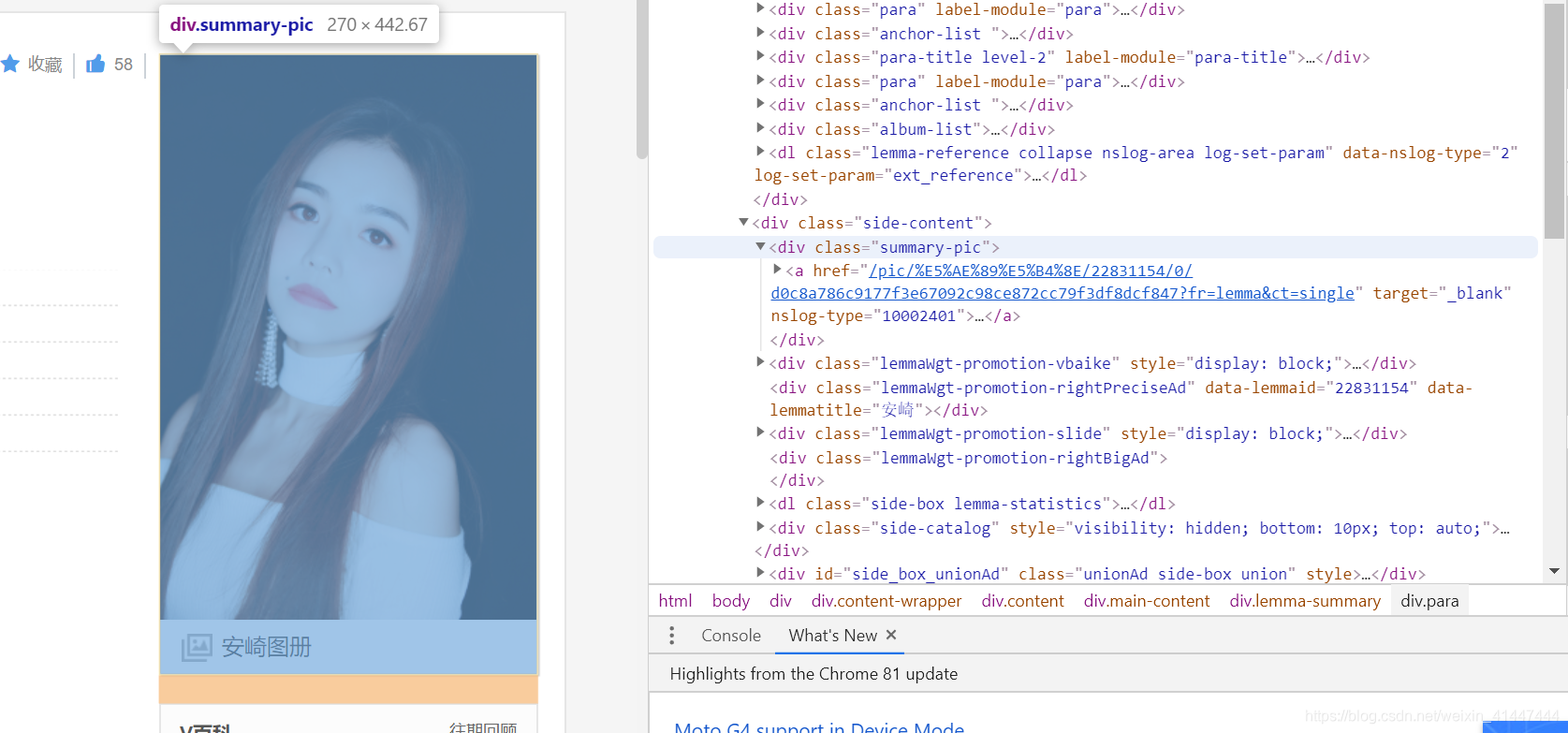
经过检查源码,发现了标签所在位置,a href所对应的东西即是我们要寻找的内容,得到了这个内容,在与https://baike.baidu.com进行拼接,就进入了爬虫第一层。
#爬虫第一层
response = requests.get(link, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
tables = soup.find_all('div', {
'class': 'summary-pic'})
经过第一层的爬虫,我们进入到了选手的图集,此时还需要进行第二层的爬虫,与第一次爬虫的方法一样,还是继续检查源码,找到pic-list标签
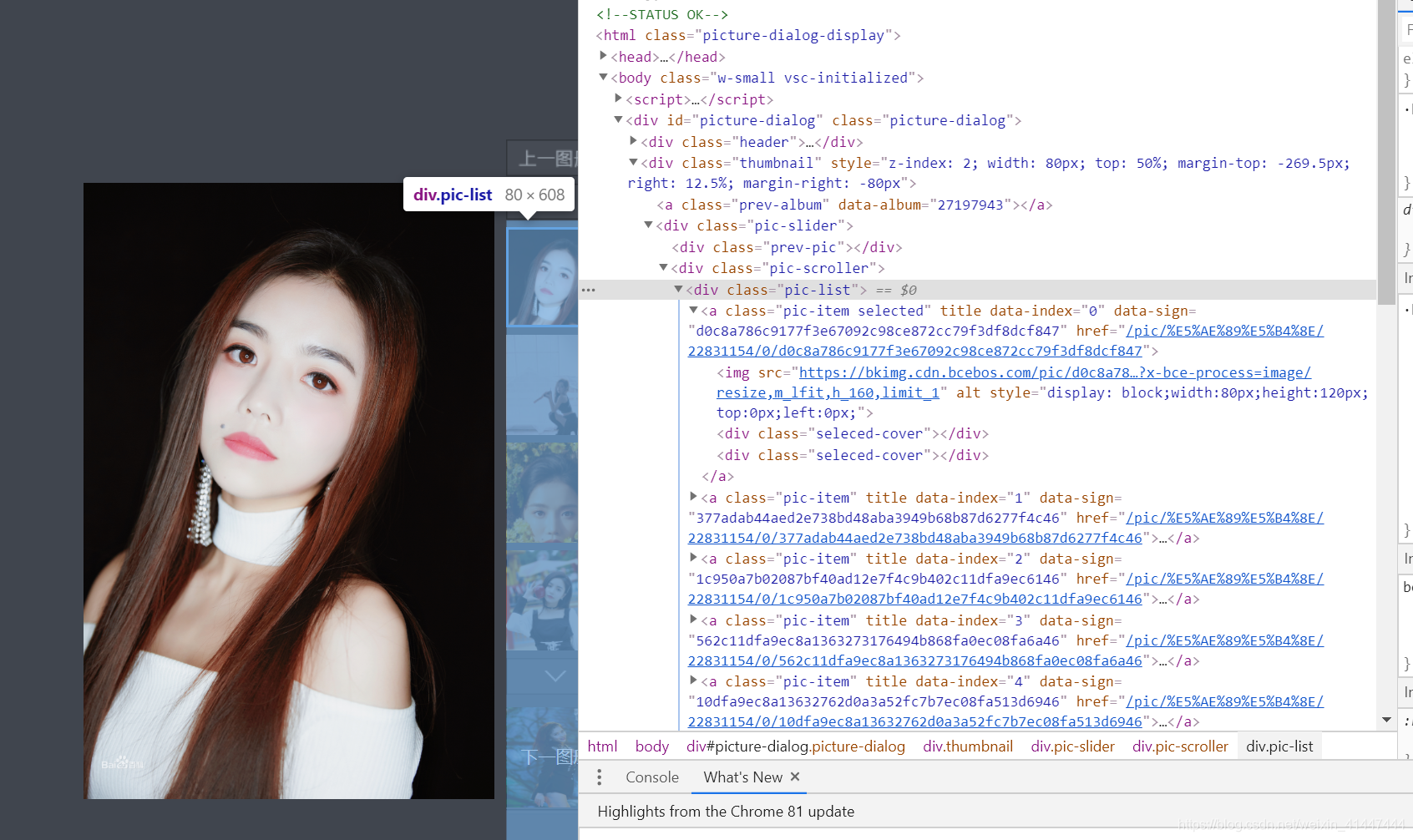
里面的img所对应的即是我们想要的,然后与上一步的地址进行拼接,这就是最终找到的选手的url了
#爬虫第二层
aHref = table.a['href']
album_url = "https://baike.baidu.com" + aHref
response = requests.get(album_url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
pic_list_div = soup.find('div', {
'class': 'pic-list'})
albumTmages = pic_list_div.find_all('img')
接下来就是对所有选手的link及img进行遍历,这就找到了所有选手的图片了。附上爬虫完整代码
#爬虫第二层
aHref = table.a['href']
def crawl_pic_urls():
'''
爬取每个选手的百度百科图片,并保存
'''
with open('work/' + today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
headers = {
'User-Agent': xxx
}
for star in json_array:
name = star['name']
link = star['link']
pic_urls = []
# !!!请在以下完成对每个选手图片的爬取,将所有图片url存储在一个列表pic_urls中!!!
response = requests.get(link, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
tables = soup.find_all('div', {
'class': 'summary-pic'})
for table in tables:
aHref = table.a['href']
album_url = "https://baike.baidu.com" + aHref
response = requests.get(album_url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
pic_list_div = soup.find('div', {
'class': 'pic-list'})
albumTmages = pic_list_div.find_all('img')
for album_image in albumTmages:
albumL_inmage_url = album_image["src"]
pic_urls.append(albumL_inmage_url)
Day3-《青春有你2》选手数据分析
作业3:对《青春有你2》对选手体重分布进行可视化,绘制饼状图
第三天的任务较为轻松,要求对《青春有你2》对选手体重分布进行可视化,绘制饼状图。这个不多说了,直接放代码吧
#绘制饼状图
import matplotlib.pyplot as plt
import pandas as pd
#显示matplotlib生成的图形
# %matplotlib inline
df = pd.read_json('data/data31557/20200422.json')
Weight_statistics  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









