









1. ID3决策树
1.1 基本概念
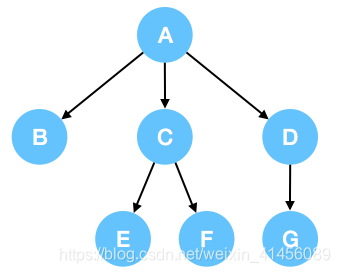
决策树指的是一颗多叉树,如图所示
1.2 作用
通俗来讲,决策树可以帮助我们降低选择的混乱程度。什么意思呢?举个例子来说,今天我们出不出去玩。在不考虑其他因素的情况下,出去玩和不出去玩的概率假设分别是50%,这意味着我们此时的大脑很混乱,对于出去玩这一问题,没有一颗坚定的心。但如果我们此时有A→B,A→C,A→D三种选择(晴天,阴天,雨天)。那么我们就可以将叶子节点B,D(假设上图没有节点G),当做结果,B为出去玩,D为不出去玩。而A→C表示阴天,我们还可以通过其他因素C→E和C→F来判断到底出不出去玩,假设C→E和C→F分别表示心情好和心情不好,那么E节点我们可以表示为出去玩,F节点可以表示为不出去玩。最后,我们得到如这样一棵树A→B(晴天),A→C(阴天),A→D(雨天),C→E(心情好),C→F(心情不好),叶子节点B,E(出去玩),叶子节点F,D(不出去玩)。
从以上例子可以明显看出,在通过决策树的选择后,我们可以对自己的目标有一个更为清晰的认知,因为我们的混乱程度下降了。说到这里,我们之前所讲的混乱程度,可以用熵来表示。那么接下来的问题是,在众多的因素中,如何选择一个因素,也就是特征,使我们的混乱程度下降的最大呢?换句话说,什么因素可以帮助我们把熵降的最多呢?我们将在1.3 熵这一小节讲解。
1.3 熵
1.3.1 基础概念
熵其实就是指在对一件事做抉择时的混乱程度。基本公式为:。常见的,我们可以以2,10,自然对数e为底。不过在决策树中,以哪个数为低并不重要,因为我们最终只比较结果的大小。
假设我们有如下两组数据:
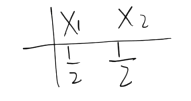 和
和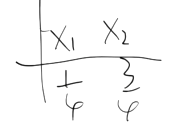
我们可以使用熵值的计算公式,分别计算两组数据熵的大小。如果不亲自计算,看官您是否能直观的感触哪组数据的熵值更大呢?
答案是第一组数据的熵值更大,还记得我们之前讲的,对一件事越不确定,熵值自然越大。
在本案例中,第一组数据X1和X2(出去玩和不出去玩)的概率都为1/2,我们无法确认到底选择X1还是X2。第二组数据中X1和X2(出去玩和不出去玩)的概率分别为1/4和3/4,很好,在我们山穷水尽时,我们可以更偏向3/4(不出去玩)这一选择,因为我更青睐于它,这意味着此时我们在选择时远没有第一组数据混乱。
接下来的问题是,如果我们现在知道的N个Y1~Yn事件(数据集中的标签Yi)的频率,且有X个事件,我们能否借助这些X帮助我们预测Y呢?决策树就是借鉴了这一点,结合了信息增益的思想,降低我们的混乱程度,便于我们做决策。在下一小节中,我们将讨论信息增益究竟是什么,为什么它可以帮助我们降低我们的混乱程度。
通俗的理解是,好比1.2中的例子,我们现在有标签Y(出去玩,不出去玩),现在需要借助一系列事件来帮助我们预测今天出不出去玩,于是就有了X(天气,心情等),根据X去预测Y。
1.3.2 信息增益
这一节,咱们来讨论信息增益到底是什么。其实,信息增益也被称为互信息,表示A事件和B事件的共同信息。
假设我们现在有A~E事件的熵“H(A)~ H(E)“,分别以一个圈表示,如图所示,那么,图中E和D的交集部分,就是互信息,也就是信息增益。(注,这里的圈代表的是事件的熵,因此和概率中的计算有所不同)。
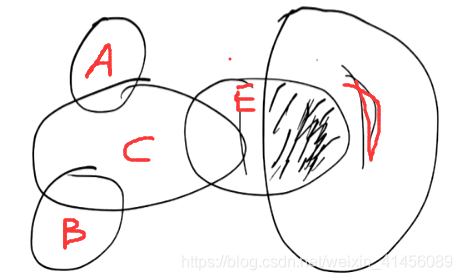
前面我们说过,熵值的大小代表着混乱程度的大小,这里用圆圈的面积表示,我们可以明显发现每个事件的混乱程度各有不同。假如我们现在想要预测E事件的发生(出去玩或不出去玩)。如何降低我们的混乱程度呢?
图中,与E事件有所关联的是C事件和D事件,如果我们知道了C事件和D事件,我们就可以减少我们的混乱程度了。以E和D为例,如果我们知道了D事件,也就意味着,我们得知了E事件和D事件有所交集的那片阴影信息。换句话说,E事件中的那片阴影信息(互信息或信息增益),我们已经知道了,E的熵值也就只剩下左边的非阴影部分。
决策树在做选择时,通常会选择信息增益最大的事件去分枝,放在本案例中,如果是预测E,决策树会优先挑选D事件当做分枝特征,再挑选C事件。因为D事件带给我们的信息增益更大,而其它事件(A,B)则对我们没有一丝帮助(信息增益为0)。
信息增益如何计算呢?请看下一小节。
1.3.3 信息增益的计算
如1.3.2中的图所示,每个事件的熵我们可以表示为H(A)~H(E)。那么,在得知D事件后,E事件的熵值,我们可以表示为H(E|D)。信息增益则可以表示为:H(E)- H(E|D)。
具体案例看官可以详细看看李航老师《统计学习方法》中决策树那一章节所举出的例子,本文就不详细阐述了。
1.4 分枝停止条件
- 小于信息增益的阈值
- 分裂到只剩一个样本时
- 最大树深
- 最小节点中所含样本数
- 最小叶节点数
1.6 缺点
- 无法处理回归问题
- 无法处理连续特征
- 在选择特征时,对于p(X1)~p(X2)=1/2和p(X1)~p(X6)=1/6这种情况,ID3决策树更倾向于选择后者,因为选择了后者后,我们的信息增益更大。以不重复的ID特征为例,每个ID的频率都是1/n,决策树一旦选择它,我们会获得最大的信息增益,但ID只是个标识,对于我们筛选毫无意义。
- 因多叉树的结构特点,空间成本大(计算机以二进制存储的特点,计算机对二叉树会更友好。)
- 计算涉及到对数计算,需要占用较大计算资源
- 容易过拟合
2. C4.5决策树
2.1 基本概念
C4.5与ID3的决策树唯一的差异是,C4.5将ID3使用的分枝条件信息增益转为信息增益率,这是对ID3决策树的一个改进。
2.2 基本公式
信息增益率 = 信息增益 / H(D)
在这里,信息增益指H(A|D)
2.2 相比于ID3的改进
2.2.1 针对某一特征中类别数量n过多的惩罚(同一特征内的不同类别频率均相等,即1/n)
前面我们提到,基于ID3的决策树会倾向于类别较多的某特征。
现在有天气特征(晴天,阴天,雨天,雷天,雪天,...,胡编的其它天),拥有n种天气,而非天气的其它特征中,拥有的类别数量小于n,假设不同特征中各类别的频率都相等(比如天气中各天气的频率都为1/n,某一其它特征中各类别的频率都为1/k(k<n)),决策树会更倾向于选择n>k的这一特征,因为经过选择后,我们获得的信息增益是最大的,看官们可以自行试验一下。
因此,为了平衡权重,找到真正最大的信息增益,我们可以使用信息增益 / n作为我们新的信息增益的计算公式,n越大,尽管信息增益也越大,但由于分母的惩罚,信息增益/n并不会发生偏差。
看到这里,看官们估计要疑惑了,我们之前提到的C4.5公式不是信息增益率 = 信息增益 / H(D)吗?且别急,我们会在下一小节中进行阐述。
2.2.2 针对不同特征中各类别频率不等的惩罚(同一特征内的不同类别频率不相等)
我们已经知道,通过信息增益 / n可以达到对ID3决策树倾向选择较大n的特征的惩罚。但是我们忽略了一个问题,如果不同特征的类别频率不等呢?这里可能不是很好理解,下面用例子说明一下:
假设我们现在有两个特征,两个特征都包含n个类别,其中一个特征内的不同类别频率都相等,但另一特征内的不同类别频率不全都相等,如下所示:
| 第一个特征 | ||||||
| 类别 | X1 | X2 | X3 | X4 | X5 | X6 |
| 频率 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
| 第二个特征 | ||||||
| 类别 | X1 | X2 | X3 | X4 | X5 | X6 |
| 频率 | 2/6 | 2/6 | 1/12 | 1/12 | 1/12 | 1/12 |
在这两个特征中,显然我们会更倾向于选择第二个特征。如果只是使用n作为惩罚的话,这里的频率就被忽略了,会显得两者的信息增益相同。这时,如果我们使用H(特征)作为分母对它进行惩罚,就可以在惩罚n的同时,惩罚频率。这里H(第一个特征)= 6 * 1/6 * log(1/6),另一个特征类推。显然H(第一个特征) > H(第二个特征),也就是说,在计算第一个特征的信息增益率时,它收到的惩罚比第二个特征更大。这就完美解决了ID3决策树的倾向缺陷。
2.2.3 针对ID3无法解决的连续特征
C4.5有专门处理连续特征的方法,即将连续特征离散化后再计算信息增益。
2.3 缺点
- 无法处理回归问题
- 因多叉树的结构特点,空间成本大(计算机以二进制存储的特点,计算机对二叉树会更友好。)
- 计算涉及到对数计算,需要占用较大计算资源
- 容易过拟合
3. cart决策树
3.1 基本概念
cart决策树与前两种决策树所不同的是,他并未使用基于熵的信息增益这个概念,而使用gini系数来计算。
3.2 基本公式
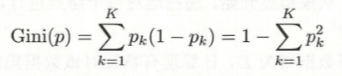
k表示某一特征中的一个第k个类别的频率,假设我们有十个样本,天气为其中一个特征。在这个特征中,包含三个类别(晴天,阴天,雨天),每个类别的数量分别是3,3,4,换句话说,每个类别的频率分别为3/10, 3/10, 4/10。
代入公式为:3/10*(1-3/10)+ 3/10*(1-3/10)+4/10*(1-4/10)
注:在cart决策树中,某一特征也可被分为两类,如晴天,非晴天,再继续使用gini系数计算。
3.3 优点
- 由于可以使用二叉树的形式分枝,计算机对其会更友好
- 由于去除了对数计算,计算资源得到改善
- 可以结合二叉树的特点,处理连续型特征和做回归
3.4 缺点
在ID3决策树和C4.5决策树中,cart决策树仍未解决的其它缺点。














 4624
4624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









