






Yolov5 VOC数据集训练与识别
环境部署
部署环境:miniconda3 + python3.8 + pytorch + cuda
安装Miniconda
选择python3的64位版本,即Miniconda3 Windows 64-bit
MiniConda下载链接 https://docs.conda.io/projects/miniconda/en/latest/
安装miniconda完成后,打开Anaconda Prompt,更换源,避免下载依赖时,速度太慢。

在Prompt中输入:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
创建虚拟环境(指定python版本为3.8.0):
conda create -n myenv python=3.8
进入虚拟环境:
conda activate myenv
检查安装的python版本:
python
此处安装的是python 3.9.0

退出虚拟环境
conda deactivate
下载Yolov5和预训练权重文件
Github下载Yolov5
百度云下载Yolov5
百度云下载Yolov5 链接:https://pan.baidu.com/s/1VuI5qqz62joV9Ax2a2QTLA?pwd=0j8r
提取码:0j8r
预训练权重文件yolov5s.pt
预训练权重文件yolov5s.pt 链接:https://pan.baidu.com/s/1k0Mz_XDnxrK7DCln6pqhQg?pwd=qzkq
提取码:qzkq
安装Yolov5 所需依赖
解压yolov5压缩包,打开anaconda prompt 进入之前创建的虚拟环境中,cd进入刚刚解压的yolov5目录下,该目录下有个requirements.txt文本
在prompt中输入

安装完成后查看已经安装的依赖包,输入:
pip list

注意安装的Pytorch分为CPU版本和GPU版本,如果要使用GPU版本还需要安装显卡对应的CUDA
安装CUDA
查看自己电脑的GPU最高支持什么版本,在CMD中输入如下指令:
-nvidia-smi
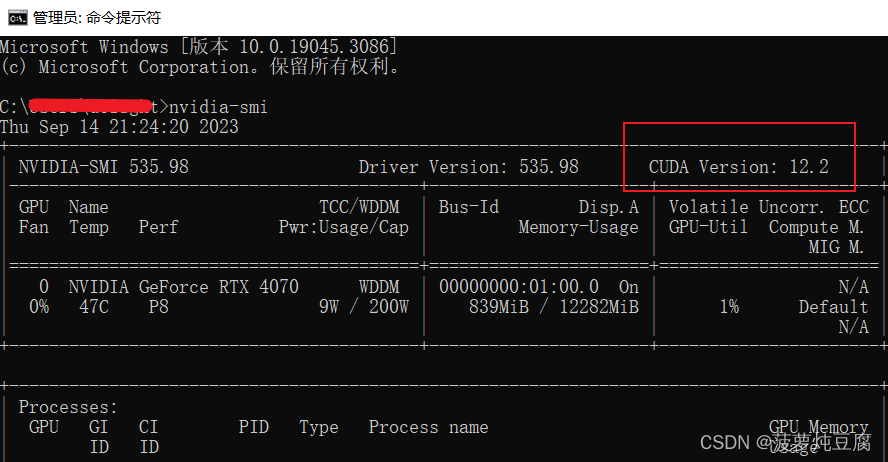
这里以我的GPU为例,RTX4070最高支持CUDA的版本为12.2,但是查资料发现40系显卡最低仅能支持CUDA 11.8.0的版本,而pytorch最高支持的CUDA版本为11.8.0。所以我在安装CUDA的时候选择了11.8.0的版本,pytoch则安装了能够支持CUDA11.8的版本。
安装完后,查看安装的CUDA版本是否正确,在CMD中输入:
nvcc -V

安装Pytorch
在Pytorch官网选择对应的版本

复制 Run this Command 中的指令,到前面我们创建并安装了Yolov5依赖的Anaconda 虚拟环境的Promot中,并执行 (如果安装太慢可以更换Anaconda的镜像源)

安装完成后,可以再次查看安装大的版本正不正确,可以输入pip list查看已安装的所有包
转换VOC数据集为YOLOv5可识别的数据集
VOC数据集
VOC数据集主要分为两个层级:
1 -> Annotations (存放标签的文件夹,里面每一个xml都存储这对应图像的标注信息)
2 -> Images (存放所有的训练图像数据)
我们创建一个叫做mydata的文件夹,在该文件夹下创建如下文件夹:

将VOC数据中的images图像丢进,上面的images文件夹中,将VOC数据集的Annotations文件丢进上面的xml文件夹中,并在mydata文件夹下创建一个py文件,将数据集进行划分:
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml->这里是上面存放原VOC Annotations标签文件的地方
parser.add_argument('--xml_path', default='xml', type=str, help='input xml label path')
#dataset->这里是刚创建,存放划分好训练集和验证集txt文件的存储地方。
parser.add_argument('--txt_path', default='dataset', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent =1.0
train_percent = 0.9
xml_file_path = opt.xml_path
txt_save_path = opt.txt_path
total_xml = os.listdir(xml_file_path)
if not os.path.exists(txt_save_path):
os.makedirs(txt_save_path)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval,tr)
file_trainval = open(txt_save_path + '/trainval.txt', 'w')
file_test = open(txt_save_path + '/test.txt', 'w')
file_train = open(txt_save_path + '/train.txt', 'w')
file_val = open(txt_save_path + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
执行上面的py代码后,会在dataset中得到如下txt文件,其中我们只划分了训练集、验证集和训练验证集,所有test文件里面为空(正常要有):

再次在dataset文件夹下创建一个py文件,代码如下:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["missing_hole"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('xml/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('dataset/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
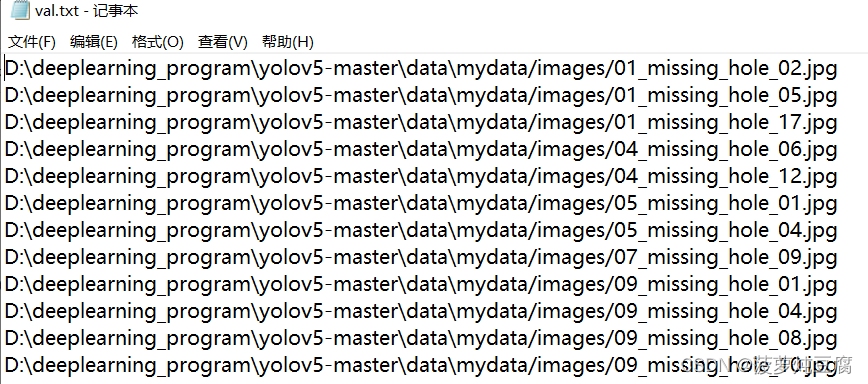
正常执行后,在mydata文件夹下会生成两个txt文件,里面存储着对应的训练图像的存储位置:
在data文件夹下创建一个叫mydata.yaml的文件,在里面配置对应的训练数据文件的地址和训练数据的类别:
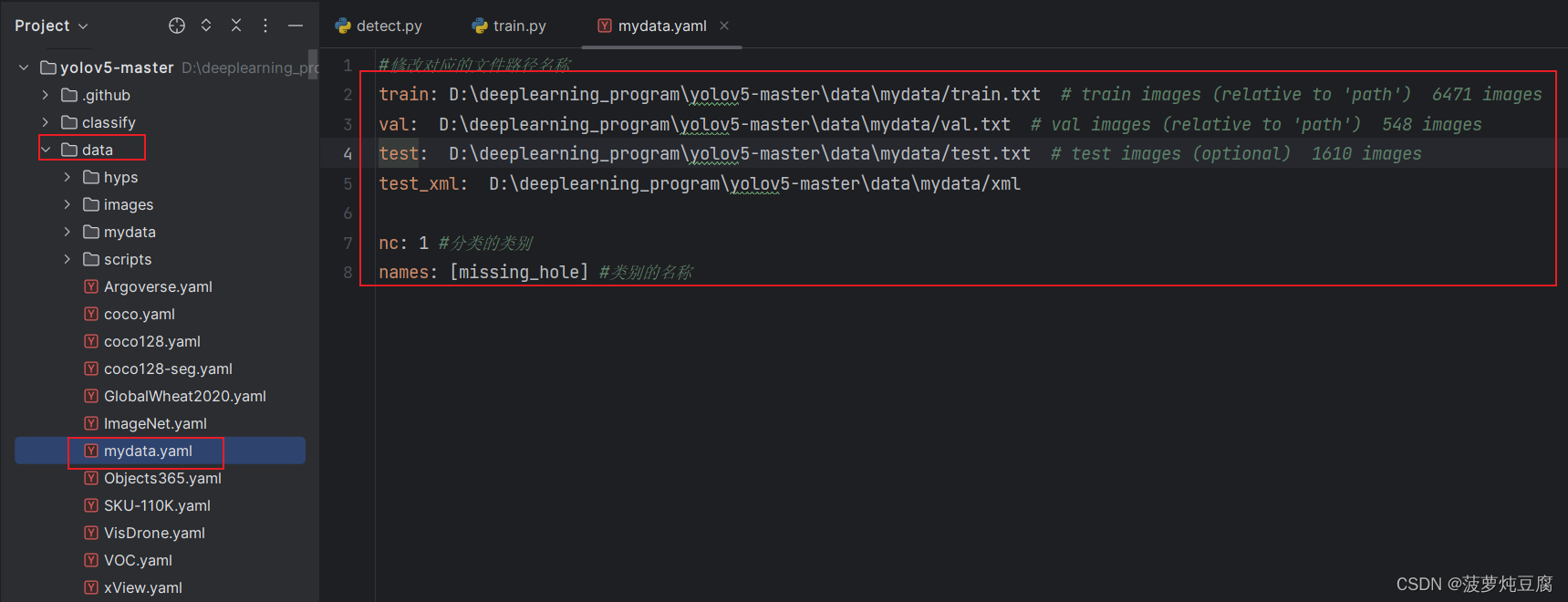
训练数据
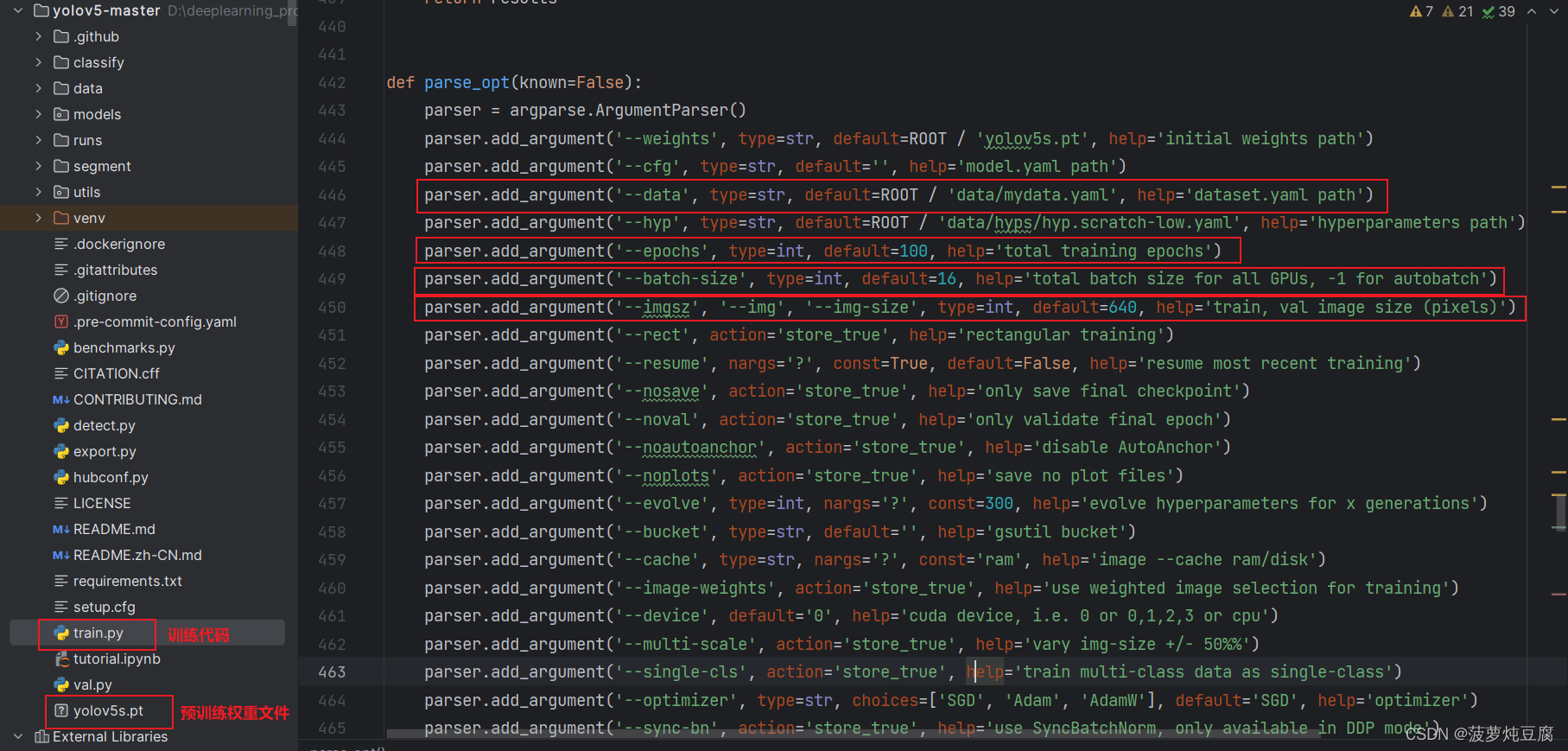
在训练代码中,修改 ‘–data’ 为存放上面我们创建的mydata.yaml的路径,修改合适的迭代次数’–epoch’、批处理数’–batchs-size’ (应该为2的倍数)、和训练的图像大小’–imgz’。
训练报错 - Arial.ttf
在训练过程中,有可能因为没有下载Arial.ttf字体文件而自动下载,在中国大陆,容易下载报错,服务器无响应,这里我们可以提前下载,放进对应的文件夹中 Arial.ttf 下载链接:https://pan.baidu.com/s/1-96nqHsdFsmNxl6uQbl3vw?pwd=hnb8 提取码:hnb8 :

开始训练

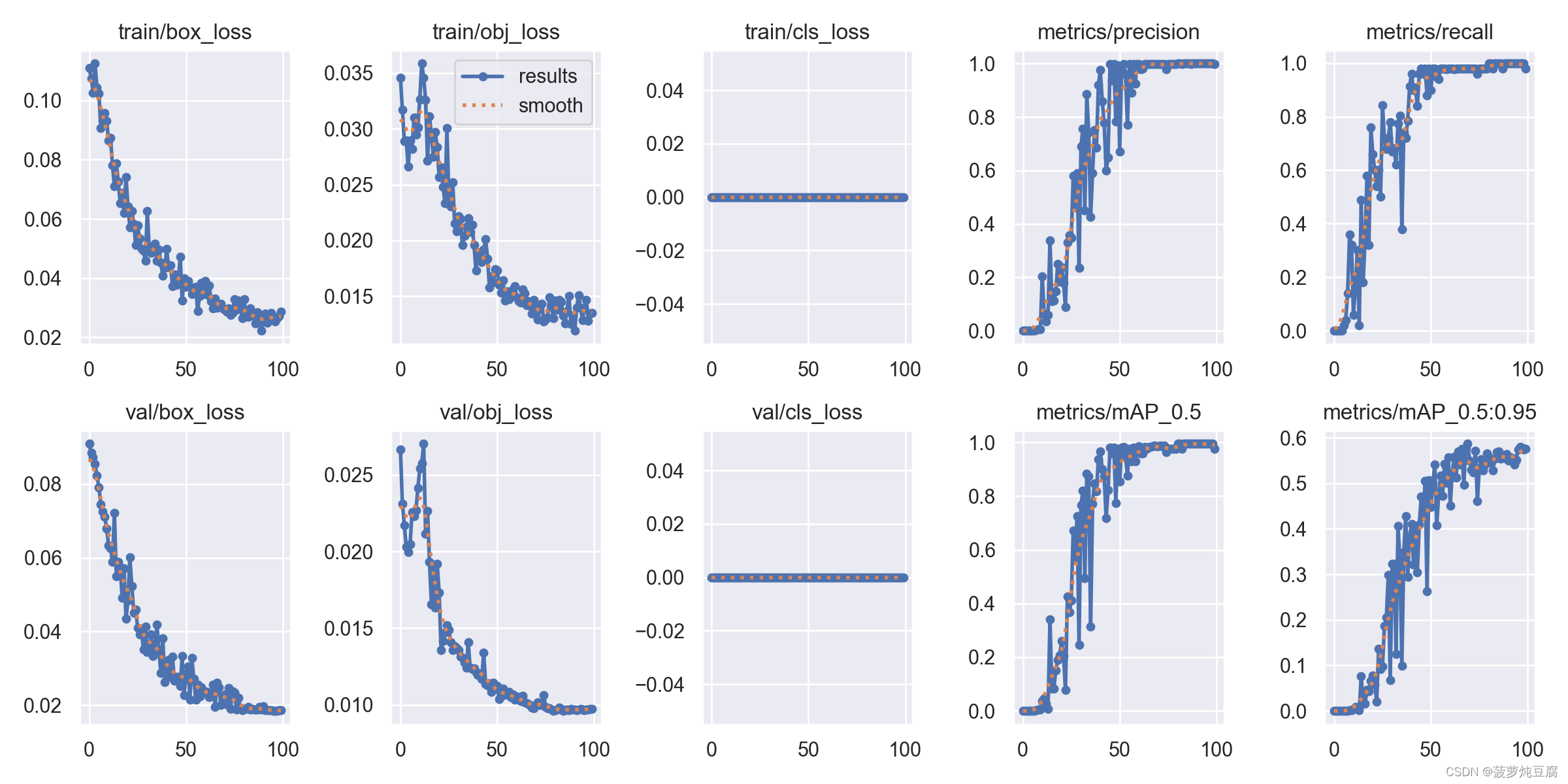
训练结果
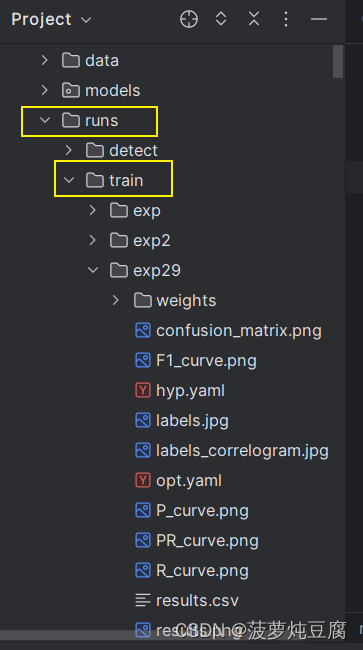
训练结果会在runs文件夹下生成,如exp29文件夹下所有生成的文件均为训练结果,exp29中的weights文件夹下存放着最后一次训练的权重文件和效果最好一次的训练权重文件。
使用训练好的权重模型文件进行预测
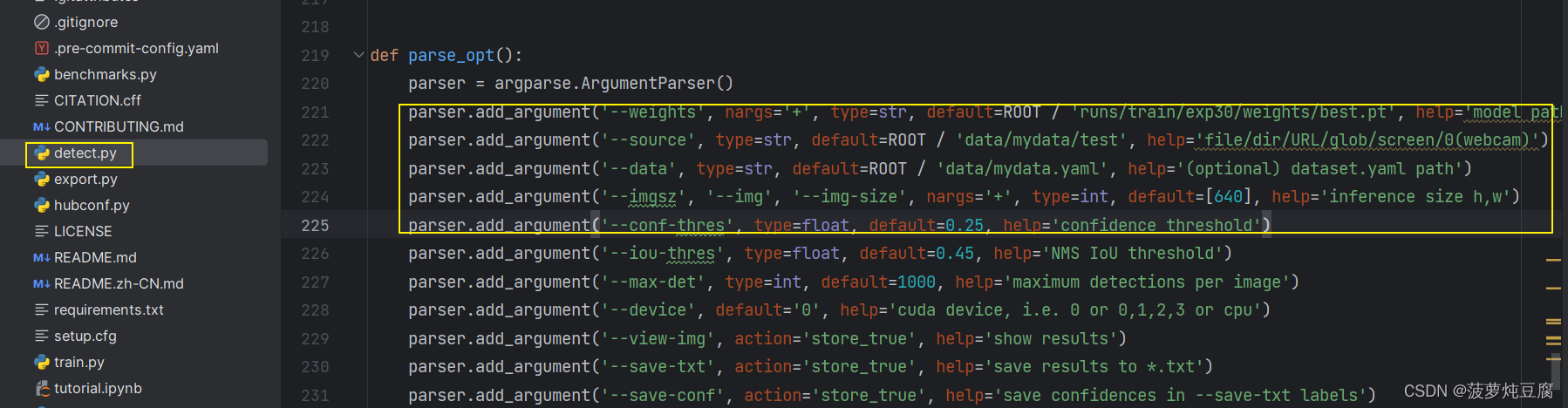
在detect.py 文件中修改‘–weights’为我们自己训练好的模型文件地址,‘–source’为预测图像文件夹,’–data’ 为之前创建的mydata.yaml文件,里面有分类类别,‘–imgsz’为预测图像大小,’–conf-thres’为置信度,'–iou-thres’为IoU
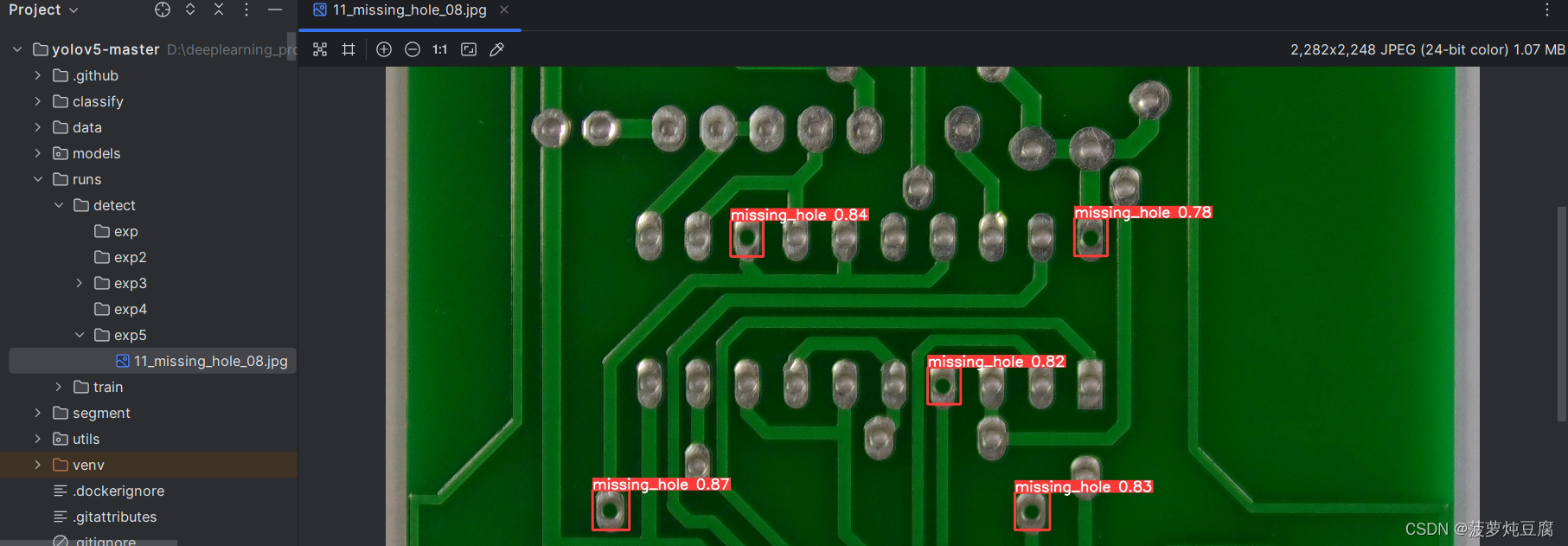
预测结果在runs/detect文件夹下生成


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









