






深度学习专业名词术语释义
神经网络结构
神经元结构
| 名词术语 | 释义 | 功能 |
|---|---|---|
| Neuron(神经元) | 深度学习中的基本计算单元,通常包含一个加权输入的和和一个非线性激活函数。 | / |
| Weights(权重) | 神经网络中用于输入数据加权的参数,是网络通过学习过程中调整的主要对象。 | / |
| Bias(偏置) | 神经网络中的另一组参数,与权重相结合来控制神经元的激活阈值。 | / |
| Activation Function(激活函数) | 用于引入非线性的函数,常见的有ReLU、Sigmoid、Tanh等。 |
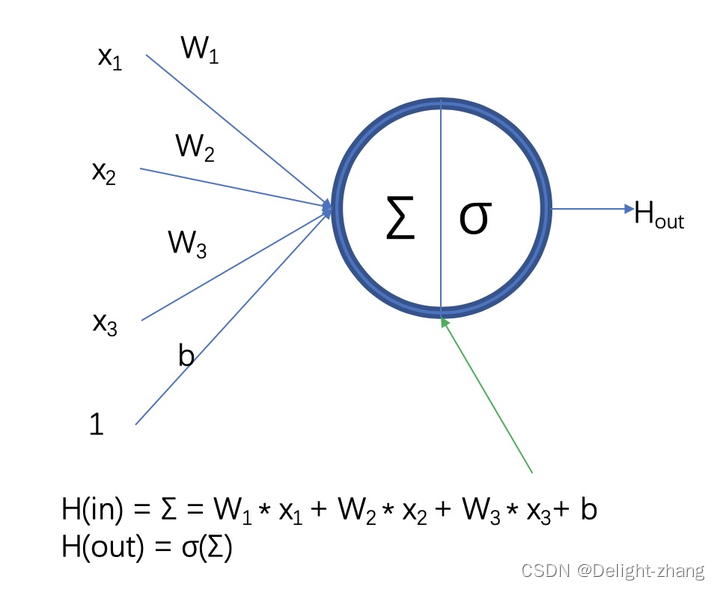
注:W为权重,b为偏置,σ为激活函数。
神经元的线性函数使用的是y = wx +b 而不是其他的非线性函数或者其他的线性函数?
在神经网络中,每个神经元的输出通常由输入的加权和加上一个偏置项来计算,这个线性计算可以表示为
:y=wx+b
- y 是神经元的输出。
- w 是权重,表示输入 * x 对输出 y 的影响程度。
- x 是输入。
- b 是偏置项,它提供了一个可调整的阈值,决定了神经元激活的难易程度。
这种形式的线性函数之所以被广泛使用,有几个原因:
- 模型简单性:线性函数
y=wx+b 是最简单的一类函数,只有两个参数:斜率 w 和截距 b。这种简单性使得模型容易理解和实现。- 可学习性:在神经网络中,w 和 b 是可以通过学习数据来调整的参数。这意味着网络可以通过学习找到最佳的 w 和 b 来逼近目标函数。
- 仿射变换:y=wx+b 实际上是一个仿射变换(affine transformation),它是线性变换的一种,可以提供平移和缩放。在多维空间中,这种变换能够改变数据的分布,为非线性激活函数提供更有利的输入。
- 叠加性:线性函数的输出可以很容易地叠加,即多个神经元的输出可以简单地相加以形成下一层的输入。这种叠加性质在神经网络的设计中非常重要。
- 梯度传播:在反向传播算法中,线性函数的梯度(导数)是常数,这意味着梯度可以有效地通过网络传播,而不会立即消失或爆炸(尽管在深层网络中这仍然可能发生)。
如果使用其他类型的线性函数,比如没有偏置项的 y=wx,神经网络会失去一定的灵活性,因为没有偏置项,每个神经元就无法独立地调整其激活阈值。偏置项允许神经元即使在输入为零时也能有非零的输出,这在很多情况下是有用的,比如当我们想要模型能够捕捉到输入中的偏差时。
因此,使用 y=wx+b 这样的线性函数是为了保持模型的简单性和灵活性,同时使得模型能够适应数据的不同分布,并有效地通过学习调整参数。而非线性部分,则是使用了激活函数。
总的来说,使用y=wx+b,使得模型简单的同时兼具有灵活性和可学习性,而激活函数又能增肌网络的非线性表达能力。
ReLu激活函数:

神经网络主要构成
按层次划分
| 名词术语 | 释义 |
|---|---|
| 层 (Layer) | 神经网络中的一个处理级别,由一组神经元构成。 |
| 输入层 (Input Layer) | 网络的第一层,接受原始数据的输入。 |
| 隐藏层 (Hidden Layer) | 位于输入层和输出层之间的网络层,可以有多个。 |
| 输出层 (OutputLayer) | 在神经网络中,输出层是网络的最后一层,负责将从前面的隐藏层学到的表示转换为具体的输出,如分类标签、连续值或其他形式的预测。输出层的设计取决于特定的任务和所需的输出类型。 |

按模块划分
| 名词术语 | 释义 | 功能 |
|---|---|---|
| Backbone | "Backbone"通常指的是神经网络的主体部分,它负责提取输入数据的特征。在图像处理任务中,backbone通常是一个预训练的卷积神经网络(CNN),如ResNet、VGG、Inception或MobileNet。这些网络通过多个卷积和池化层来提取图像的低级、中级和高级特征。在迁移学习的情况下,backbone通常会使用在大型数据集(如ImageNet)上预训练的权重。 | 负责提取输入数据的特征 |
| Neck | "Neck"是连接backbone和head的部分,它的作用是进一步处理特征,使其更适合后续的任务。不是所有的网络架构都明确区分neck部分,但在一些复杂的模型中,如目标检测或实例分割模型中,neck可以执行特征金字塔网络(FPN)或其他特征融合和增强的操作。 | 连接backbone和head的部分,它的作用是进一步处理特征 |
| Head | "Head"通常指的是网络的最终部分,它根据backbone提取的特征来完成特定的任务,如分类、检测、分割等。例如,在目标检测网络中,head可能包括用于边界框回归的层和用于分类的层。在不同的任务中,head的结构会有很大差异。 | 据backbone提取的特征来完成特定的任务 |
| Block | 我们在使用神经网络的时候,可以N次堆叠 layer,通常我们把这样的一种由多个 layer 组成的模块叫做 block,这种 block 就是一种比 layer 更大规模的可复用单元。 | / |
YOLOv5神经网络架构
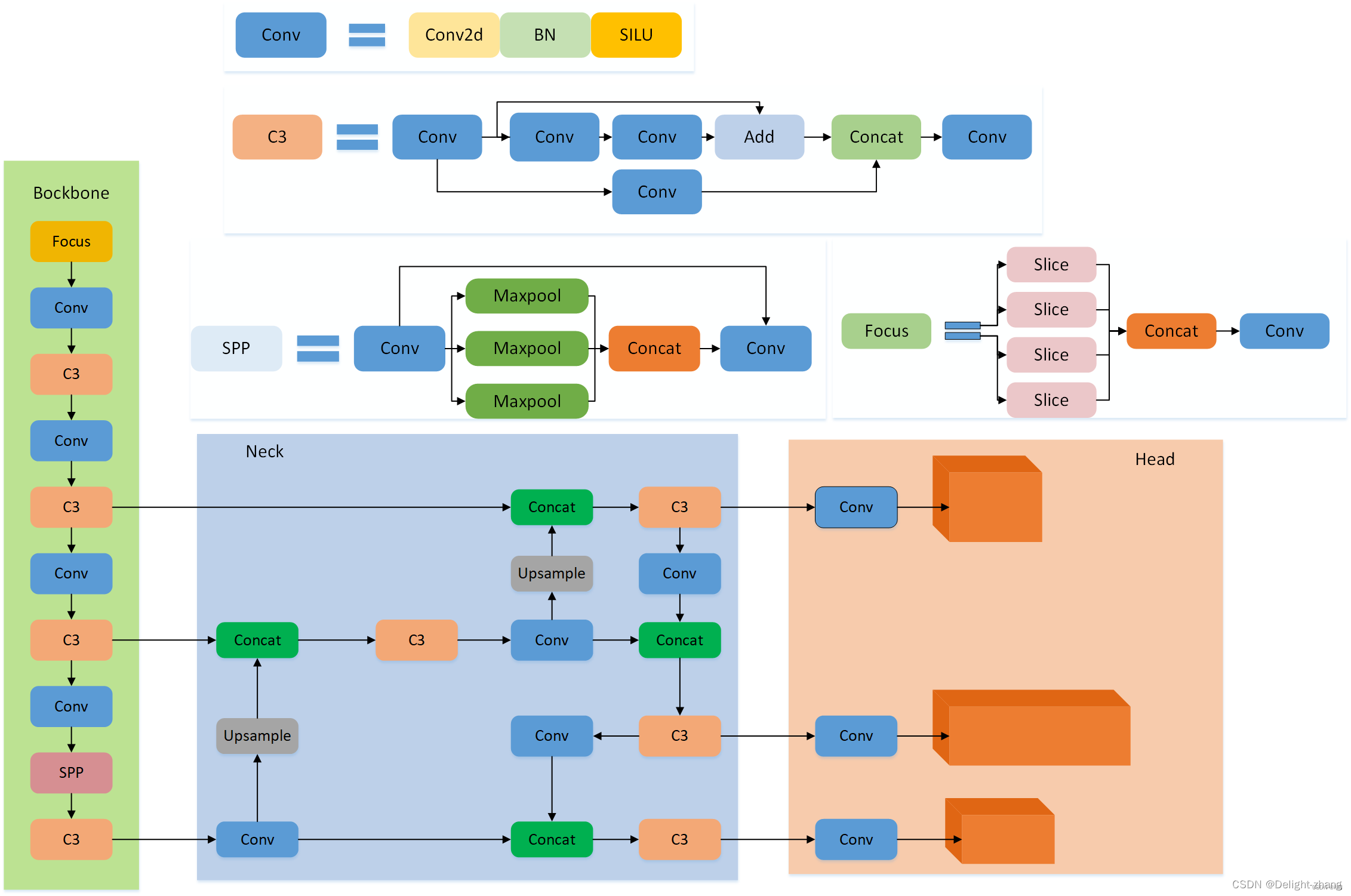
网络中的常见隐藏层
| 名词术语 | 释义 | 功能 |
|---|---|---|
| 卷积层(Convolutional Layer) | 在卷积神经网络(CNN)中使用的特殊隐藏层,用于提取图像特征 | 用于提取输入数据中的局部特征 |
| 池化层(Pooling Layer) | 用于降低特征维度和提取重要信息的网络层,常见的有最大池化(Max Pooling)和平均池化(Average Pooling) | 用于降低特征维度和提取重要信息 |
| 全连接层(Fully Connected Layer) | 也是隐藏层的一种,也可以被称为密集连接层(Dense Layer)或者全连接层(Fully Connected Layer)。全连接层可以将输入特征与每个神经元之间的连接权重进行矩阵乘法和偏置加法操作,从而得到输出结果。在全连接层中,每个神经元都与上一层的所有神经元相连,每个输入特征都与每个神经元之间都存在一定的连接权重。 | 整合特征、决策(分类任务中,输出前的概率分布)、增强非线性能力 |
| 归一化层(Normalization Layer) | 如批归一化(Batch Normalization)层,用于调整前一层的输出,以减少内部协变量偏移并加速训练。除此之外还有层归一化(Layer Normalization)、实例归一化(Instance Normalization)、组归一化(Group Normalization)等 | 高训练过程的稳定性和加快收敛速度 |
| 随机失活层(Dropout层) | 一种正则化技术,它在训练过程中随机丢弃(即设置为零)一部分神经元的输出,以避免过拟合。 | 增加网络非线性处理能力,防止过拟合 |
| 嵌入层(Embedding Layer) | 在处理类别输入数据时使用,如将单词转换为密集的向量表示。常用于自然语言处理(NLP)任务。 | / |
| 残差层(Residual Layer) | 在残差网络(ResNet)中使用,包含跳跃连接(或快捷连接),允许网络学习恒等映射,有助于训练更深的网络。 | 缓解梯度消失、加快收敛、允许更深的网络增强特征传播 |
| 注意力层(Attention Layer) | 用于加权输入的不同部分,以便网络能够集中注意力于最重要的信息。在变压器(Transformer)模型中尤其重要。 | 为模型提供一种动态的信息过滤机制,让网络关注输入的关键信息,提高了模型的性能和灵活性 |
| 稠密层(Dense Layer) | 另一种说法是全连接层,但有时用于特别指代作为输出层之前的最后一个全连接层。 | / |
损失函数、前向传播和反向传播
| 名词术语 | 释义 | 功能 |
|---|---|---|
| 损失函数 | 损失函数(Loss Function),也称为代价函数(Cost Function),在机器学习和深度学习中用来量化模型的预测值与实际值之间的差异。损失函数是一个衡量模型预测错误程度的非负实值函数,训练神经网络的目标就是通过优化算法(如梯度下降)来最小化损失函数。 | 提供了一个优化目标,使得模型能够在训练过程中改进,也为模型的性能提供了评价标准。 |
| 前向传播 | 前向传播是神经网络计算输出的过程。在这个过程中,输入数据在网络中从输入层流向输出层,经过每一层时都会进行相应的变换。 步骤包括:1、输入层接收数据:输入层的神经元接收原始数据。2、加权和偏置:数据通过与每个神经元相关联的权重相乘,并加上偏置。3、激活函数:加权和加偏置后的值被送入激活函数,激活函数通常是非线性的,使得网络能够学习和模拟非线性关系。4、传递到下一层:激活函数的输出成为下一层的输入。5、重复过程:以上过程在每一层重复,直到最后一层。6、输出层产生最终结果:最后一层的输出是网络的最终输出,它可以是分类的概率、回归的数值或其他形式的预测。 | 前向传播的主要功能是根据当前的权重和偏置值,计算神经网络对给定输入的预测输出。 |
| 反向传播 | 反向传播是神经网络训练中用于优化权重的算法。当前向传播完成后,网络的输出会与实际的目标值进行比较,计算出预测误差。 步骤包括:1、计算误差:使用损失函数(如均方误差或交叉熵损失)计算预测输出与实际标签之间的差异。2、计算梯度:计算损失函数关于网络权重的梯度,这通常通过链式法则进行。3、反向传递梯度:将这些梯度从输出层反向传递到输入层,过程中更新每层的权重梯度。4、权重更新:使用梯度下降或其他优化算法,根据计算出的梯度来调整权重,目的是减少损失。 | 反向传播的主要功能是通过计算损失函数相对于每个权重的梯度,并使用这些梯度来更新权重,从而使得网络的预测输出更接近实际的目标值,即优化网络的性能。 |
- 总结来说,前向传播和反向传播是神经网络训练的两个互补过程:前向传播负责生成预测结果,反向传播负责根据预测结果和实际结果之间的误差来优化网络参数,以便在未来的前向传播中产生更准确的输出。
常见神经网络结构
| 名词术语 | 释义 |
|---|---|
| 前馈神经网络(FNN) | 前馈神经网络(Feedforward Neural Networks, FNN)是最简单的人工神经网络架构之一,在这种网络中,信息只在一个方向上流动,从输入节点流向输出节点,可能会经过一个或多个隐藏层,但不会形成任何循环或环。这种“前馈”的特性意味着网络中的信号只在一个方向上传播,即从输入层到隐藏层,再从隐藏层到输出层。 |
| 卷积神经网络(CNN) | 主要用于图像处理的神经网络类型。 |
| 循环神经网络(RNN) | 适用于时间序列数据或文本数据的神经网络类型。 |
| 长短期记忆网络(LSTM) | 一种特殊的RNN,能够学习长期依赖信息。 |
| 生成对抗网络(GAN) | 由生成器和判别器组成,用于生成数据的神经网络结构。 |
其他一些常见名词
| 名词术语 | 释义 |
|---|---|
| 感知机(Perceptron) | 感知机通常指单层的神经网络结构,它只有输入层和一个输出节点,输出节点是一个线性分类器,通常使用阶跃函数作为激活函数。 |
| 多层感知机(Multilayer Perceptron,简称 MLP) | 一种前馈人工神经网络模型,它扩展了原始感知机的概念,通过引入一个或多个隐藏层来解决非线性问题。也可以被理解以一种非常基础的神经网络,CNN、RNN等神经网络都是以此为基础的变体形式。 |
| 损失函数(Loss function) | 也称为目标函数(Objective function)或代价函数(Cost function),是用来衡量模型预测值与真实值之间差异的函数。在机器学习和深度学习中,损失函数用于指导模型的训练过程,通过最小化损失函数来优化模型的参数。 |
| 特征提取器(Feature Extractor) | 通常指backbone部分,负责从原始数据中提取有用的特征。 |
| 特征图(Feature Map) | 由卷积层生成的多维张量,包含了输入数据的空间特征。 |
| 锚框(Anchor Box) | 在目标检测任务中使用的一种先验框,用于作为候选对象检测的参考。 |
| 感受野(Receptive Field) | 网络中一个神经元所能"看到"的输入数据的区域。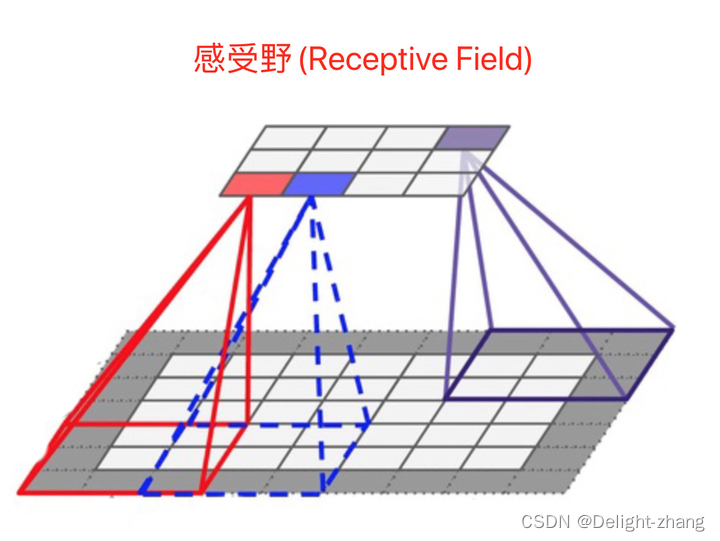 |
| 填充(Padding) | Padding(填充)是一种在输入数据周围添加额外值(通常是零)的技术,用于在卷积神经网络(CNN)和其他层中处理边界效应和尺寸不匹配的问题,保持特征图尺寸的一致性。 |
| 步幅(Stride) | 是指卷积操作中卷积核在输入数据上滑动的步长。Stride决定了每次滑动的距离,从而影响输出特征图的尺寸。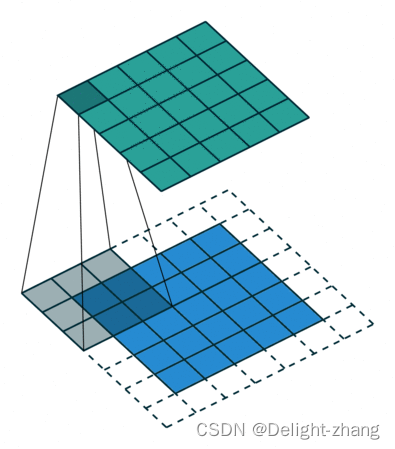 |
| 滤波器(Filter) | 常指卷积神经网络(CNN)中的卷积核(convolutional kernel)或滤波器矩阵。卷积神经网络使用滤波器来进行特征提取和图像处理。 |
| 信道(Channel) | 是指表示数据在不同特征维度上的分离和组织方式。通常,通道在卷积神经网络(CNN)中用于处理多个特征图或多个输入信号。 |
| 上采样(Upsampling) 和 下采样(Downsampling) | 分别指增加和减少特征图的空间分辨率的操作 |
| 跳跃连接(Skip Connection) | 一种网络连接方式,允许从一个层的输出直接连接到后面层的输入,有助于缓解梯度消失问题,常见于ResNet架构。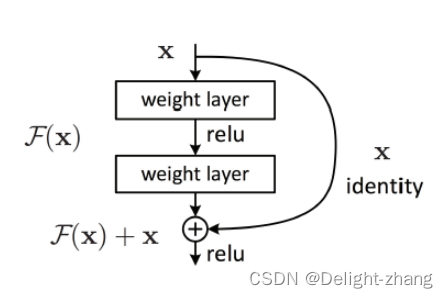 |
| 端到端(End-to-End) | 指的是一个完整的流程,通常从输入数据到最终输出结果,不需要人为干预的步骤。 |
| 端到端学习(End-to-End Learning) | 一种设计哲学,旨在通过单个模型直接从原始数据到最终输出进行学习,最小化预处理和特征工程。 |
| 微调(Fine-tuning) | 在预训练模型的基础上,针对特定任务继续训练模型的过程。 |
| 迁移学习(Transfer Learning) | 利用在一个任务上学到的知识来解决另一个相关任务的过程。 |
| 多任务学习(Multi-task Learning) | 在一个模型中同时学习多个相关任务,共享一些通用的表示。 |
| one-shot | 指的是模型能够仅通过一个样本来学会一个新的任务或者识别一个新的对象。例如,在图像识别中,模型能够仅通过查看一张猫的图片就能学会识别猫。这要求模型具有很强的泛化能力。 |
| zero-shot | 是指模型在没有见过任何示例的情况下学会执行某项任务。这通常通过将知识从模型已知的类别转移到未知的类别来实现,例如,通过属性(所有猫都有尾巴,所有鸟都有翅膀)来识别新的动物类别。 |
| few-shot | 介于one-shot和传统机器学习之间,指的是模型能够通过非常少量的样本(通常几个到几十个)来学会一个新的任务。这种方法通常需要先进的算法来优化模型,使其能够从很少的数据中学习到足够的信息。 |
| 自监督学习(Self-supervised learning) | 无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务 |
| 半监督学习(Semi-supervised learning) | 在半监督学习中,模型首先使用少量有标签数据进行训练,然后利用这些信息来处理大量无标签数据。这种方式适用于标签数据稀缺或者标注成本高昂的情况。 |
| 无监督学习(Unsupervised learning) | 监督学习不使用任何标签数据,而是直接从输入数据的结构中提取模式。 |
模型训练
神经网络的训练是指通过使用训练数据来调整神经网络的参数,使其能够学习并适应给定任务。在神经网络中,参数通常是指连接权重W和偏置(或阈值)b,它们决定了神经元之间的信息传递和计算过程。
| 名词术语 | 释义 |
|---|---|
| GPU | 一种可以并行计算的图形处理器 |
| CUDA | 显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题,在深度学习中,存在着广泛的使用,一般的深度学习平台都有其对应CUDA的版本。安装时需要查看GPU支持的版本 |
| cuDNN | cuDNN(CUDA Deep Neural Network library) 是由NVIDIA开发的一个深度学习GPU加速库。 cuDNN旨在提供高效、标准化的原语(基本操作)来加速深度学习框架(例如TensorFlow、PyTorch、PaddlePaddle)在NVIDIA GPU上的运算。根据安装的CUDA版本对应安装。 |
| Pytorch、Tensorflow、PaddlePaddle、Caffe等 | 开源的深度学习平台 |
| 特征(Feature) | 输入数据的属性,用于模型训练的各种指标或测量值。 |
| 标签(Label) | 在监督学习中,数据的真实输出值。 |
| 样本(Sample) | 数据集中的一个元素,包含特征和通常在监督学习中包含标签。 |
| 迭代(Iteration) | 每次模型更新权重的过程,通常发生在一个批次的数据上。 |
| 权重初始化(Weight initialization) | 权重初始化就是在开始训练神经网络之前,先给每个神经元的权重随机赋值一个初始的值。帮助网络更快收敛。 |
| 权重更新(Weights Update) | 用梯度下降或其它优化算法调整权重和偏置,以减少损失。 |
| 权重冻结(Weight freezing) | 指在神经网络训练过程中固定(不更新)特定层或特定参数的权重。通过冻结权重,这些层或参数将在后续的训练过程中保持不变。(通过冻结权重,可以减少需要更新的参数数量,从而加快训练速度,并且可以防止已经学到的特征被过度调整。这对于数据集较小或特定任务的训练中尤为有用,因为这些情况下,模型可能更容易出现过拟合。) |
| 验证集(Validation Set) | 用于在训练过程中评估模型性能的数据集,不用于训练。 |
| 测试集(Test Set) | 在训练完成后用于评估模型最终性能的数据集。 |
| 早停(Early Stopping) | 为了防止过拟合而提前终止训练的策略。 |
| 参数(Parameter) | 模型训练过程中学习的权重W和偏置b。 |
| 迭代(Iteration) | 每次模型更新权重的过程,通常发生在一个批次的数据上。 |
| 梯度消失 | 指梯度变得非常小,几乎为零,导致权重几乎不更新,使得模型训练停滞不前。 |
| 梯度爆炸 | 指在训练神经网络时,梯度(用于更新权重的值)变得非常大,导致权重更新过度,使得模型无法稳定学习。 |
常见的一些训练需要设置的参数
以YOLOv5为例:
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/mydata.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=16, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
这里挑选了一些参数进行解释
| 参数 | 代表的名词 | 释义 |
|---|---|---|
| weights | 预训练模型 | 预训练模型是已经经过大量数据集训练过的模型,可直接进行使用。也可以针对特定的任务,在基础上,进行微调或添加新的数据再训练 |
| cfg | 配置文件 | 里面存储着模型的结构参数,例如backbone的隐藏层输入输出维度,分类类别和预选框等 |
| data | 训练数据 | 标注好的训练数据 |
| epochs | 训练轮数 | Epoch指定模型将对整个训练数据集进行几次完整的遍历。在每个Epoch中,模型将使用不同的批次进行训练,并更新模型的参数。通过增加Epoch的数量,模型有更多机会学习训练数据中的模式和特征,从而提高模型的性能和泛化能力,但同样的也会增加训练消耗的时间。 |
| batch-size | 批次大小 | Batch size指定每个训练批次中的样本数量。在每个批次中,这些样本将被同时输入到模型中进行前向传播和反向传播,然后通过优化算法进行参数更新。较大的批次大小可以提高训练速度,因为可以并行处理更多的样本,但也需要更多的内存来存储中间结果。 |
| imgsz | 指定输入图片的大小 | 指定输入图片的大小。 |
| evolve | 遗传算法 | 是否使用遗传算法进行超参数优化,以及遗传迭代次数。 |
| cache | 训练数据缓存 | 将文件转化到内存或者硬盘中,加快训练速度。 |
| device | 指定使用的计算设备 | 如"cpu"或"cuda:0"。默认值为"cuda:0",表示使用第一个可用的GPU设备进行训练。 |
| multi-scale | 多尺度图像 | 多尺度图像(Multi-scale Image)指的是在不同尺度上表示和处理的图像。在计算机视觉和图像处理领域,多尺度图像常用于解决物体检测、目标跟踪、图像分割等任务中的尺度变化和多尺度信息的问题。 |
| optimizer | 优化器 | 优化器(Optimizer)是深度学习中的一个关键组件,用于更新模型的参数以最小化损失函数。在训练过程中,通过不断迭代地调整模型的参数,优化器能够使模型逐渐收敛到最优解或接近最优解。深度学习中的优化器的主要目标是最小化损失函数。损失函数用于衡量模型的预测输出与真实标签之间的差异,优化器的任务是通过调整模型的参数来降低损失函数的值。 |
| sync-bn | 同步批量归一化 (SyncBatchNorm) | 同步批量归一化(Synchronized Batch Normalization)是一种批量归一化(Batch Normalization)的变体,用于在分布式训练中处理多个GPU之间的批量归一化操作。,只在分布式训练 (DDP mode) 模式下可用,当多GPU时候启用 |
| workers | 加载数据的进程数 | 使用CPU进程来加载图像数据,例如 --workers 8 表示使用 8 个进程来加载数据 |
| quad | 四进程数据加载器 | 四进程数据加载器,在多 GPU 训练时可以有效提高数据的加载速度,但需要更多的 CPU 和内存资源。 |
| cos-lr | 余弦退火学习率 (cosine learning rate) 调度器 | 使用余弦退火算法,在训练过程中可以动态地调整学习率 |
| label-smoothing | 标签平滑技术 (label smoothing) | 标签平滑(Label Smoothing)是一种用于改善分类模型性能和鲁棒性的技术。,使得模型对输入数据的微小扰动更加鲁棒,并且可以减少过拟合。 |
| patience | 表示早停 (early stopping) 的耐心值 (patience) | 表示在多少个 epochs 内没有提高性能就停止训练。 |
Batch Size和Epoch的关系与选择
Batch size和Epoch之间的关系可以通过以下方式理解:
每个Epoch需要处理的总样本数量 = Batch size × 训练数据集的样本数量。 较大的Batch size将导致每个Epoch需要更少的批次,因为每个批次包含更多的样本。相应地,较小的Batch
size将导致每个Epoch需要更多的批次,因为每个批次包含更少的样本。训练的总迭代次数 = Batch size × Epoch。 Batch size和Epoch的乘积表示整个训练过程中的总迭代次数。这个值可以用来衡量训练的规模和计算资源的消耗。
在选择Batch size和Epoch时,需要考虑以下几点:
- Batch size较大可以提高训练速度,但可能需要更多的内存。如果内存受限,可以选择较小的Batch size。
- Epoch数量较大可以提高模型的性能和泛化能力,但可能需要更长的训练时间。需要根据数据集的复杂性和模型的收敛速度来选择合适的Epoch数量。
超参数
超参数(Hyperparameters)是机器学习和深度学习模型中的可调整参数,用于控制模型的行为和性能。与模型的权重和偏差不同,超参数通常在训练过程之前设置,并且需要手动选择或通过试验和调整来确定,非训练而来的。常见的超参数如下:
| 名词术语 | 释义 | 作用与功能 |
|---|---|---|
| 学习率(Learning Rate) | 在梯度下降中,决定权重更新幅度的超参数。 | 学习率控制模型在每次参数更新时的步长大小。较高的学习率可能导致参数更新过大而无法收敛,而较低的学习率可能导致训练过程缓慢。选择合适的学习率是优化模型性能的关键。 |
| 批量大小(Batch Size) | 用于在训练过程中一次性传递给模型的一组样本。 | 批量大小定义了每次模型更新时所使用的训练样本数量。较大的批量大小可以加快训练速度,但也增加了内存需求。较小的批量大小可以提供更稳定的梯度估计,但训练过程可能更慢。 |
| 纪元(Epoch) | 整个训练数据集被模型完整地通过一次的周期。 | 迭代次数指定了模型要遍历整个训练数据集的次数。较多的迭代次数可以提高模型的训练效果,但如果过多,可能会导致过拟合。 |
除此之外的超参数还有:正则化参数(Regularization Parameter)、优化算法的超参数和网络结构相关超参数。
过拟合和欠拟合
| 名词术语 | 释义 |
|---|---|
| 欠拟合(Underfitting) | 欠拟合指的是模型在训练数据和测试数据上都表现不佳的情况。欠拟合通常发生在模型过于简单或参数过少的情况下。当模型无法捕捉到数据中的关键特征和模式时,它可能无法在训练数据和测试数据上都取得良好的性能。 |
| 过拟合(Overfitting) | 过拟合指的是模型在训练数据上表现出很好的性能,但在未见过的测试数据上表现较差的情况。 过拟合通常发生在模型过于复杂或参数过多的情况下。当模型过于关注训练数据中的细节和噪声时,它可能会在训练数据上产生过高的拟合度,但对于新数据的泛化能力较差。 |
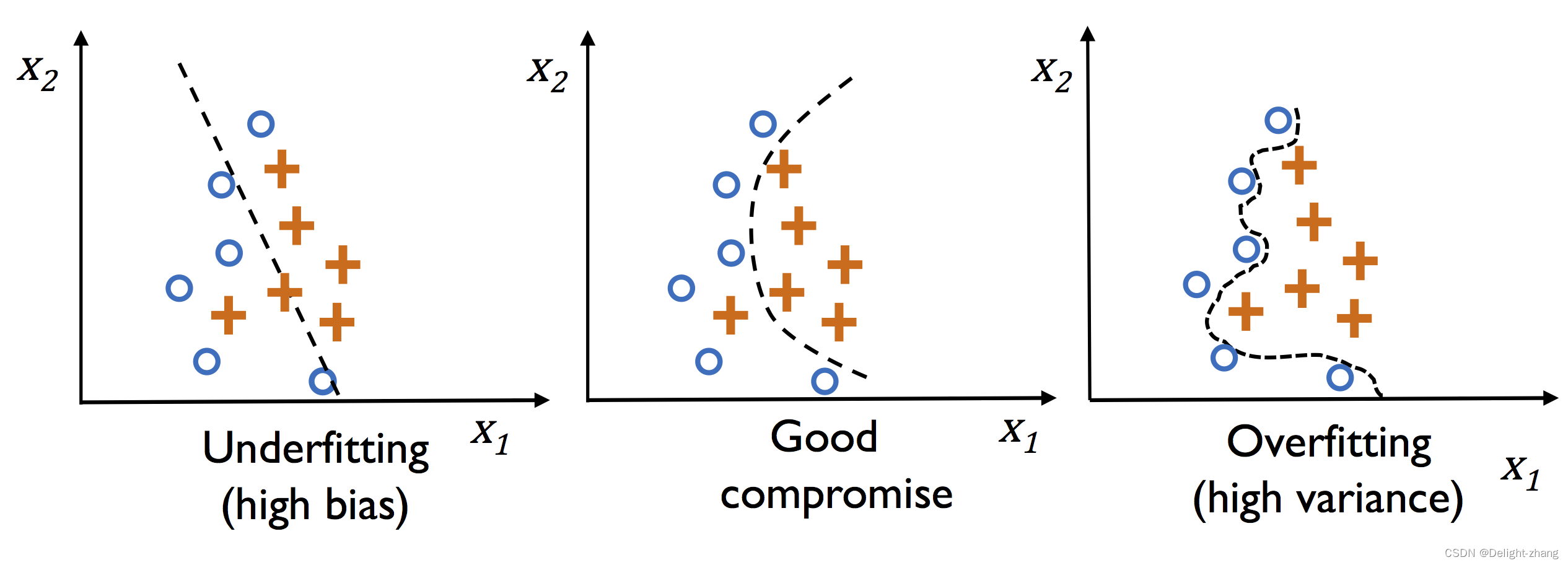
过拟合和欠拟合的解决方法如下:
过拟合的解决方法:
- 数据增强(Data Augmentation):通过对训练数据进行随机变换和扩充,增加训练样本的多样性,减少过拟合的风险。
- 正则化(Regularization):通过在损失函数中引入正则化项,惩罚模型的复杂性,以防止过拟合。常见的正则化方法包括L1正则化和L2正则化。
- 提前停止(Early Stopping):在训练过程中,根据验证数据集的性能,及时停止训练以防止过拟合。
- 简化模型结构:减少模型的复杂度,例如减少网络层数、降低隐藏层的维度等。
欠拟合的解决方法:
- 增加模型复杂度:增加模型的容量,例如增加网络的层数、增加隐藏层的维度等,以提高模型的拟合能力。
- 特征工程(Feature Engineering):通过手动设计和选择更多的特征,以提高模型对数据中关键特征的捕捉能力。
- 收集更多的数据:增加训练数据的数量,以提供更多的样本和变化,有助于提高模型的泛化能力。
正则化
正则化技术通常是用来
| 名词术语 | 释义 |
|---|---|
| L1正则化 | 在损失函数中加入权重的绝对值之和,促使部分权重变为0,从而产生一个稀疏模型,有助于特征选择。 |
| L2正则化 | 在损失函数中加入权重的平方和,使得权重值较小,防止权重过大导致的过拟合,通常会使模型变得更加平滑。 |
| Dropout(随机失活) | 在训练过程中随机“丢弃”神经网络中的一些神经元(即将它们的输出设置为0),减少神经元之间复杂的共适应关系,增强模型的泛化能力。 |
优化算法
在机器学习和深度学习中,优化算法用于改进模型的参数,在训练过程中以最小化或最大化一个目标函数(通常是损失函数),以期待找到全局最优解为目标。以下是常见的一些优化算法:
| 名词术语 | 释义 |
|---|---|
| 梯度下降(Gradient Descent) | 这是最基本的一种优化算法,通过计算损失函数的梯度并沿着梯度的反方向更新参数来最小化损失。 |
| 随机梯度下降(Stochastic Gradient Descent, SGD) | 与传统的梯度下降相比,SGD每次更新只使用一个训练样本的梯度,这使得更新更快并且可以逃离局部最小值,随机性增强。 |
| 小批量梯度下降(Mini-batch Gradient Descent) | 梯度下降和SGD的折衷,每次更新参数时使用小批量的数据(例如32或64个样本),既提高了计算效率,又保持了一定的稳定性。 |
| 动量(Momentum) | 一种旨在加速SGD的优化技术,考虑历史值,也就是通过累积过去梯度的加权平均来调整更新方向,有助于加快学习速度并减少震荡。 |
| Adam(Adaptive Moment Estimation) | 结合了动量和RMSprop的优点,通过计算梯度的一阶矩估计(均值)和二阶矩估计(未中心化的方差)来自适应地调整每个参数的学习率,通常在各种不同的问题上表现得相当好。 |
| 移动平均(EMA) | 指数移动平均(Exponential Moving Average)也叫权重移动平均(Weighted Moving Average),是一种给予近期数据更高权重的平均方法。通常用于平滑模型参数,以提高模型在验证集和测试集上的泛化能力。这种技术经常在训练过程中用来跟踪模型参数的移动平均,从而得到更加稳定的模型版本。 |
模型评估与调试
| 名词术语 | 释义 |
|---|---|
| SOTA | SOTA全称是state of the art,是指在特定任务中目前表现最好的方法或模型。 |
| Benchmark | 指的是一组用于评估和比较算法或系统性能的标准测试或数据集。这些测试可以是标准化的,也可以是广泛认可的,使得不同方法之间的比较变得公平和一致。 |
| baseline | Baseline是指在进行实验或开发新算法时用作参考点的基线模型或方法。在机器学习领域,baseline通常是一个广为人知的算法,可以是最基础同时性能又不错的算法,也可以是最先进、性能最好的算法(SOTA) |
| Metric | 评测指标 |
| TP | 被模型预测为正类的正样本 |
| FP | 被模型预测为正类的负样本 |
| TN | 被模型预测为负类的负样本 |
| FN | 被模型预测为负类的正样本 |
| 准确率(Accuracy) | 准确率是分类问题中最直观的性能度量,它衡量的是所有分类正确的样本(真正例和真负例)占总样本数的比例。它的计算公式是: |
| 精确率或查准率(Precision) | 精确率关注预测为正类的样本中,实际为正类的比例。它的计算公式是: 其中,假正例(FP)是负类被错误预测为正类的数量。精确率特别适用于那些假正例的代价很高的情况。 其中,假正例(FP)是负类被错误预测为正类的数量。精确率特别适用于那些假正例的代价很高的情况。 |
| 召回率(Recall) | 召回率衡量的是所有实际为正类的样本中,被正确预测为正类的比例。它的计算公式是:  |
| F1分数 | 精确度和召回率的调和平均值。 F1分数的值也在0到1之间,值越高表示模型的精确率和召回率越平衡,即模型的性能越好。 F1分数的值也在0到1之间,值越高表示模型的精确率和召回率越平衡,即模型的性能越好。 |
| IoU | 它衡量的是预测的边界框(或分割区域)与真实边界框(或分割区域)之间的重叠程度。IoU的值范围从0到1,值越高表示预测和真实之间的重叠越多,模型的性能越好。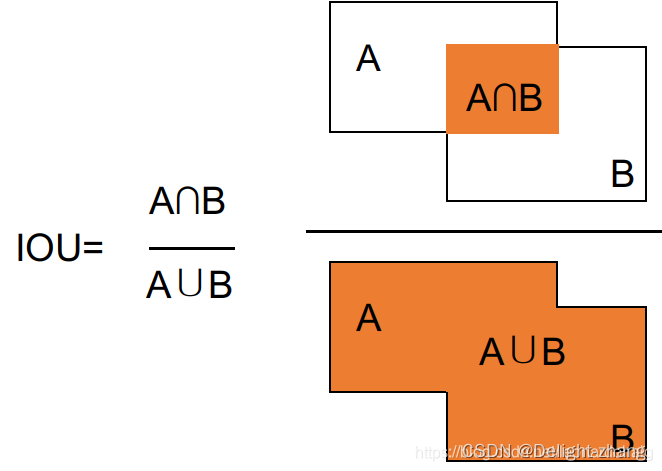 |
| ROC | ROC曲线是一个图形工具,用于展示分类模型在所有可能的分类阈值下的性能。它通过将真正例率(True Positive Rate, TPR)或召回率绘制在Y轴,假正例率(False Positive Rate, FPR)绘制在X轴来实现。ROC曲线下方的面积越大,表示模型的性能越好。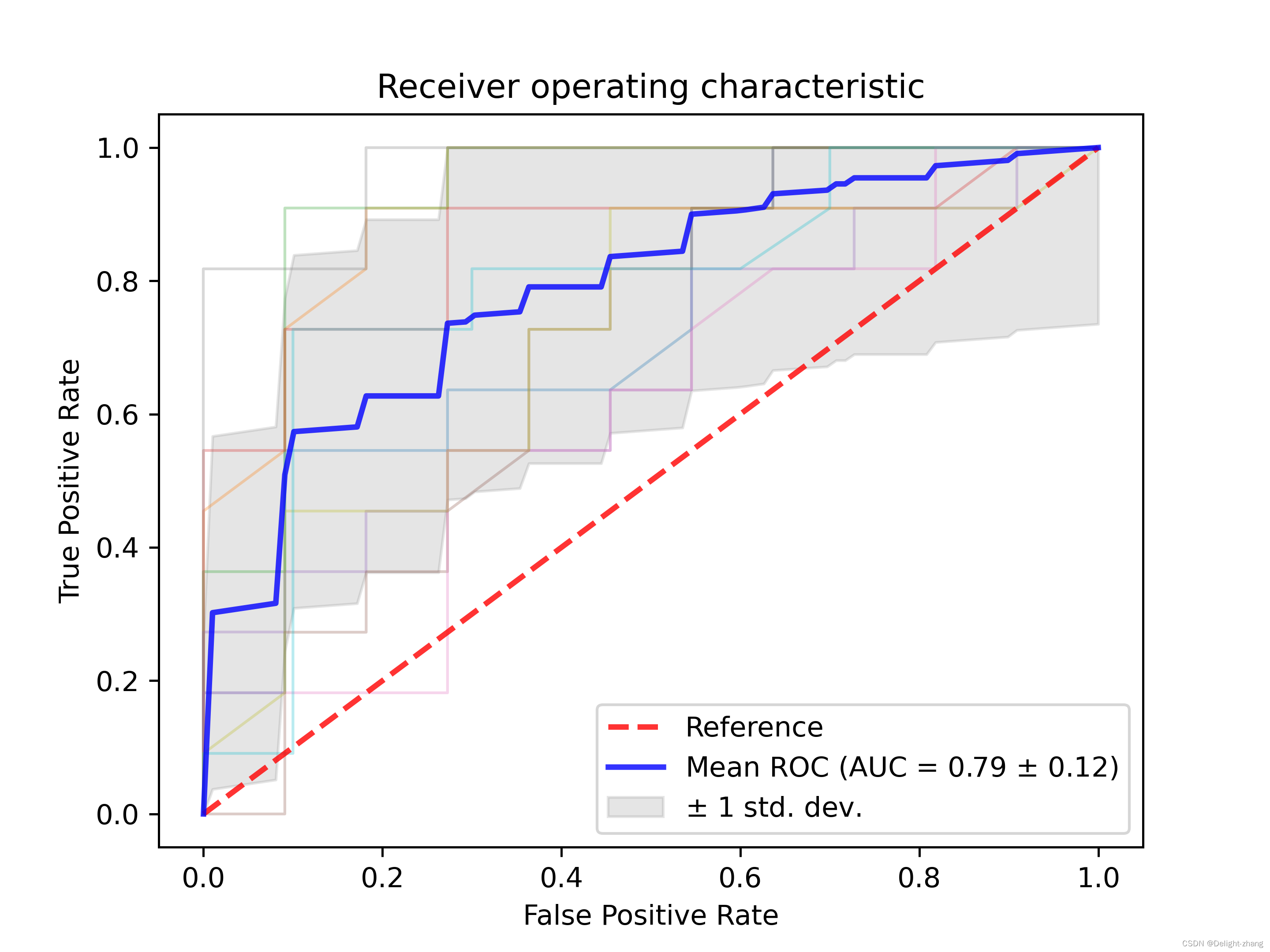  |
| AUC | AUC衡量的是ROC曲线下的面积,值介于0和1之间。AUC值越大,表示模型的分类性能越好。AUC为0.5通常意味着模型没有区分能力,等同于随机猜测;AUC为1意味着模型在这个任务上有完美的性能。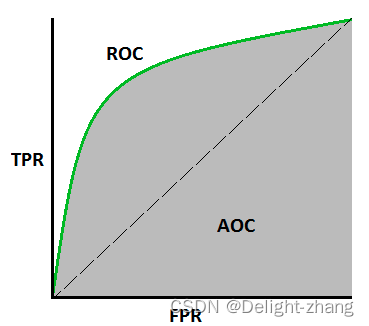 |
| AP | AP是精确率和召回率曲线下的面积,它在信息检索和对象检测任务中被用来衡量模型的性能。对于每个召回率水平,计算对应的最大精确率,然后对这些值求平均得到AP。AP值越高,表示模型的性能越好。 |
| mAP | mAP是在多个类别或多个查询上AP值的平均,常用于多类分类或多标签分类问题。在对象检测和实例分割任务中,mAP是对不同阈值的IoU计算AP之后的平均值。举个例子,在PASCAL VOC挑战中,mAP是在IoU > 0.5时计算的所有类别的AP的平均值。在COCO挑战中,mAP是在不同IoU阈值(通常是从0.5到0.95,间隔为0.05)的AP的平均值。mAP越高,表示模型的整体性能越好。 |
| FLOPs | 一个衡量计算性能的指标,代表浮点运算次数,通常用来描述在执行某个任务(如训练或推理一个神经网络)时所需的计算复杂度。 |
| 混淆矩阵 | 混淆矩阵是一个用于评估分类模型性能的表格,它展示了模型预测的类别和实际类别之间的关系。混淆矩阵只有四个元素,就是TP FP TN FN |
| mIOU | 对每个类别数据集单独进行推理计算,计算出的预测区域和实际区域交集除以预测区域和实际区域的并集,然后将所有类别得到的结果取平均。常用于图像分割领域 |
| Kapp系数 | :一个用于一致性检验的指标,可以用于衡量分类的效果。kappa系数的计算是基于混淆矩阵的,取值为-1到1之间,通常大于0。Kappa系数越高模型质量越好。 |
| Dice系数 | 一种集合相似度度量函数,通常用于计算两个样本的相似度,取值为[0,1]。在医学图像分割中,Dice系数常被用来评估模型的分割性能 |
| 像素准确率(Pixel Accuracy,PA) | |
| 类别像素准确率(Class Pixel Accuray,CPA) | |
| 类别平均像素准确率(Mean Pixel Accuracy,MPA) |
以西瓜数据集为例,我们来通俗理解一下什么是TP、TN、FP、FN。
- TP:被模型预测为好瓜的好瓜(是真正的好瓜,而且也被模型预测为好瓜)
- TN:被模型预测为坏瓜的坏瓜(是真正的坏瓜,而且也被模型预测为坏瓜)
- FP:被模型预测为好瓜的坏瓜(瓜是真正的坏瓜,但是被模型预测为了好瓜)
- FN:被模型预测为坏瓜的好瓜(瓜是真正的好瓜,但是被模型预测为了坏瓜)
简而言之,precision 就是查准率,在模型中识别出是西瓜的好瓜的比率,recall就是查全率,有多少好瓜被识别出来。

















 7772
7772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









