







隐私计算实训营第二期-第八课
第八课:密态引擎SPU框架介绍
首先必须感谢蚂蚁集团及隐语社区带来的隐私计算实训第二期的学习机会!
本节课由蚂蚁隐私计算部SPU负责人谭晋老师讲解。

本节课主要内容有三个:
- 做SPU的原因
- SPU的介绍
- SPU的应用现状和展望

1 做SPU的原因
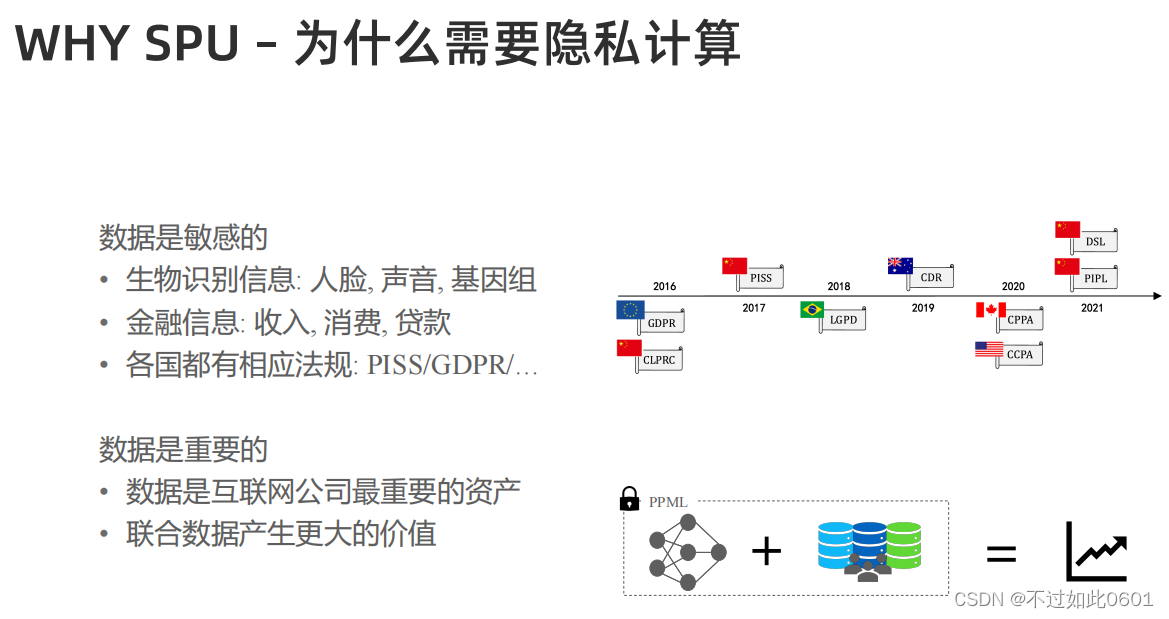
1.1 隐私保护的需求
做SPU有如下一些原因,比如在大模型中:
- 需要包含模型本身和用户的隐私
- 需要保护数据资产
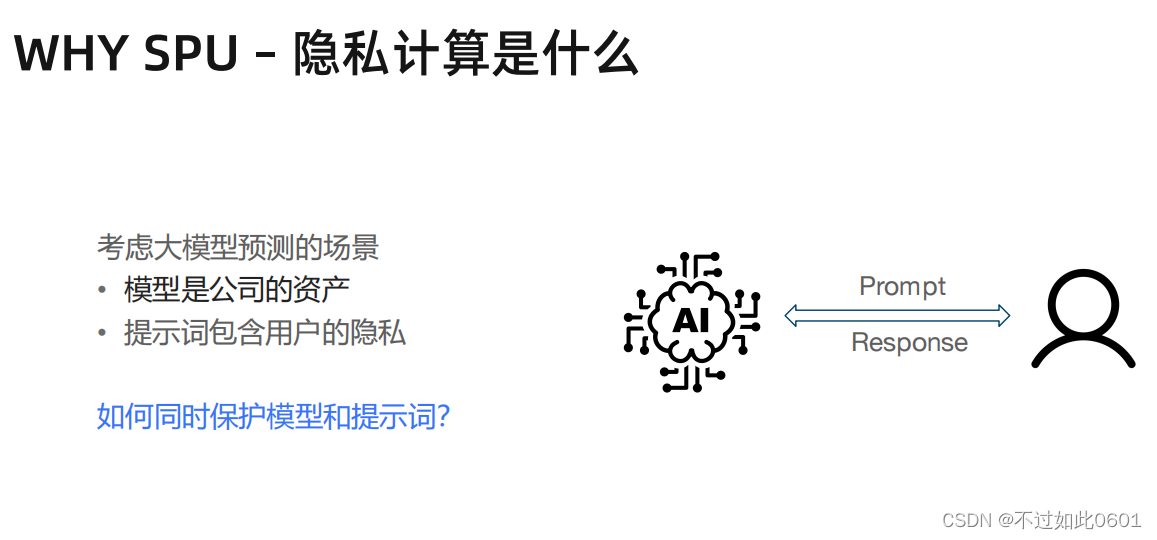
1.2 隐私计算提供了技术解
利用隐私计算技术可以实现:模型对用户是加密的,并且提示词对公司是加密的。

但是隐私计算的技术路线有很多:

利用多方安全计算能够同时实现模型和用户输入的隐私性:
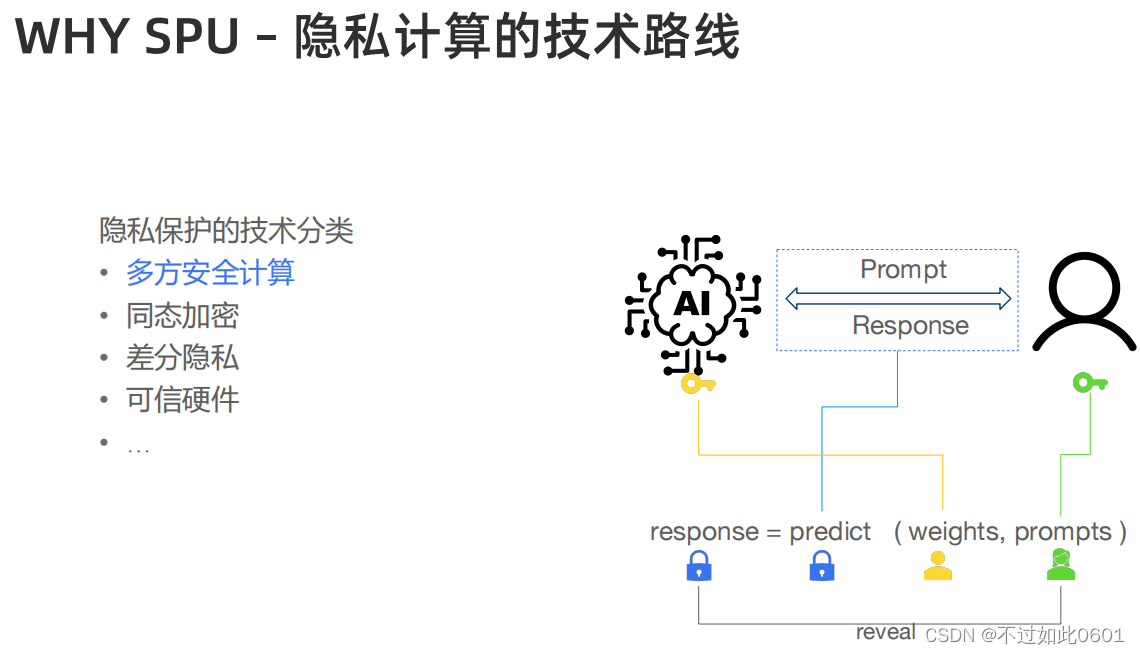
但是加密计算很有很多技术挑战,需要解决:
- 密码协议的易用性
- 工程实现上的方便性
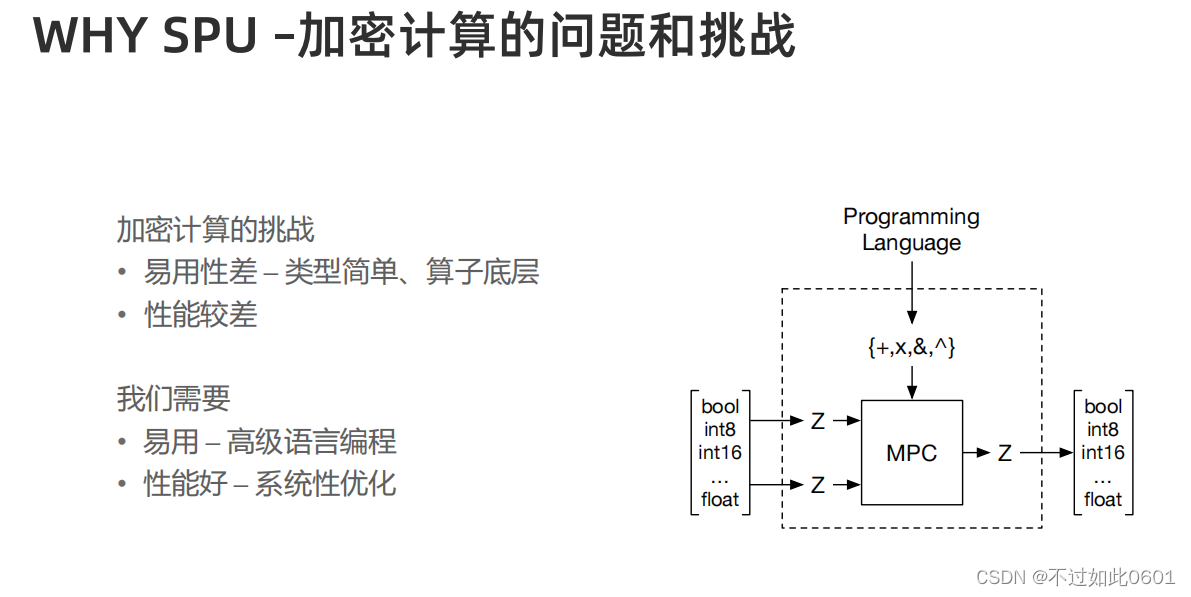
在这样的背景下,SPU诞生:
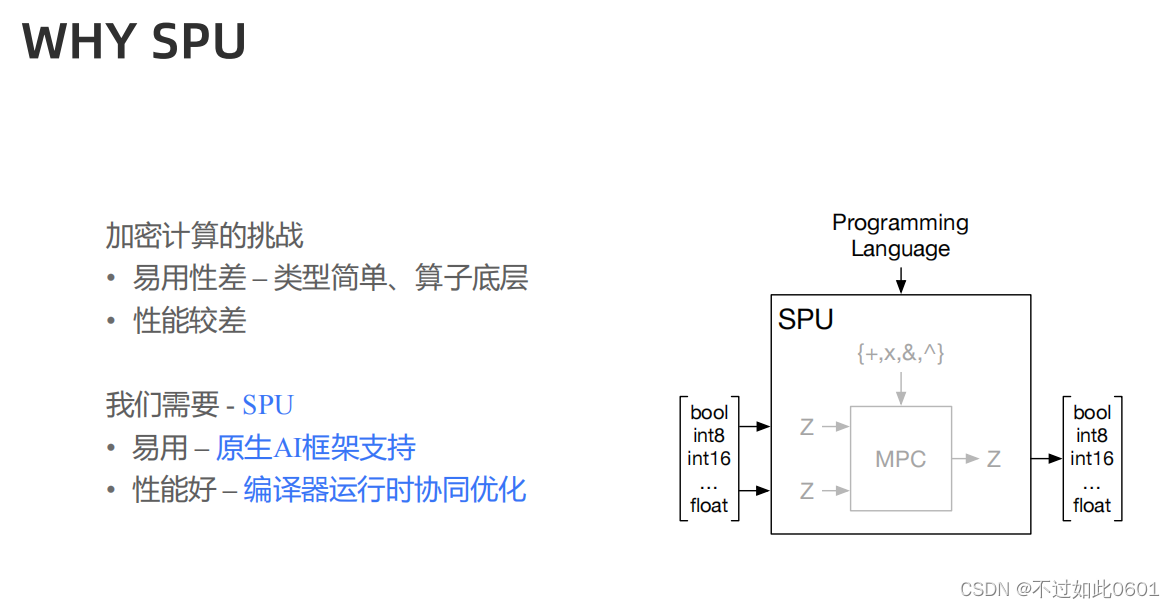
2 SPU简介
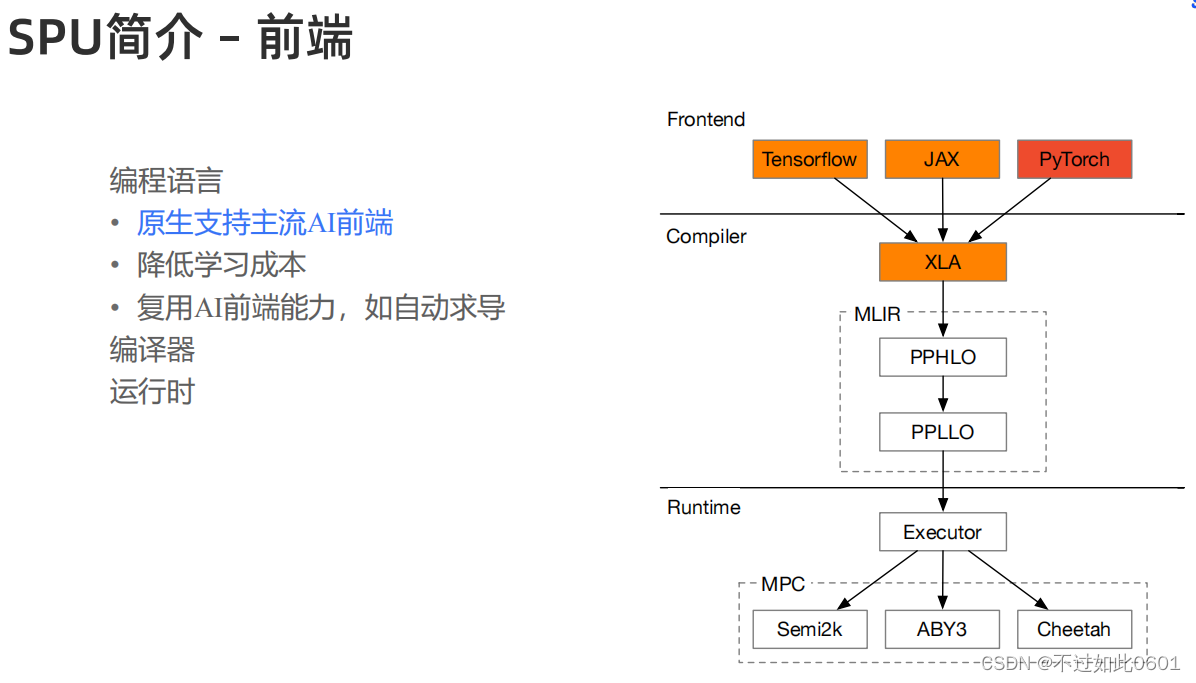
SPU主要关注前端编程环境、编译器和运行时三大方面。
前端尽量支持原生的AI编程以降低学习成本。
2.1 SPU前端
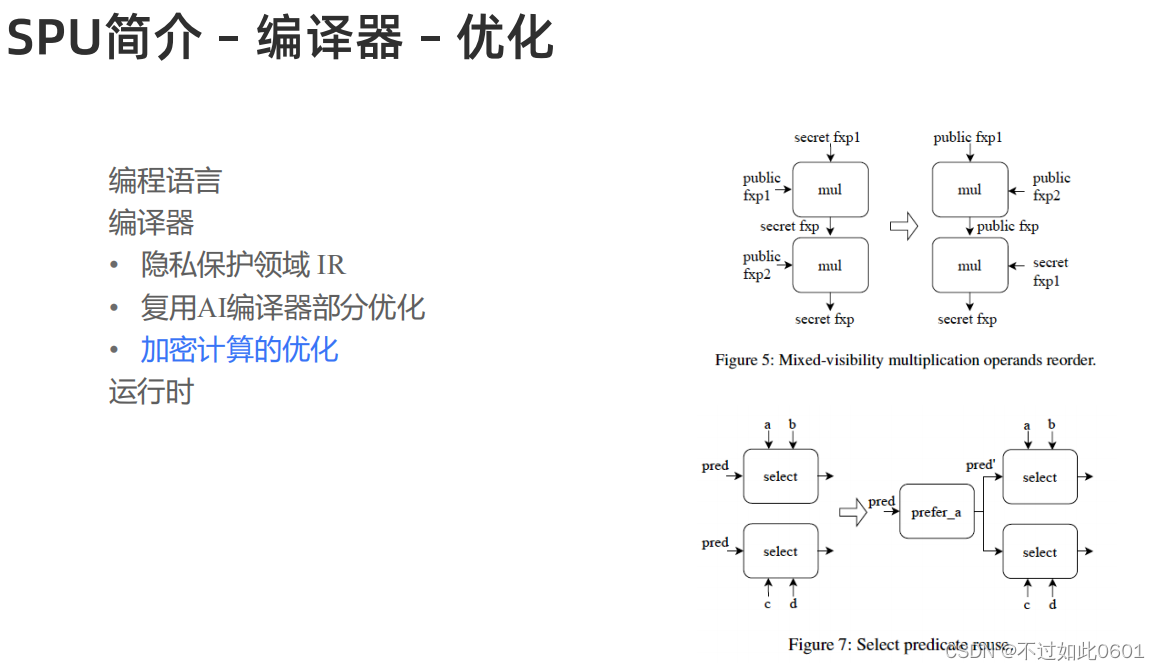
2.2 SPU编译器
然后,编译器将前端算子编译成密态形式的算子,并做了很多优化。

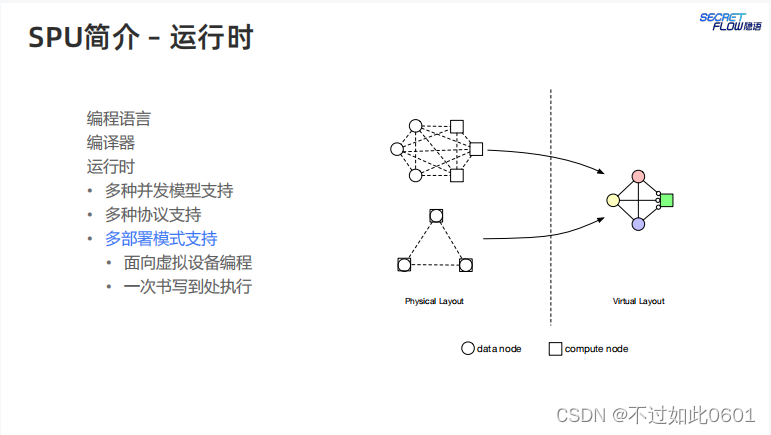
2.3 SPU运行时
最后,运行时阶段,支持多种并发模型、多种MPC协议,多种部署模式。

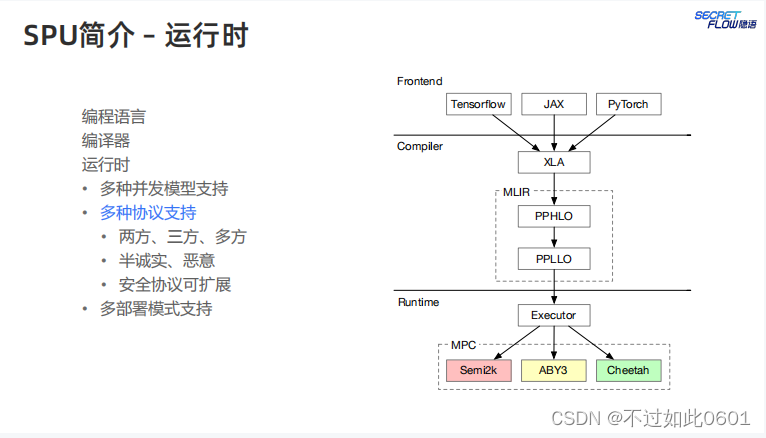
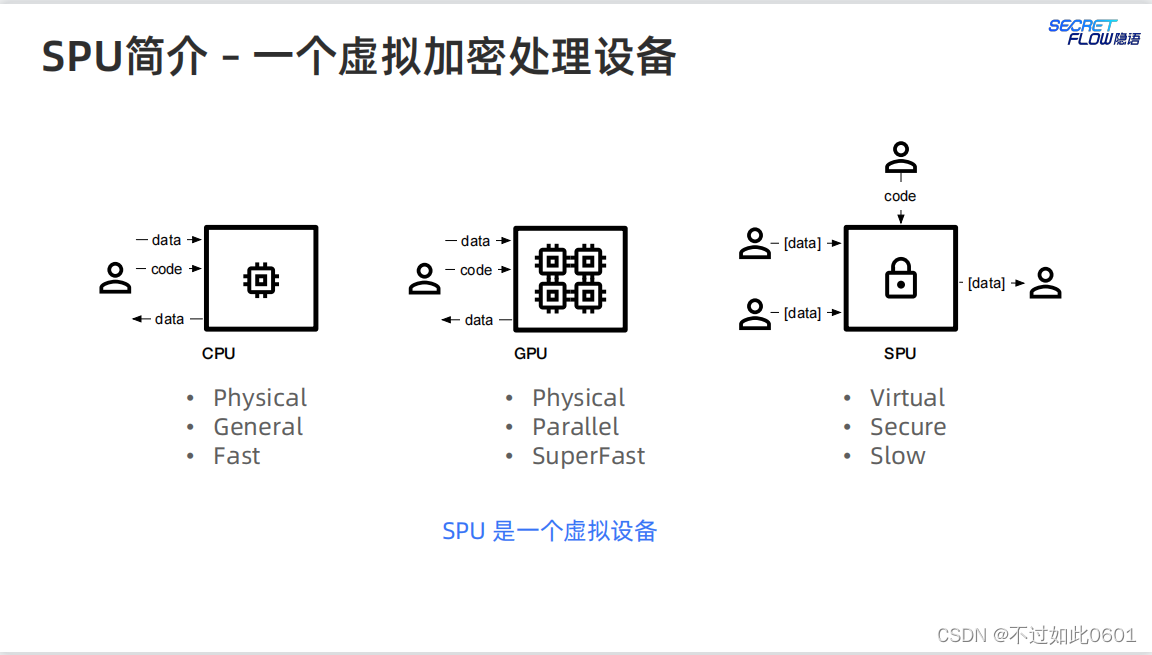
简单说来,SPU是一个虚拟的加密设备。
3 SPU编程界面
3.1 支持原生的AI框架编程
SPU支持原生的AI框架编程,方便地使用numpy,tensorflow等框架。

然后执行JIT编译:

3.2 支持大模型等生态应用
并且方便地支持大模型等生态应用:

SPU支持方便的协议配置更改和错误排查。


4 现状与展望
4.1 行业共建
SPU支持隐私保护机器学习PPML,支持联邦学习ML,支持SCQL.
4.2 学术支持
SPU在计算机系统领域、隐私保护机器学习、 密码协议创新等方面都有学术
前沿的研究和应用。

计算机视觉上的PPML:

大模型上的PPML:

SPU的目标是加速构建密态计算的生态。

5 个人小结
SPU底层以MPC协议为安全计算底座,上层通过编译器优化,能够很方便地
支持原生AI编程、支持大模型等生态应用,通过屏蔽底层MPC协议的复杂性,
大大降低了密态学习的成本,是行业领先的密态计算架构。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









