









一、机器环境
本地系统:windows 10
虚拟机:VMware Workstation Pro
虚拟系统:Centos 7.6 已配通NAT
SSH工具:XShell 6
Hadoop版本: 3.2.1
Java版本: JDK1.8
tips:若系统未配通NAT可参考
VMware——CentOS 7之NAT网络连接配置
二、准备工作
-
打开虚拟机登录系统并连接SSH
记得先打开CentOS系统在进行连接,忘记ip可使用ip addr查看第二项ens中的IP。 -
创建hadoop用户并设定密码
如果不是root账号,需要执行su命令以登录root账号。su # 上述提到的以 root 用户登录如果是root账号,只需要执行
useradd -m hadoop -s /bin/bash # 创建新用户hadoop密码设定,需输入2次,这里将密码设为hdfs2020(至少8个字符且不能过于简单,不能包含用户名),输入时密码不显示;
passwd hadoop


- 登录hadoop账号并检查SSH安装情况
输入su hadoop以登录hadoop账号。
输入ssh localhost,以下情况代表已安装SSH且可使用。
如果不是这种,请输入以下命令安装SSH,然后重新检查安装情况。
sudo yum install openssh-clients -y
sudo yum install openssh-server -y
- 配置SSH免密登录
由于每次登录都需要输入SSH密码,很麻烦,因此我们进行SSH免密登录配置。

输入 exit 以返回hadoop@localhost。
输入以下指令
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 出现输入提示,都按回车就可以

接着输入以下命令
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限
完成后,再输入ssh localhost,发现这次登录不用密码即代表成功。

- 安装Java环境
搜索JDK命令:yum search java | grep jdk
安装JDK命令:sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
检查java版本:

Tips:默认安装位置为/usr/lib/jvm/java-1.X.0-openjdk(这里X为8)
配置JAVA_HOME环境变量:
vim ~/.bashrc #编辑环境变量文件
输入环境变量保存并退出:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk

source ~/.bashrc # 使变量设置生效
echo $JAVA_HOME
出现以下结果表示JAVA环境配置完毕。

三、 Hadoop安装
-
快照
前面准备工作完成后,最好进行一次虚拟机快照。 -
Hadoop下载
镜像地址1:https://mirrors.cnnic.cn/apache/hadoop/common/
镜像地址2:
http://mirror.bit.edu.cn/apache/hadoop/common/
下载hadoop-x.y.z.tar.gz 这个文件。
包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。

- rz命令上传本地文件到虚拟机
若没有安装lrzsz可先执行命令
yum install lrzsz -y
然后进入到最高权限用户上传文件,文件将上传到当前目录下。

- 解压Hadoop
# 解压到/usr/local中
sudo tar -zxf ~/hadoop/hadoop-3.2.1.tar.gz -C /usr/local
检查Hadoop是否可用,若显示下图结果则表示正确。
cd /usr/local/hadoop-3.2.1
./bin/hadoop version

四、Hadoop伪分布式配置
-
伪分布式说明
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。 -
进行快照
此时机器上已安装好了Hadoop,为了防止配置错误找不到问题所在,需用重新安装的情况,这里进行一次快照比较保险。 -
配置Hadoop环境变量
vi ~/.bashrc
在文件中JAVA_HOME变量下面加入以下HADOOP_HOME内容,保存并退出。
export HADOOP_HOME=/usr/local/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
重启配置以生效。
source ~/.bashrc
- 修改配置文件
Hadoop配置文件位于 /usr/local/hadoop-3.2.1/etc/hadoop/
① 修改core-site.html文件内容为:
(记得按自己安装目录修改路径)
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.2.1/data/tmp</value> </property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
② 修改hdfs-site.xml文件内容为:
<configuration>
<!-- 副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 是否启用hdfs权限检查 false 关闭 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
③ 修改yarn-site.xml文件内容为:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> </property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
④ 修改mapred-site.xml文件内容为:
(记得按自己安装目录修改路径)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1/</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
</configuration>
⑤ 配置环境变量 hadoop-env.sh
在第54行左右,将 # export JAVA_HOME = 修改为:
export JAVA_HOME= /usr/lib/jvm/java-1.8.0-openjdk/

⑥ 配置环境变量 yarn-env.sh
在适当的位置手动加入JAVA_HOME路径

⑦ 配置/etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-3.2.1
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
记得 执行 source .profile 让配置立即生效。
- 克隆虚拟机并用XShell6连接

- 修改hosts文件(使用root账号,三台机都要,其实放在克隆前做更好)
ip地址要与主机对应好,三台主机hosts修改内容一样。
vim /etc/hosts

在Master主机下ping worker1和 worker2,若结果如下图则代表修改hosts完成。

Tips:使用crtl + c 或 crtl + z 来结束ping命令,否则会一直ping下去。
- 修改三台主机主机名(使用root账号)
# Master主机下
hostnamectl set-hostname master
# 两台Worker主机下
hostnamectl set-hostname worker1
hostnamectl set-hostname worker2
# 查看修改后hostname可直接输入
hostname
- 关闭防火墙(三台机都要,其实放在克隆前做更好)
#关闭防火墙指令
systemctl stop firewalld.service
#防火墙不自启动
systemctl disable firewalld.service
#查看防火墙状态指令两个选一个用
systemctl status firewalld
- 配置Master到Worker单向免密登录
ssh-copy-id worker1
ssh-copy-id worker2

#测试SSH免密连接
ssh worker1
ssh worker2

- 配置workers信息(三台机都要,其实放在克隆前完成会更方便,但放在后面做会更清晰)
# 修改workers文件, Hadoop2.X对应的是slaves文件
vim /usr/local/hadoop-3.2.1/etc/hadoop/workers
#添加内容
worker1
worker2
- 配置三台机器Hadoop 启动的系统环境变量(用一般账户,这里用我们创建的hadoop账户)
# 切换账户
su hadoop
# 编辑文件
vim ~/.bash_profile
# 添加以下内容到文件末尾,注意修改成自己的路径
#HADOOP
export HADOOP_HOME=/usr/local/hadoop-3.2.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 变量生效
source ~/.bash_profile

- 为三台机器创建数据目录
# 路径为core-site.xml配置文件中
#hadoop.tmp.dir指定的目录
mkdir -p /usr/local/hadoop-3.2.1/data/tmp
五、启动集群
- 格式化文件系统(在master主机上)
# hadoop用户下输入,若为产生Exception提示则成功格式化
# 建议成功格式化后进行虚拟机快照
hdfs namenode -format
在格式化文件系统时产生了异常,已解决。
主要是core-site.xml路径问题导致的异常,详情请看第六大项第一点。
- 启动Hadoop
# 进入Hadoop主目录
cd /usr/local/hadoop-3.2.1/
# 启动命令
sbin/start-all.sh
# jps命令查看运行情况
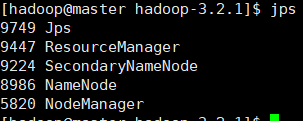
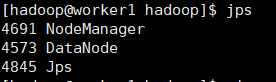
jps
master机结果:
worker机结果:
- 物理机访问WebUI
① 访问 http://masterip:9870

② 访问 http://masterip:8420

③ 访问 http://masterIp:8088

④ 未能成功在物理机上ping 通请看第六大点第三小点。
- 运行计算PI程序
[hadoop@master hadoop-3.2.1]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar pi 1 1

[hadoop@master hadoop-3.2.1]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar pi 3 3

这里用pi 1 1 和 pi 3 3来做结果检验,如果想要精度高一点可以使用pi 10 10
Tips:若出现未找到主类或加载主类失败异常,请看第六大点第五小点。
六、遇到的异常
-
core-site.xml与创建的数据目录不符合导致格式化失败

解决方法:检查core-site.xml中设置的目录和创建数据文件目录时的目录是否一致。
不一致则需修改路径或重新创建目录,所有主机都需要进行相同操作。 -
master也作为DataNode了

正常来说Master应该没有DataNode,想起在配置worker时没有删除掉localhost一项,可能是这个导致的。

解决方法:删除worker配置文件中localhost后,重新格式化并重新启动,其他两个worker节点的localhost不影响可不进行修改。
重新格式化前需关闭hadoop服务。
#进入Hadoop主目录后执行
sbin/stop-all.sh
修正后结果:

- 访问不了WebUI
- ip地址输错
- 未关闭虚拟机防火墙,物理机不必关
- 端口号错误(hadoop3.2.1 hdfs端口号为9870)
- hosts文件未配置ip地址转localhost
- 针对上面的第四点,配置ip地址转localhost
vim /etc/hosts

加入上面这句话就行,ip地址记得改为master主机的。
- 启动计算PI程序时显示加载主类失败
原因:
# 获取hadoop classpath
hadoop classpath

将下面的内容加到yarn-site.xml文件中
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop-3.2.1/etc/hadoop:/usr/local/hadoop-3.2.1/share/hadoop/common/lib/*:/usr/local/hadoop-3.2.1/share/hadoop/common/*:/usr/local/hadoop-3.2.1/share/hadoop/hdfs:/usr/local/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.2.1/share/hadoop/hdfs/*:/usr/local/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-3.2.1/share/hadoop/mapreduce/*:/usr/local/hadoop-3.2.1/share/hadoop/yarn:/usr/local/hadoop-3.2.1/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.2.1/share/hadoop/yarn/*</value>
</property>
关闭服务并重新开启服务。
# hadoop主目录下,hadoop账户下
bsin/stop-all.sh
bsin/start-all.sh
- JPS worker机没有DataNode

原因:执行文件系统格式化时,会在namenode数据文件夹中保存一个name/current/VERSION文件,记录namespaceID,标识了所格式化的 namenode的版本。如果频繁的格式化namenode,那么datanode中保存(即配置文件中dfs.data.dir在本地系统的路径)的data/current/VERSION文件只是你第一次格式化时保存的namenode的ID,因此就会造成datanode与namenode之间的id不一致。



解决方法:
查看master节点的clusterID并覆盖worker节点的clusterID,完成后关闭服务并重启。
[hadoop@worker2 hadoop-3.2.1]$ cd data/tmp/dfs/data/current/
[hadoop@worker2 current]$ vim VERSION
若仍不行就直接删除三台机器core-site.xml中定义的dfs.data.dir在本地系统的路径(此教程为/usr/local/hadoop-3.2.1/data/tmp),然后重新格式化文件系统。















 3204
3204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









