







一、基本介绍
1、 简介:在给定n个权值作为n个叶子节点,构造一颗二叉树,如果该二叉树的带权路径长度(wpl)达到最小,称为这样的树称为最优二叉树,也称赫夫曼树。赫夫曼树是带权路径最短的树,权值越大的结点离根结点最近。
2、 二叉树的路径长度:由根结点到所有叶子结点的路径长度之和。
3、 二叉树的带权路径长度:从根结点到各个叶子结点的路径长度与相应结点权值的乘积之和。
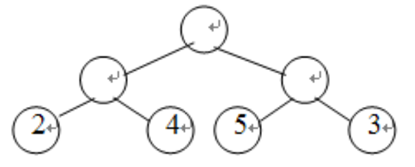
例如一下树的带权路径长度为:WPL=2 * 2 + 4 * 2 + 5 * 2 + 3 * 2 = 28
二、赫夫曼树的创建过程
在给定一个数组,{13,6,7,8,3,29,1}要求转为一颗赫夫曼树。大致过程如下:
1、将该数组按照升序进行排序,数组中的每个元素看做是二叉树中的一个结点。
2、取出两颗权值最小的二叉树组成一个新的二叉树,新的二叉树的权值就是前面取出的两颗二叉树权值之和。
3、将新的二叉树放入数组,同时移除原来的已经取出的两颗二叉树,将新的数组再次按照升序排序,重复1-2步,直到所有的数据都被处理,就可以得到赫夫曼树。
具体操作过程如下:
①、第一步,将其进行排序得到数组为:{1,3,6,7,8,13,29}
②、取出1和3组成新的树,得到一颗新的树,权值为4,将4放入数组中,此时得到的排序数组为{4,6,7,8,13,29},
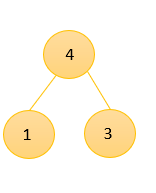
③、取出4和6,得到新的二叉树10,再次将10放入数组中得到新的排序数组为:{7,8,10,13,29}
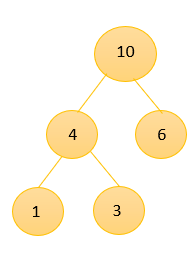
④、取出7和8组成新的树权值为15,并且将该树放入数组中,此时的数组为{10,13,15,29}
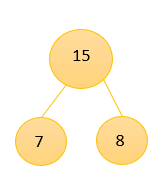
⑤、取出10和13进行组合。得到新的二叉树,权值为23,将该树放入数组中,此时数组为{15,23,29}。
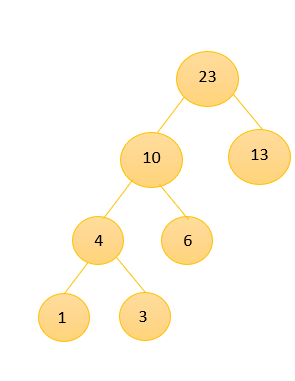
⑥,取出15和23组成新的二叉树,得到新的树,权值为38,最后在将29和38进行组合,最终得到的赫夫曼树为:

三、代码实现
1、结点类数据结构
/**
* 创建一个节点类,并且实现Comparable接口,重写compareTo(Node o)方法。实现此接口的对象列表和数组可以进行排序,
* 通过Collections.sort()或者Arrays.sort()方法
*/
public class Node implements Comparable<Node> {
private int value; // 结点权值
private char c; //字符
private Node left; // 指向左子结点
private Node right; // 指向右子结点
//省略get和set方法
public Node(int value) {
this.value = value;
}
//前序遍历
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
@Override
public String toString() {
return value + " ";
}
/**
*将此对象与指定的order对象进行比较。返回一个负整数、零或正整数作为这个对象小于、等于或大于指定的对象。
* @param o 被比较的对象
* @return
*/
@Override
public int compareTo(Node o) {
// 表示从小到大排序
return this.value - o.value;
}
}
//测试类
public class HuffmanTreeDemo {
public static void main(String[] args) {
int arr[] = {13,7,8,3,29,6,1};
Node root = createHuffmanTree(arr);
root.preOrder();
}
/**
*
* @param arrays 数组元素结点
*/
public static Node createHuffmanTree(int[] arrays){
//1、将该数组中的元素,转为一个个的结点
List<Node> nodes = new ArrayList<>();
for (int arr : arrays) {
nodes.add(new Node(arr));
}
//最终该列表中只会剩余一颗根树,所以只要列表中的数据大于1,都需要循环处理
while (nodes.size() > 1){
//将该nodes排序
Collections.sort(nodes);
//取出最小的两颗树
Node left = nodes.get(0);
Node right = nodes.get(1);
//构造新的二叉树
Node parent = new Node(left.getValue() + right.getValue());
parent.setLeft(left);
parent.setRight(right);
//删除取出的两个节点
nodes.remove(left);
nodes.remove(right);
//将新构造的结点加入到列表中
nodes.add(parent);
}
return nodes.get(0);
}
}
前序遍历输出结果为:

四、赫夫曼树的应用
在数据通讯中,经常需要将传送的文字转换成由二进制字符0,1组成的二进制串,我们称之为编码。
例:如果需传送的电文为 ‘ABACCDA’,它只用到四种字符,若采用下面的编码方式(这是一种等长编码):

实际应用中各字符的出现频度不相同,用短(长)编码表示频率大(小)的字符,使得编码序列的总长度最小。
我们应该注意一点是:编码不能具有二义性,即任一个字符的编码都不是另一个字符的编码的前缀。例如:

赫夫曼树中的左分支代表0,右分支代表1,这样从根结点到每个叶子结点所经过的路径分支组成的0和1的序列便为该结点对应字符的编码,我们称之为赫夫曼编码。
在赫夫曼编码树中,树的带权路径长度的含义是各个字符的码长与其出现次数的乘积之和,也就是电文的代码总长,所以采用赫夫曼树构造的编
码是一种能使电文代码总长最短的不等长编码。
换言之,就是统计各个字符在报文中出现的次数,将该次数作为权值。构造赫夫曼树。最后在统计每个字符的编码。
例如:要传送的电文是{CAS;CAT;SAT;AT}
各个字符出现的次数为:C:2,A:4,T:3,;:3,S:2。最终构造出的赫夫曼树和对应字符编码为:
















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









