






一、全局锁(Flush tables with read lock (FTWRL))
全局锁是在整个数据库实例上加锁,使得在锁定期间,除了持有全局锁的线程外,其他线程不能对数据库进行写操作,包括数据的增删改以及表结构的更改操作。全局锁通常用于需要对整个数据库进行一致性备份的场景,以确保备份的数据在逻辑上是一致的。
二、表级别锁
1、表锁
锁定整个表,而不是单个行或页,语法:lock tables … read/write
表锁的类型包括:
● 共享读锁(Shared Read Locks):多个线程可以同时对表进行读取操作,但不能进行写操作。
● 排他写锁(Exclusive Write Locks):只允许一个线程对表进行写操作,其他线程的读写操作都会被阻塞。
2、元数据锁(MDL锁)
元数据锁通常是自动管理的,不需要用户显式操作。当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。这是为了防止在对数据库做增删查改时,对表结构发生变更,导致数据不一致的问题。
三、行锁
一、行锁的三种算法
假设我们有如下表结构和数据,我们给t2加上索引。
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`t1` int(11) NULL DEFAULT NULL,
`t2` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_t2`(`t2`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = DYNAMIC;
INSERT INTO `demo`.`test` (`id`, `t1`, `t2`) VALUES (1, 530, 'a1');
INSERT INTO `demo`.`test` (`id`, `t1`, `t2`) VALUES (2, 630, 'a10');
INSERT INTO `demo`.`test` (`id`, `t1`, `t2`) VALUES (3, 830, 'a50');
INSERT INTO `demo`.`test` (`id`, `t1`, `t2`) VALUES (4, 930, 'a100');
假设我们要更新t2 介于a1和a10之间的数据
update test set t1 = 640 where t2 <= 'a10' and t2 >= 'a1';
为了保证更新数据的一致性,不会出现多个线程更新同一条数据导致的并发问题,更新时那肯定需要将t2介于这个区间内的每条数据都加锁。这就是:
1、Record Lock:单个行记录上的锁。
我们的确锁定了每条索引记录,其他线程对该条记录的修改都需要等待当前线程释放锁。但是,t2列的每个数据之间,是有间隙的,这并不能防止其他线程插入记录。
如图:
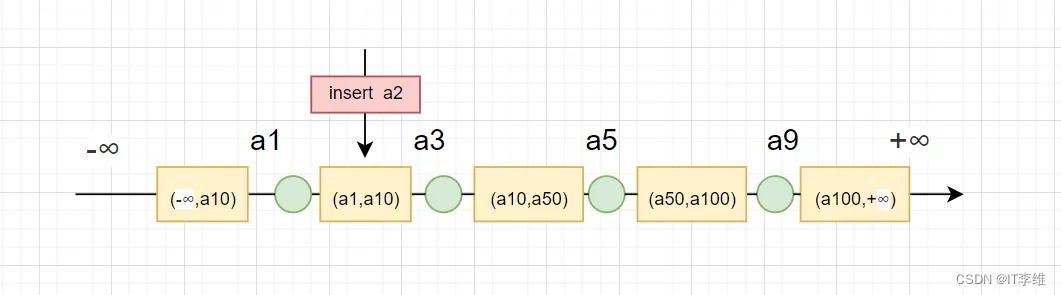
如果在执行业务过程中插入了a2这条数据,两次查询条件的数据条数,并不一致,这就是幻读,所以为了解决这个问题,我们不仅要锁定记录本身,还需要锁定再查找数据过程中,遍历过的间隙,这就是:
2、Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
而Gap Lock和Record Lock的组合就是:
3、 Next-Key Lock∶Gap Lock+Record Lock。这也是INNODB引擎加锁的默认单位。官方的解释是说,在给索引记录加锁的同时,会给当前索引与前一个索引之间的间隙加锁,所以其加锁规则是前开后闭区间,也就是说,在上图中next-key lock锁定范围可能是:(-∞,a1]、(a1,a3]、(a3,a5]、(a5,a9]、(a9,+∞)。
二、关于索引和行锁
为什么行锁要基于索引?
- 提高锁定的精确度:基于索引的行锁可以锁定表中特定的行,而不是整个表或多个行。这样可以减少锁定的范围,提高并发性能。
- 提高性能:索引通常用于快速定位数据,基于索引的行锁可以更快地确定哪些行需要被锁定,从而减少锁定操作的时间。
- 利用索引的有序性:索引是有序的,这使得基于索引的行锁可以更有效地管理锁定的行。例如,在范围查询中,可以利用索引的有序性来锁定一个范围内的所有行。
- 减少锁定开销:如果行锁不基于索引,数据库系统可能需要扫描整个表来确定哪些行需要被锁定,这会增加锁定的开销。基于索引的行锁可以直接定位到索引中的特定位置,减少这种开销。
三、演示
我们先对加锁的过程进行大致的说明,在结合官方文档中说明:
查询索引顺序,本文示例如上图。
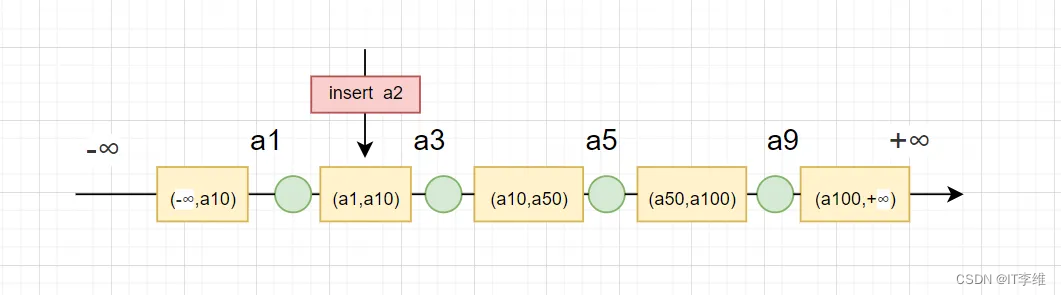
规则1、看查询条件,看查询条件包含哪些索引记录,给每个索引记录加上next-key lock。
规则2、为了防止幻读,需要找到第一个不符合索引查询条件的索引记录加next-key lock。
规则3、给符合查询条件的所有记录的主键,加上记录锁。有同学可能会产生疑问,不是都给使到的索引加锁了吗,为什么还要给每个主键索引加锁?
这是因为,非聚集索引的锁,并不能控制这条数据的其他字段不被更新。比如,给t2=a5的记录加了锁,只是锁定了t2这个索引,如果不给主键索引加锁,别的线程通过update test set t1=300 where id=3修改这一列的值。这就会导致数据不一致。如果每个索引的加锁规则都会给主键加锁,那其他线程的修改申请会被阻塞。
现在我们举个例子分析:
start TRANSACTION;
select * from test where t2 <= 'a3' for update;
t2 <=a3,
根据规则1:符合条件的记录为:a1,a3。所以会给这两个记录加上next-key lock,
根据规则2,向右寻找第一个不满足条件的记录a5加上next-key lock。
根据规则3,给t2为a1和a3记录的主键索引加锁。所以经过分析,这条sql一共有5把行锁,一把表的意向锁(意向排他锁是一种表级别的锁,它表明持有该锁的事务打算在表中的某些行上获取排他锁。)。
我们查询一下performance_schema.data_locks,这张表记录了锁的信息。
SELECT ENGINE
,
ENGINE_LOCK_ID,
ENGINE_TRANSACTION_ID,
THREAD_ID,
OBJECT_NAME,
INDEX_NAME,
LOCK_TYPE,
LOCK_MODE,
LOCK_DATA
FROM
`performance_schema`.data_locks
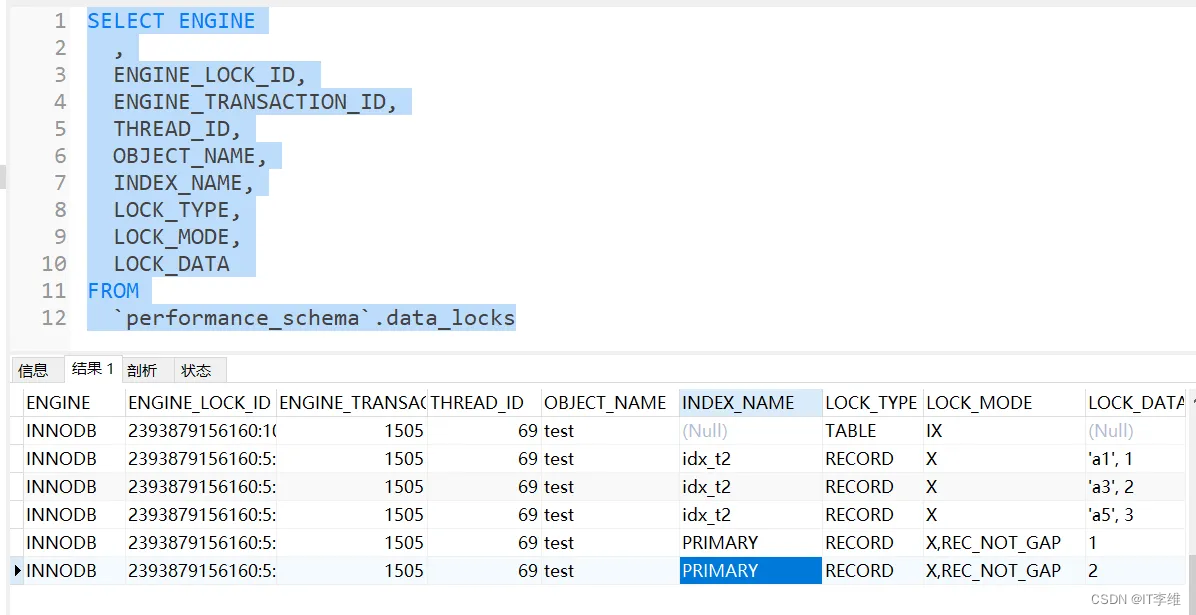
符合预期。
LOCK_MODE字段枚举为:
● IX:代表意向排他锁。
● X:代表Next-Key Lock锁定记录本身和记录之前的间隙(X)。
● S:代表Next-Key Lock锁定记录本身和记录之前的间隙(S)。
● X, REC_NOT_GAP:代表只锁定记录本身(X)。
● S, REC_NOT_GAP:代表只锁定记录本身(S)。
● X, GAP:代表间隙锁,不锁定记录本身(X)。
● S, GAP:代表间隙锁,不锁定记录本身(S)。
● X, GAP, INSERT_INTENTION:代表插入意向锁。
MySQL对锁的优化:
1、锁降级:如果查询包括唯一索引,那么next-key lock会被优化成record lock。这是因为根据唯一索引,就已经能够锁定一条记录了,而非聚集索引就不行。
start TRANSACTION;
select * from test where t2 <='a3' and id=1 for update;
这是,只会存在两把锁,表的意向排他锁,主键索引的记录锁。如图:
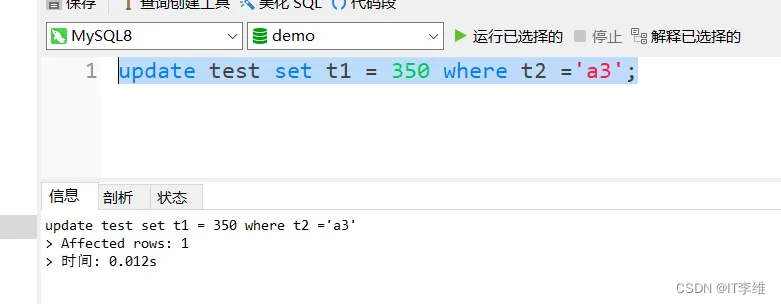
所以,此时我们运行如下更新SQL是被允许的
update test set t1 = 350 where t2 ='a3';
2、等值查询优化,根据规则2,给下一个不符合查询条件的记录加上的next-key lock会优化成间隙锁。
start TRANSACTION;
select * from test where t2 ='a3' for update;
此时会给a3加上Next-key lock,锁定区间为:(a1,a3],由于是等值查询,所以,给a5加上的next-lock会退化成间隙锁。所以此时一共存在4把锁:
1把表的排他意向锁,1把next-key lock,1把间隙锁,1把主键索引的record lock。
我们查询一下锁的信息
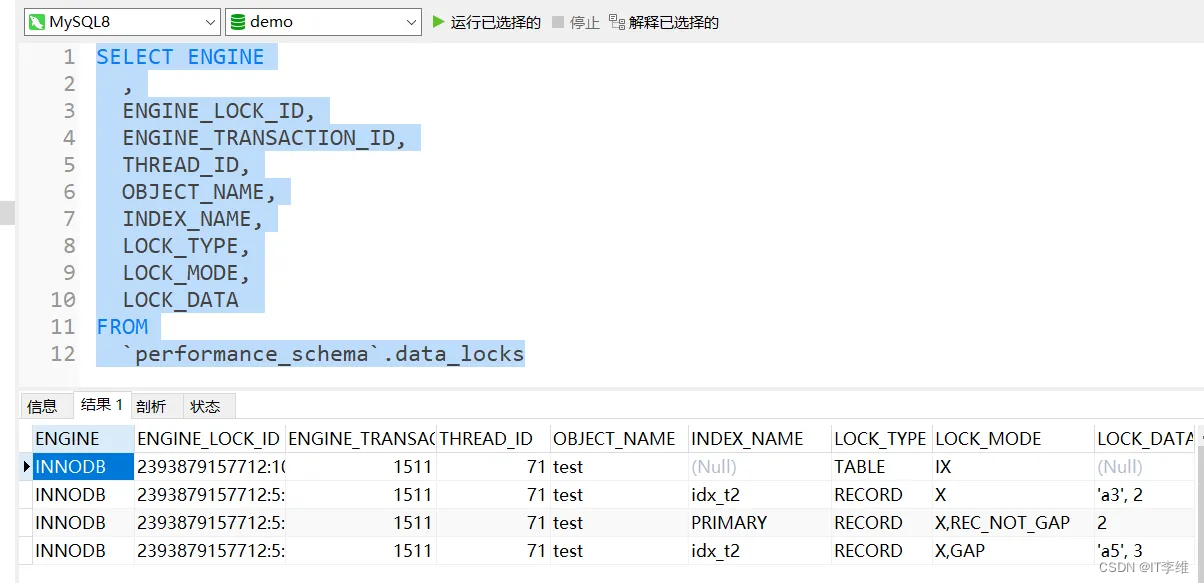
符合预期。
3、无需访问的数据不需要加锁。根据规则2,我们为什么要给主键索引增加锁,我们现在来看一个示例
会话1,注意,我们这儿用的是读锁
start TRANSACTION;
select t2 from test where t2 <='a3' lock in share mode;
我们查看一下锁的信息。
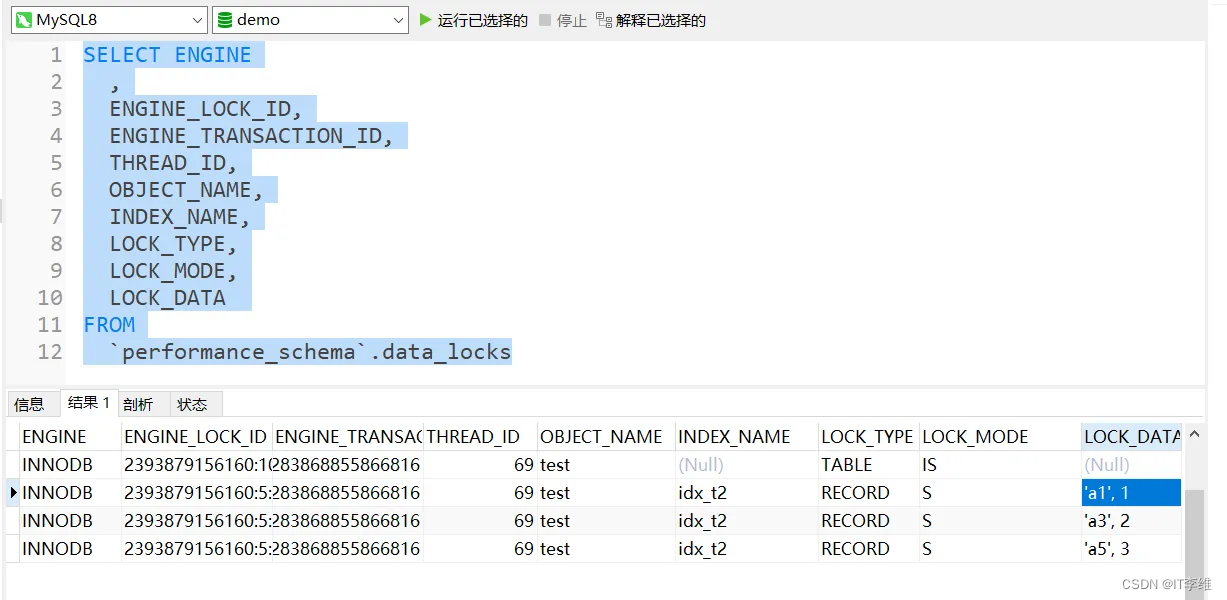
???我们主键索引上的锁哪儿去了呢?
其实这是因为,我们这个SQL使用了覆盖索引,索引上的字段就已经能够满足查询需求了,其他字段的变化,与本次查询无关。比如执行update test set t1=300 where id=3,就算t1变化了对本次查询也没有影响。
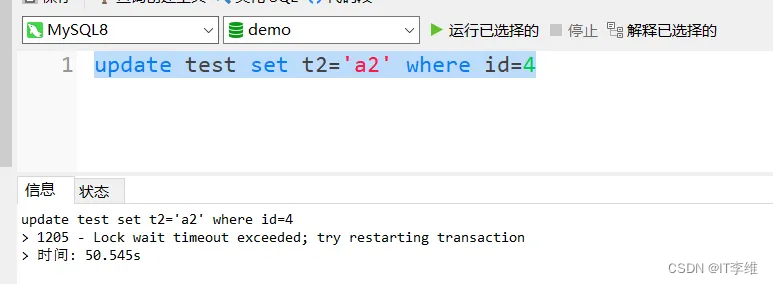
而假设有线程执行语句update test set t2=‘a2’ where id=4,因为修改字段会涉及到索引的重排序,此时向idx_t2这个索引中插入a2这个值,就会被锁住。也能保证我们结果的正确性
最后,我们再说明一下,对于多个索引的情况,我们按照规则依次加锁即可。大家可以自行去尝试和分析。


















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









