







出处
论文发表于CVPR 2021
论文地址:点击
论文代码:点击
问题
-
背景:深度神经网络容易受到对抗样本的攻击,这些攻击通过不可察觉的扰动欺骗模型。
-
解决的问题:虽然白盒攻击已经取得了惊人的成功率,但大多数现有的攻击在黑盒情况下往往表现出较弱的迁移性,特别是在攻击具有防御机制的模型时。
-
提出的方法:在本文中,我们提出一种名为方差调整的新方法,来增强迭代梯度攻击方法的攻击迁移能力。具体而言,在每次梯度计算的迭代中,我们并非直接使用当前梯度进行动量累积,而是进一步考虑上一次迭代的梯度方差,以调整当前梯度,从而稳定更新方向,并摆脱贫困局面。
-
实验结果:基于标 ImageNet数据集的实证结果表明,我们的方法可以显著提高梯度攻击的迁移能力。此外,我们的方法可用于攻击集成模型或与各种输入变换集成。将方差调整与输入变换相结合的迭代梯度攻击多模型集成方法可以对九种先进的防御方法产生平均成功率为90.1%,将当前最佳攻击性能显着提高了85.1%。
方法
该论文提出的攻击算法,是在mi-fgsm的基础上进行改进,防止寻找最优参数时限于局部最优。具体改进如下:
-
对前一数据点进行均匀采样
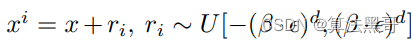
-
对采到的样本求近似方差
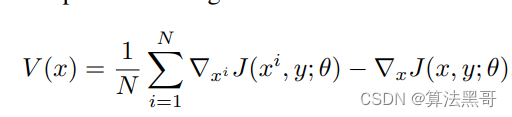
-
用方差优化当前梯度
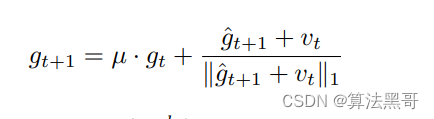
- 伪代码图如下

代码
参考我的github















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









