







- 传统人脸检测算法
利用手工特征+分类器,以滑窗方式在图像金字塔上遍历所有位置和大小,进行人脸检测
Viola-Jones算法:
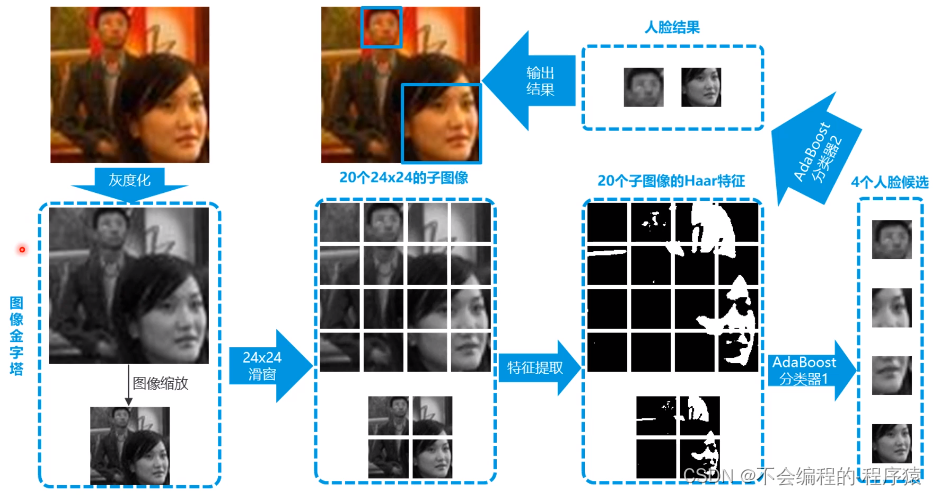
Viola-Jones算法三个最重要的点:
- Hear特征,一个非常高效特征
- AdaBoost构建分类器
- 分类器1和分类器2是级联的结构
深度学习早期人脸检测算法:

| 滑窗 | 滑窗操作遍历所有的位置 |
|---|---|
| 金字塔 | 图像金字塔遍历所有的大小 |
| 级联 | 3个级联的阶段,人脸数量从多到少,人脸难度从易到难,网络结构从简单到复杂 |
| 深度学习 | 利用深度学习中的神经网络进行特征提取+分类器+矫正器+其他 |
| 优点 | 有着满足实际需求的精度,具备CPU实时的速度 |
| 缺点 | 1. 局部最优:三个独立的阶段,容易取得局部最优而非全局最优; 2. 训练繁琐:训练不是端到端的,每个段单独处理,非常繁琐 3. 检测速度:检测速度与图像上人脸的数量高度相关 4. 检测精度:在复杂的场景下,检测精度不能够满足性能的需求 |
| 总结 | 深度学习早期人脸检测算法的代表,开创了深度学习时代下,人脸检测的一个派系,很多实际场景中都在使用该类型的算法 |
深度学习后期人脸检测算法:对通用物体检测算法进行相应改进,应用于人脸检测领域
高效率的人脸检测算法
- 基础网络为专门设计的轻量级的网络结构。
- 在实际场景中,检测大于30个像素的人脸,有着满足需求的检测精度
- 能够在资源受限的前端设备 (CPU、ARM、FPGA等)上实时的运行.
- 追求检测速度和检测精度的平衡,满足实用性
高效率算法: 由于资源受限,只需要在正常场景下满足精度需求 (人脸>30个像素,背景比较简单)
高精度的人脸检测算法
- 基础网络为重量级的VGG16或ResNet-50/101/152等
。 - 在复杂场景下,有着非常高的检测精度,非常小的人脸也能检测·
- 可以在高性能的GPU设备上实时的运行
·追求极致的检测精度,检测速度可以不考虑
高精度算法: 由于资源充足,需要在所有场景下都满足精度需求(任何尺度人脸,背景非常复杂)
FaceBox结构:
SFD&SFDet
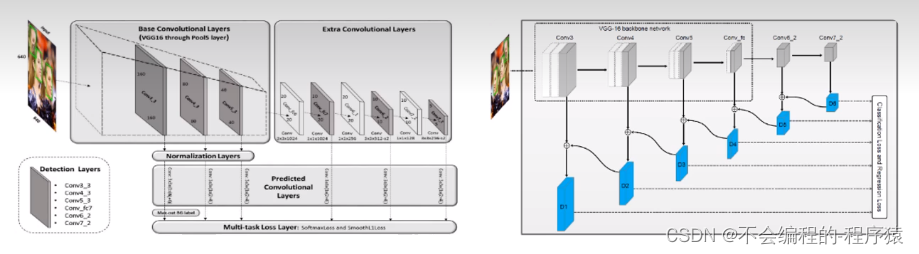
- 尺度上公平的检测框架
利用感受野理论设计锚框大小,同时提出等比间隔原则,辅助锚框所铺设的检测层的选取。 - 尺度补偿的锚框匹配策略
在传统的锚框匹配结束后,增加了一轮锚框的匹配,通过增加的一轮锚框匹配将没有匹配到充足正样本的人脸找到,通过放低匹配的条件阈值,使得人脸能够匹配到更多的正样本,从而提高召回率。 - 背景标签输出最大化操作
能够有效降低小尺度锚框造成的虚检,把一些弱的背景小分类器集成一个强的背景标签类别,从而降低虚检。
SRN & RefineFace
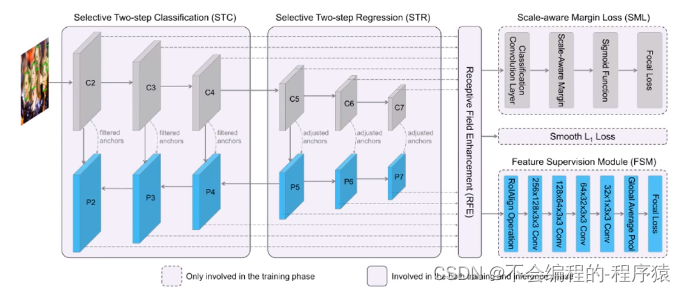
- 选择性二阶段分类
只在检测层的前三个层做二阶段的分类 - 选择性二阶段回归
只在检测层的后三个层做二阶段的回归 - 感受野增强模块
- 尺度敏感的margin损失函数
- 特征监督模块

















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









