







线性回归、Softmax与分类模型、多层感知机
线性回归
任务目标
我们假设房屋价格取决于房屋面积与房屋年龄,则假设他服从一个线性关系:
p
r
i
c
e
=
w
a
r
e
a
⋅
a
r
e
a
+
w
a
g
e
⋅
a
g
e
+
b
\mathrm{price} = w_{\mathrm{area}} \cdot \mathrm{area} + w_{\mathrm{age}} \cdot \mathrm{age} + b
price=warea⋅area+wage⋅age+b
我们的目的就是求得其中的参数
w
a
r
e
a
w_{\mathrm{area}}
warea和
w
a
g
e
w_{\mathrm{age}}
wage
数据集
我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。
损失函数
损失函数用于评价真实值与预测值之间的误差,有许多种形式。这里使用均方误差作为损失函数,即:
l
(
i
)
(
w
,
b
)
=
1
2
(
y
^
(
i
)
−
y
(
i
)
)
2
,
l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2,
l(i)(w,b)=21(y^(i)−y(i))2,
L
(
w
,
b
)
=
1
n
∑
i
=
1
n
l
(
i
)
(
w
,
b
)
=
1
n
∑
i
=
1
n
1
2
(
w
⊤
x
(
i
)
+
b
−
y
(
i
)
)
2
.
L(\mathbf{w}, b) =\frac{1}{n}\sum_{i=1}^n l^{(i)}(\mathbf{w}, b) =\frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2.
L(w,b)=n1∑i=1nl(i)(w,b)=n1∑i=1n21(w⊤x(i)+b−y(i))2.
我们通过优化损失函数即可求得参数
w
a
r
e
a
w_{\mathrm{area}}
warea和
w
a
g
e
w_{\mathrm{age}}
wage,那么这就成了一个简单的优化问题。
优化函数 - 随机梯度下降
在此使用小批量的随机梯度下降。梯度下降使用所有样本的平均梯度(导数)进行优化,小批量随机梯度下降则是每次随机选取一小批量的样本进行优化。其优化公式:
(
w
,
b
)
←
(
w
,
b
)
−
η
∣
B
∣
∑
i
∈
B
∂
(
w
,
b
)
l
(
i
)
(
w
,
b
)
(\mathbf{w},b) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{(\mathbf{w},b)} l^{(i)}(\mathbf{w},b)
(w,b)←(w,b)−∣B∣η∑i∈B∂(w,b)l(i)(w,b)
学习率:
η
\eta
η代表在每次优化中,能够学习的步长的大小
批量大小:
B
\mathcal{B}
B是小批量计算中的批量大小batch size
总结一下,优化函数的有以下两个步骤:
·(i)初始化模型参数,一般来说使用随机初始化;
·(ii)我们在数据上迭代多次,通过在负梯度方向移动参数来更新每个参数。
(线性回归实现代码见上篇,由于贴到博客太费时间,后面部分不再分析)
Softmax与分类模型
任务目标
上面线性回归是一个回归问题,下面引入SoftMax来解决分类问题。
这里使用Fashion-MNIST训练集,见下图。
 其输入一个图片,模型判断其类别。
其输入一个图片,模型判断其类别。
一个简单的图像分类问题,输入图像的高和宽均为2像素,色彩为灰度。我们将图片从高宽两维,按像素灰度变为数字量形式,之后便可以使用线性模型。图像中的4像素分别记为
x
1
,
x
2
,
x
3
,
x
4
x_1, x_2, x_3, x_4
x1,x2,x3,x4。
假设真实标签只有三类,
y
1
,
y
2
,
y
3
y_1,y_2,y_3
y1,y2,y3。那么线性模型可以写为:
o
1
=
x
1
w
11
+
x
2
w
21
+
x
3
w
31
+
x
4
w
41
+
b
1
\begin{aligned} o_1 &= x_1 w_{11} + x_2 w_{21} + x_3 w_{31} + x_4 w_{41} + b_1 \end{aligned}
o1=x1w11+x2w21+x3w31+x4w41+b1
o
2
=
x
1
w
12
+
x
2
w
22
+
x
3
w
32
+
x
4
w
42
+
b
2
\begin{aligned} o_2 &= x_1 w_{12} + x_2 w_{22} + x_3 w_{32} + x_4 w_{42} + b_2 \end{aligned}
o2=x1w12+x2w22+x3w32+x4w42+b2
o
3
=
x
1
w
13
+
x
2
w
23
+
x
3
w
33
+
x
4
w
43
+
b
3
\begin{aligned} o_3 &= x_1 w_{13} + x_2 w_{23} + x_3 w_{33} + x_4 w_{43} + b_3 \end{aligned}
o3=x1w13+x2w23+x3w33+x4w43+b3
神经网络图
下图用神经网络图描绘了上面的计算。softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出
o
1
,
o
2
,
o
3
o_1, o_2, o_3
o1,o2,o3的计算都要依赖于所有的输入
x
1
,
x
2
,
x
3
,
x
4
x_1, x_2, x_3, x_4
x1,x2,x3,x4,softmax回归的输出层也是一个全连接层。
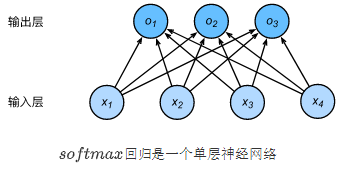
我们将输出值
o
i
o_i
oi当作预测类别是
i
i
i的置信度,并将值最大的输出所对应的类作为预测输出,即输出
arg
max
i
o
i
\underset{i}{\arg\max} o_i
iargmaxoi.
SoftMax
· 输出问题
直接使用输出层的输出有两个问题:
1.一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果o1=o3=103,那么输出值10却又表示图像类别为猫的概率很低。
2.另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符则解决上述两个问题,他在输出层增加运算:
y
^
1
,
y
^
2
,
y
^
3
=
softmax
(
o
1
,
o
2
,
o
3
)
\hat{y}_1, \hat{y}_2, \hat{y}_3 = \text{softmax}(o_1, o_2, o_3)
y^1,y^2,y^3=softmax(o1,o2,o3)
他将输出值变换为正且和为1的概率分布
其中:
y
^
1
=
exp
(
o
1
)
∑
i
=
1
3
exp
(
o
i
)
,
y
^
2
=
exp
(
o
2
)
∑
i
=
1
3
exp
(
o
i
)
,
y
^
3
=
exp
(
o
3
)
∑
i
=
1
3
exp
(
o
i
)
.
\hat{y}1 = \frac{ \exp(o_1)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}2 = \frac{ \exp(o_2)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}3 = \frac{ \exp(o_3)}{\sum_{i=1}^3 \exp(o_i)}.
y^1=∑i=13exp(oi)exp(o1),y^2=∑i=13exp(oi)exp(o2),y^3=∑i=13exp(oi)exp(o3).
损失函数
在此使用交叉熵损失函数:
ℓ
(
Θ
)
=
1
n
∑
i
=
1
n
H
(
y
(
i
)
,
y
^
(
i
)
)
,
\ell(\boldsymbol{\Theta}) = \frac{1}{n} \sum_{i=1}^n H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ),
ℓ(Θ)=n1∑i=1nH(y(i),y^(i)),
其中交叉熵:
H
(
y
(
i
)
,
y
^
(
i
)
)
=
−
∑
j
=
1
q
y
j
(
i
)
log
y
^
j
(
i
)
,
H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ) = -\sum_{j=1}^q y_j^{(i)} \log \hat y_j^{(i)},
H(y(i),y^(i))=−∑j=1qyj(i)logy^j(i),
多层感知机
单层感知机用于分类问题,在两类样本中找一条直线,直线上下分别为不同两类。
任务目标
同样使用Fashion-MNIST训练集,解决分类问题。
隐藏层

上图网络第一层为输入层,最后一层为输出层,中间为隐藏层。上图表示的表达式为:
H
=
X
W
h
+
b
h
,
O
=
H
W
o
+
b
o
,
\begin{aligned} \boldsymbol{H} &= \boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h,\\ \boldsymbol{O} &= \boldsymbol{H} \boldsymbol{W}_o + \boldsymbol{b}_o, \end{aligned}
HO=XWh+bh,=HWo+bo,
我们若将两式联立,可得出:
O
=
(
X
W
h
+
b
h
)
W
o
+
b
o
=
X
W
h
W
o
+
b
h
W
o
+
b
o
.
\boldsymbol{O} = (\boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h)\boldsymbol{W}_o + \boldsymbol{b}_o = \boldsymbol{X} \boldsymbol{W}_h\boldsymbol{W}_o + \boldsymbol{b}_h \boldsymbol{W}_o + \boldsymbol{b}_o.
O=(XWh+bh)Wo+bo=XWhWo+bhWo+bo.
不难看出,虽然引入了多层,但是其表达仍是一个线性关系,与单层效果相同,所以我们引入激活函数,使其进行非线性变换。
激活函数
我们在上面两个函数间增加一个激活函数,下面介绍常用的三个激活函数:ReLU、Sigmoid、tanh
ReLU
ReLU
(
x
)
=
max
(
x
,
0
)
\text{ReLU}(x) = \max(x, 0)
ReLU(x)=max(x,0)

Sigmoid
sigmoid
(
x
)
=
1
1
+
exp
(
−
x
)
\text{sigmoid}(x) = \frac{1}{1 + \exp(-x)}
sigmoid(x)=1+exp(−x)1

tanh
tanh
(
x
)
=
1
−
exp
(
−
2
x
)
1
+
exp
(
−
2
x
)
\text{tanh}(x) = \frac{1 - \exp(-2x)}{1 + \exp(-2x)}
tanh(x)=1+exp(−2x)1−exp(−2x)

激活函数的选择
ReLu函数是一个通用的激活函数,目前在大多数情况下使用。但是,ReLU函数只能在隐藏层中使用。用于分类器时,sigmoid函数及其组合通常效果更好。由于梯度消失问题,有时要避免使用sigmoid和tanh函数。在神经网络层数较多的时候,最好使用ReLu函数,ReLu函数比较简单计算量少,而sigmoid和tanh函数计算量大很多。在选择激活函数的时候可以先选用ReLu函数如果效果不理想可以尝试其他激活函数。















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









