






线性回归
基本要素
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。本节使用的线性回归和平方误差刚好属于这个范畴。然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
小批量随机梯度下降(mini-batch stochastic gradient descent),
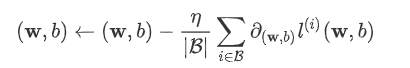
矢量计算
这里有个timer class可以mark一下。
线性回归模型从零开始的实现
读取数据集
torch.index_select()
random.shuffle()
心得
- 代码部分涉及numpy、pytorch的基础使用方法,值得一看。
- 从零开始实现的更有助于理解原理,完全弄懂从零开始实现之后对比pytorch实现代码则有助于了解学习pytorch。
Softma与分类模型
Softmax
softmax成功的将输出压缩到了0-1之间,消除了score绝对数值对结果的影响,更关注score之间的相对值对结果的影响。
交叉熵损失函数(Cross-Entropy)
交叉熵

交叉熵损失函数
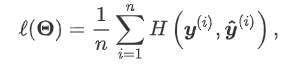
观察公式可发现交叉熵只关心对正确类别的预测概率,因为只要其值足够大,就可以确保分类结果正确。
又原式可转化为
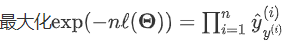
最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。
获取Fashion-MNIST训练集和读取数据
- torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
- torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
- torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
- torchvision.utils: 其他的一些有用的方法。
多层感知机
激活函数的选择
ReLu函数是一个通用的激活函数,目前在大多数情况下使用。但是,ReLU函数只能在隐藏层中使用。
用于分类器时,sigmoid函数及其组合通常效果更好。由于梯度消失问题,有时要避免使用sigmoid和tanh函数。
在神经网络层数较多的时候,最好使用ReLu函数,ReLu函数比较简单计算量少,而sigmoid和tanh函数计算量大很多。
在选择激活函数的时候可以先选用ReLu函数如果效果不理想可以尝试其他激活函数。















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









