







目录
一、简介
所谓大规模机器学习(Large Scale Machine Learning)就是指当数据量极大时的机器学习任务。当数据量非常大时,传统的优化方法如梯度下降法等会非常的耗时,对内存等计算资源要求极大,且易于过拟合。
本章将会从优化算法和一些硬件优化技巧来讨论如何处理大规模机器学习任务。
二、优化算法
2.1 诊断
正如第十章中所讨论的,并非所有机器学习任务都需要非常大的数据集进行训练,有时候适当的样本加上合理的模型即可得到较好的效果。所以在遇到大规模机器学习任务时,首要的任务就是通过绘制学习曲线来判断大量样本是否对模型优化有益。
具体内容可见机器学习诊断法。
2.2 随机梯度下降法
2.2.1 原理
简而言之,随机梯度下降法(Stochastic Gradience Descent,简称SGD)的核心思想就是每次迭代时只用一个样本来更新梯度,这样不停的遍历整个训练集,直到模型收敛为止。举例 ,其平方损失函数表示如下:
(公式 17.1)
具体步骤为:
-
对训练集进行随机化,打乱顺序。
-
对数据集不断进行遍历,每次抽取一个样本进行梯度更新。
-
直到模型收敛,或者达到一定更新次数为止。
2.2.2 优缺点
与传统的梯度下降法相比,其优点很明显,即:
-
更新速度快。
同时,其缺点也很明显:
-
准确度下降,因为单个样本的所拥有的噪声较大,所以即使目标函数为强凸函数,SGD依然很难正确收敛。
-
更容易达到局部最优。
-
不利于并行化。
2.2.3 学习率与收敛性
为了观察算法的学习情况,常用的方法就是绘制损失值和迭代次数之间的函数关系。在SGD中,会指定一个样例数n,每迭代n个样例后,求n个样例的平均损失,以此来画曲线,如图17-1所示(图片来源,吴恩达机器学习17 - 4 讲,侵删)。
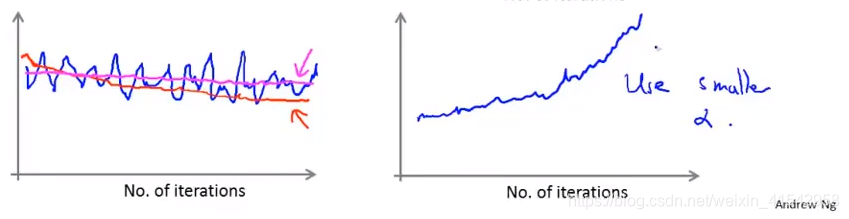
假设绘制出的曲线如左图蓝线所示,不停的发生震荡,则可能说明此时学习率过低,可以适当增大。假设学习率增大过后如红线所示呈下降趋势,则说明修改正确;反之若如紫线一般没有较明显下降的趋势,则说明可能是模型有问题,需要进一步研究。
假设绘制出的曲线如右图蓝线所示,呈现发散趋势,则说明学习率过大,需要适当降低。
同时,还能设计学习率不断变换的模型,例如令:
(公式 17.2)
即令学习率α随着迭代的不断进行而减小,同样的还要动量法等更高级的优化算法,有兴趣者可以自己查阅相关资料。
2.2.4 在线学习
在线学习(Online Learning)是指随着应用程序的运行,会有新的数据不断涌入的机器学习任务。例如在线交易和推荐系统等,随着用户不断的使用,会有新的交易记录和评分数据,系统可根据新数据进行更新。这种不断有在线数据流的问题也是大规模机器学习任务的一种。
针对在线学习的算法需要能从在线数据量中学习,而不需要讲数据存入数据库在进行离线学习的能力。
一种简单的思路即为像SGD一般,每当有新数据来临时,立马用新数据对模型进行一次更新,随后立即将用过的数据抛弃。这样做的好处在于,使得系统随用户的使用习惯的变换而不断变换自身,当用户的品味等发现改变时,系统能立马迎合这一倾向性。
2.3 小批量梯度下降法
2.3.1 原理
小批量梯度下降法(mini-batch Gradient Descent)为传统的批量梯度下降法与随机梯度下降法的折中,其核心思想为,指定一个常数b,每次选取训练集中b个样本进行数据更新,不停的遍历整个训练集,直到模型收敛为止。
其损失函数为:
(公式 17.3)
具体步骤为:
-
对训练集进行随机化,打乱顺序。
-
对数据集不断进行遍历,每次抽取b个样本进行梯度更新。
-
直到模型收敛,或者达到一定更新次数为止。
通常会令b介于2-100之间,方便向量化处理。
2.3.2 优缺点
其优点有:
-
在每一给batch上更新参数时,通过矩阵运算,并不会比单个数据慢太多。
-
与SGD相比,每次使用一个batch可以大大的减小收敛所需要的迭代次数。
-
易于并行化。
其缺点有:
- 引入了batch这一参数。
当batch_size在合理范围内增大时,能增大内存利用率;矩阵运算等并行化计算;减小迭代次数;使下降的方向更准确,减小震荡的可能。
相应的当batch_size过大时,内存的容量可能不足;迭代次数虽然减少,但是每次迭代所需要的时间愈发增加,从而使得总体时间变慢;当其达到一定程度时,下降的方式基本不发生变化。
实用的经验建议是:先用较小的batch_size,步数多但收敛快;最后几轮时使用较大的batch_size,使得精度更大。
三、多机器优化
使用多主机或多GPU优化训练的方法可简单分为数据并行以及模型的并行。
其中基于模型的并行即为一个GPU或主机复制模型中一个部分的训练,即为流水线。在神经网络中可理解为一个GPU负责整个网络中的一个层次的训练。
而基于数据的并行常见的有模型平均,同步随机梯度下降和异步随机梯度下降。
模型平均(model average)是指将数据集划分到不同的GPU上,各个GPU分布训练自己的模型,最后汇总到主核上,所有参数取各个GPU模型的平均数。由于各个GPU之间没有互相交流,各个模型随数据集的偏差可能差距较大,所以效果不是很好。
同步随机梯度下降(synchronous Stochastic Gradience Descent,简称SSGD)同样将数据集划分到不同的GPU上,只有主核上有模型。正式训练时主核将模型参数发送给各个GPU,各个CPU分别根据自己数据集计算出梯度,需要进行一次同步,然后将梯度统一发送给主核,主核用平均的梯度更新完自己的模型后,又将新的模型参数发送给各个GPU,如此往复。当模型收敛时,训练结束。
异步随机梯度下降(Asynchronous Stochastic Gradience Descent,简称ASGD)有别于SSGD的地方在于每个GPU在计算出梯度后,就立马将梯度发送给主核。主核在收到梯度时就会立刻进行参数更新,然后将训练出的参数发送给梯度来源的核。这样各个CPU只要计算出了梯度就立刻发送给主核并立即得到反馈,不需要同步。但这也使得所有CPU上的模型参数的“版本”不一致。
四、总结
本章讨论的当遇到大规模机器学习任务时,可以采取的优化方法,具体有:
- 使用随机梯度下降和小批量梯度下降等优化算法。
- 使用基于数据并行或者模型并行的多机器优化方法。

















 3757
3757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









