







数据分析之pandas_20题
系列文章
数据分析之pandas_20题_1-5
数据分析之pandas_20题_6-10
数据分析之pandas_20题_16-20
写在前面的话
这边笔记主要记录一些在数据分析过程中使用到的pandas模块的方法,希望可以帮到需要的人。
pandas 20题并不是简单的20个题目哟,是20中不同的需求。
pandas是什么?
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。常用语数据分析处理
引入库
代码如下(示例):
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
11. 统计分析之累加计算
有时候会针对数值型数据分析每条记录的累加情况
我们继续用前面的数据集
df = pd.DataFrame(index=pd.date_range('20200930',periods=11,freq='2D',closed='right'),
data=np.random.randint(10,100,(10,5)),
columns=[i for i in "ABCDE"]
)
结果

累积和
df.cumsum() # 数值型的特征累加和
结果

累积最大值
df.cummax() # 累加最大值
结果
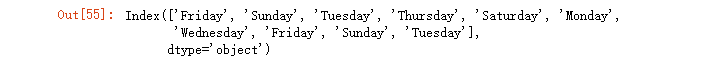
12. 统计分析波动情况
有时候需要分析本期数据与上期数据的变化情况,可以用于分析某个特征周期内的波动情况
df.diff()
结果

13.添加新的记录
我们的数据往往是随着时间不断增加的,当需要在源数据集中增加新的数据集时,就需要用到添加操作
# 造数
data = dict(zip(df.columns.to_list(),np.random.randint(10,100,5)))
# data结果
{
'A': 41, 'B': 32, 'C': 50, 'D': 41, 'E': 55}
append 方法添加
# 以字典格式添加,默认会将字典转换成新的DataFrame,但是新的DataFrame的索引并不是时间序列 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









