







b树和b+树的区别
基本知识
2-3树

2-3-4树

B树存储引擎
(小知识点)
Innodb使用的是B+树,他存在有一个主键索引和辅助索引两种索引,主键索引是在生成主键时就有的索引,他的叶子节点中存放的就是数据行,所以又称之为聚集索引。
而另一类索引,辅助索引,就是我们人为新建的索引,他的叶子节点中存放的是主键,当我们通过辅助索引查找到主键之后,再通过查找的主键去查找主键索引,
(数据结构)
相比哈希存储引擎,B树存储引擎不仅支持随机读取,还支持范围扫描。关系数据库中通过索引访问数据,在Mysql InnoDB中,有一个称为聚集索引的特殊索引,行的数据存于其中,组织成B+树(B树的一种)数据结构。

如图所示,MySQL InnoDB按照页面(Page)来组织数据,每个页面对应B+树的一个节点。其中,叶子节点保存每行的完整数据,非叶子节点保存索引信息。数据在每个节点中有序存储,数据库查询时需要从根节点开始二分查找直到叶子节点,每次读取一个节点,如果对应的页面不在内存中,需要从磁盘中读取并缓存起来。B+树的根节点是常驻内存的,因此,B+树一次检索最多需要h-1次磁盘IO,复杂度为O(h)=O(logdN)(N为元素个数,d为每个节点的出度,h为B+树高度)。修改操作首先需要记录提交日志,接着修改内存中的B+树。如果内存中的被修改过的页面超过一定的比率,后台线程会将这些页面刷到磁盘中持久化。
B-树

简介
B树也是一种用于查找的平衡树,但是它不是二叉树。
B树的定义:B树(B-tree)是一种树状数据结构,能够用来存储排序后的数据。这种数据结构能够让查找数据、循序存取、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树,可以拥有多于2个子节点。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。这种数据结构常被应用在数据库和文件系统的实作上。
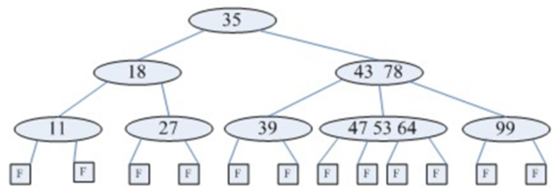
1 一颗m阶树中每个节点至多有m棵子树(即至多含有m-1个关键字);
2 若根节点不是叶子节点,则至少有2棵子树;
3 除根节点之外的所有非终端节点至少有[ m/2 ] ( 向上取整 )棵子树,即([ m/2 ]-1个关键字)
4 每个节点中的信息结构为(A0,K1,A1,K2......Kn,An),其中n表示关键字个数,Ki为关键字,Ai为指针;且Ai-1所指子树中所有结点的关键字均小于Ki,An所指子树中所有结点的关键字均大于Kn;
5 所有的叶子节点都出现在同一层次上,且不带任何信息,也是为了保持算法的一致性。
查找


 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











