









 文章提出了一种新的自动程序修复方法,名为AlphaRepair,它利用预训练的CodeBERT模型,通过完形填空式的修复策略,无需微调或重新训练,提高了修复效率。AlphaRepair在Defects4J基准上表现优越,特别是在与现有最先进的APR技术对比中,显示出更高的修复成功率。
文章提出了一种新的自动程序修复方法,名为AlphaRepair,它利用预训练的CodeBERT模型,通过完形填空式的修复策略,无需微调或重新训练,提高了修复效率。AlphaRepair在Defects4J基准上表现优越,特别是在与现有最先进的APR技术对比中,显示出更高的修复成功率。
Less Training, More Repairing Please: Revisiting Automated Program Repair via Zero-shot Learning
摘要概述
基于模板的技术需要预定义模板来执行修复功能,该方式的有效性有限;基于学习的APR通常是在神经机器翻译的基础上,将错误/修复代码视为源/目标语言的翻译问题进行修复,但是该方式严重依赖大量高质量的错误/修复数据集,同样也有自身的局限性。该文重新审视了基于学习的APR技术,直接利用了大型预训练代码模型对错误代码进行完形填空模式的修复,且该方式不需要进行任何的微调或者重新训练。我们利用最近的CodeBERT模型实现了 AlphaRepair 工具来验证我们的方式,并且在广泛使用的 Defects4J 基准上评估了 AlphaRepair ,结果表明,该方式的修复效率大大优于目前最先进的 APR 技术。
方法概述
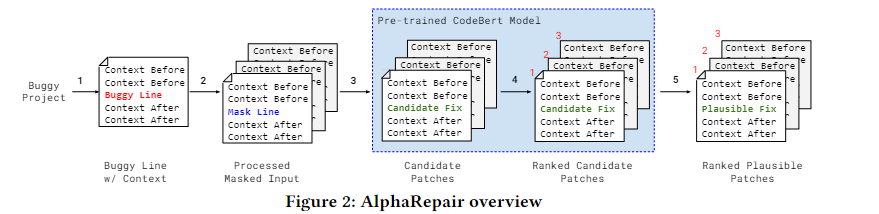
1. 接受一个bug项目,根据故障定位信息,将bug行和周围的上下文分开,其中,上下文编码为令牌表示,错误行编码为CodeBERT的自然语言输入中的注释
2. 使用模板将bug行转换为多种形式的掩码行(整行替换/前半部分替换/后半部分替换),每个掩码行都和周围的上下文信息一起标记为CodeBERT的输入
3. 迭代查询CodeBERT使将掩码行生成候选补丁,其中每个候选补丁都是将掩码行换为代码行而转变来的
4. 再次通过使用CodeBERT生成的令牌的联合概率来计算生成的补丁的分数来提供补丁排行
5. 编译每个候选补丁并根据测试套件验证它,最后为开发人员输出一个可能的补丁列表来供检查
详细步骤
1. 输入处理
标记器:Byte-level BPE(已证明可以缓解词汇外问题)
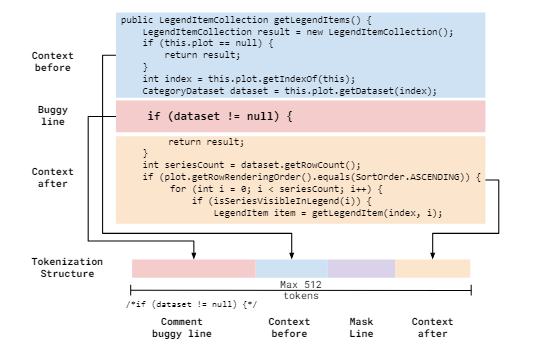
标记化结构(CodeBERT输入的标记列表):标记前后的上下文,并将掩码行夹在它们之间。利用CodeBERT的双峰特性(即可以同时采用编程语言和自然语言),将原始错误行勇注释字符/*comment*/包围起来,作为注释。如下图所示,注释错误行、前上下文、掩码行、后上下文一起标记为CodeBERT的输入。且为了最大化上下文,逐步上下文的大小,直到达到最大的CodeBERT输入令牌大小512
2. 掩码生成
掩码行:带有一个或多个<mask>标志的代码行。
在该步骤中,作者定义了三种掩码掩码策略,如下图所示,分别为,Complete mask(全部掩码)、Partial mask(部分掩码)、Temlpate mask(模板掩码)

Complete mask(全部掩码):该策略两种方式:1. line replace:将整个bug行用掩码行替换;2. line after:在掩码行前后都增加一行掩码行,表示对bug行前后行的修复
Partial mask(部分掩码):生成掩码行的另一种策略是重用错误行中的部分代码。首先将错误行分离为其单独的令牌,然后保留最后一个/第一个令牌,并用掩码令牌替换之前/之后的所有其他令牌。然后,我们重复这个过程,但从原始错误行中附加更多令牌,以生成部分掩码行的所有可能版本。如图所示before中,先保留长度为L的错误行中的第一个token,其余的mask,作为一个掩码行,再保留第一和第二和token,其余的mask,作为第二个掩码行,直到保留到第L-1个token,共生成L-1个掩码行
Temlpate mask(模板掩码):为条件语句和方法调用制定的几种策略。
为方法调用制定的几种模板——1、method replace:旨在针对有缺陷的方法调用。该模板将方法调用名称替换为掩码标记;2、parameter repalce:还使用几个基于参数的变化:用掩码标记替换整个输入的参数;3、single replace:用掩码标记替换一个参数;add parameter:添加附加参数(s)(可以添加多个参数,因为我们改变了掩码标记的数量,因此 CodeBERT 可以添加多个参数);
为条件语句制定的几种模板——1、expression replace:通过用掩码标记附加语句来生成替换整个布尔表达式(即将条件语句中的判断语句全部mask);2、more || /&& cond:添加额外的and/or 表达式的掩码行(在判断语句后通过各种 || 或者 && 连接符来再添加几个mask);3、replace operator:识别常见的运算符(<, >, >=, ==, &&, 、|| 等),并将它们直接替换为掩码标记。
掩码生成的整体基本策略设置:对于每个生成的掩码行,我们将生成的令牌数从1增加到该行中的令牌总数(𝐿 + 10) 其中𝐿 是原始错误行中的令牌数。例如,如果我们在L为12的错误行上使用“partial after”策略,我们保留前5个原始令牌,我们将掩码令牌的数量从1逐步增加到17。这个过程是针对我们应用的每个掩码策略完成的(替换运算符策略除外,在替换运算符策略中,我们只使用单个掩码令牌替换公共运算符)。我们对每个掩码行应用输入处理步骤,以获得CodeBERT的已处理输入列表。
3. 补丁生成
该步骤使用的数据和训练所使用过的数据不同的是,训练时生成的mask是随机的,而该步骤使用的mask标志是连续的。在该步骤中,主要是通过用先前生成的标志来替换mask标志从而迭代输出token。大致过程如下图示例所示:

在该示例中,首先初始化掩码行:" if (endIndex < 0 || <mask><mask><mask>) { ",并且使用CodeBERT来确定第一掩码令牌的前N个最可能的替换令牌。N 是波束宽度,是我们方法的可调参数。在此示例中,N 是 3 个含义,我们取前 3 个最可能的标记及其条件概率,前三个生成的令牌为 startIndex、endIndex、emptyRange,然后在此基础上,再预测接下来的mask,生成9个预测行,并且取前三个最高的联合条件概率的预测行 startIndex <、startIndex ==、endIndex >=。
联合条件概率值称为 temp joint score,该联合分数的公式为:
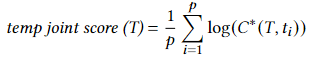
其中,p 为到目前预测的mask数量,𝐶∗(𝑇,𝑡)是CodeBERT生成mask预测的概率。(当所有mask都被预测后,临时联合分数并不代表生成的令牌的实际概率,即临时联合得分取决于其值尚未确定的掩码令牌,条件概率不考虑这些掩码令牌的未来具体值)
4. 补丁重排行
关键思想:在完全生成补丁后,为每个补丁提供准确的分数(即可能性,以便进行更有效的补丁排名)
从包含所有生成令牌的完整补丁开始。然后,我们只屏蔽其中一个令牌,并查询CodeBERT以获得该令牌的条件概率。我们对所有其他先前的掩码令牌位置应用相同的过程,并计算作为单个令牌概率的平均值的联合得分。其中,联合概率的计算公式为:
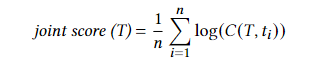
n为当前补丁的全部令数目,C(T, ti)为仅mask当前这个token后,得到这个token为预测值的概率。将其最后除以n是因为掩码行具有不同数量的掩码令牌,我们需要考虑令牌长度的差异。
通过该步骤,我们可以获得更加准确的补丁排序,当只能验证生成的补丁的子集时,该排序允许进行优先级排序
5. 补丁验证
对于我们生成的每个候选补丁,我们将相应的更改应用到bug文件。我们编译每个补丁并过滤掉任何编译失败的补丁。然后,我们针对每个编译的补丁运行测试套件,以找到通过所有测试的可信补丁。
实验设计
围绕了以下三个问题进行了实验设计:
1、 AlphaRepair 与最先进的 APR 工具相比如何?
2、 不同的配置如何影响 AlphaRepair 的性能?
3、 AlphaRepair对于其他项目和多种编程语言的通用性是什么?
通过将该工具与最先进的APR工具进行比较,证明了该工具的有效性(默认使用完美的故障定位),评估了AlphaRepair对 Defects4J 2.0 和 QuixBugs 中其他项目的可推广性。此外,我们还通过测试 Python 版本的 QuixBugs 来评估 AlphaRepair 的多语言修复能力
实验环境:
AlphaRepair在Python中是实现,CodeBERT模型在Pytorch中实现
参数设置:
1. 重用了预训练的CodeBERT模型的模型参数
2. 对于完美的故障定位补丁生成,使用N为 25 的波束宽度,最多生成5000个补丁;对于不完美的故障定位补丁生成,使用N为 5 的波束宽度,考虑前40个最可能的补丁行。
3. 使用 Ochiai 故障定位
4. 补丁验证:UniAPR工具
评估的数据集
1. Defects4J数据集。使用Defects4J 1.2 版本 (在6个不同的Java项目中包含391个错误(除去4个已折旧的错误后)) 回答解决研究问题1和2;使用Defects4J 2.0 版本 (在Defects4J1.2的基础上增加了438个bug,在该实验中只评估Defects4J 2.0中新错误中存在的82个单行错误) 解决研究问题3。
2. QuixBugs数据集:该数据集包含相同的bug程序的Python版本和Java版本。在Python和Java版本上对AlphaRepair进行了评估,以展示我们工具的多语言能力
进行比较的APR技术
将该工具与包含基于学习的和传统的APR工具进行了比较(总计 18 种),其中
● 基于学习的APR技术(6 种):Recoder(Java)[80]、DeepDebug(Python)[19]、CURE(Java)[32]、CoCoNuT(Java和Python)[51]、DLFix(Java)[42]和SequenceR(Java)[14]
● 传统的APR技术(12 种):TBar[44]、PraPR[25]、AVTAR[45]、SimFix[31]、FixMiner[35]、CapGen[74]、JAID[12]、SketchFix[29]、NOPOL[17]、jGenProg[52]、jMutRail[53]和jKali[53]
度量标准
使用了两个似是而非的补丁的标准指标,这些指标只是传递项目的整个测试套件,以及语法或语义上与开发人员补丁等效的正确补丁。遵循 APR 的常见做法,正确的补丁是通过手动检查每个合理的语义等价性补丁来确定的。
实验结果分析
1. 与最先进工具的比较
完美错误定位的前提下各工具的性能,如下表所示:
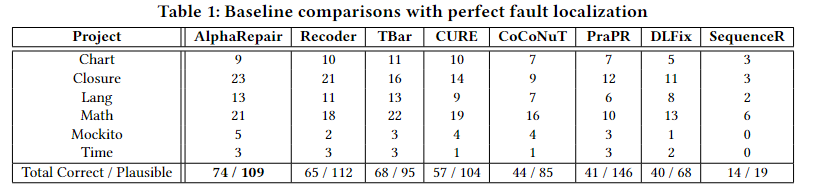
AlphaRepair 可以成功地为 74 个错误生成正确的修复,这些错误优于所有先前的基线,包括传统和基于学习的 APR 技术
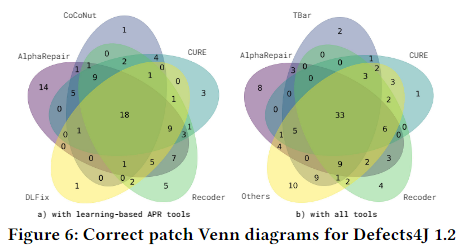
下图展示了AlphaRepair 的有效性,评估了只有该工具可以修复的唯一错误的数量,图6a 显示了与其他基于学习的工具的独特修复比较,观察到 AlphaRepair 能够修复最多数量的唯一错误,为14个;图6b显示了该工具与其他所有工具的独特修复比较,观察到 AlphaRepair 能够修复 8 个唯一错误的数量最多。这也表明 AlphaRepair 可以与其他技术一起使用,以进一步增加可以生成的正确补丁的数量。
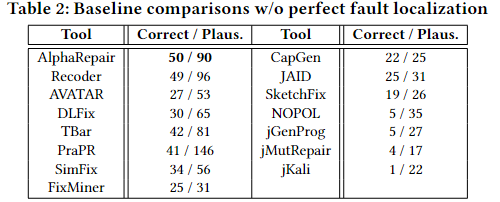
不完美错误定位的前提下各工具的性能,如下表所示:
AlphaRepair 能够产生 50 个正确的补丁,这优于以前的最先进工具。此外,AlphaRepair 能够正确修复任何其他技术无法修复 7 个唯一错误(所有研究技术中最高的错误)。
2. 消融研究
该研究的目的就是为了研究在 AlphaRepair 设计中添加不同组件的贡献,如下表所示:
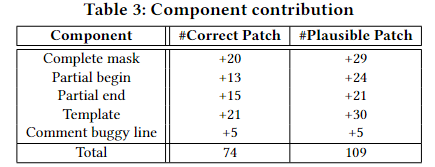
其中每行代表一个组件的结果,以及可以生成正确/似是而非的补丁数量。
该实验从最基本的策略开始并迭代地添加更加复杂的掩码策略:首先,只使用完整的掩码,其中整个错误行被替换为所有掩码标记。该情况给 CodeBERT 提供了生成各种编辑的整个自由度,然后这通常是不可取的,因为搜索空间随着掩码标记的数量呈指数增长,这很难获得正确的修复;随着开始使用更多掩码生成策略,我们获得的正确补丁数量增加,性能提升最高的是使用模板掩码行,提升了21个额外的新修复,因为模板掩码行允许CodeBERT仅填充少量限制搜索空间的掩码标记,并允许AlphaRepair 快速找到正确的补丁
另外在补丁生成后,AlphaRepair 重新查询了CodeBERT再次生成每个补丁更准确的排名,如下表所示,比较了有和没有重新排序的正确补丁的顺序:
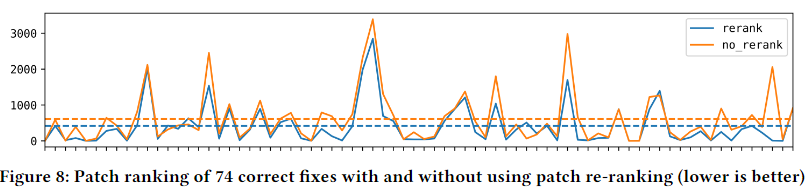
观察到,在不使用重新排序策略的情况下,平均而言,正确的补丁排名第 612。使用重新排序时,平均排名正确的补丁排名第 418(减少了 31.7%)。此外,与之前相比,74 个正确补丁中的 61 个在重新排序后排名更高
3. 通用性研究
Defects4J 2.0.为了证明附加项目和错误的普遍性,并确认 AlphaRepair 并非简单地过度拟合Defects4J 1.2 中的错误,我们在 82 个单行Defect4J 2.0 数据集上评估 AlphaRepair。下表显示了与Defects4J 2.0的其他基线相比的结果:
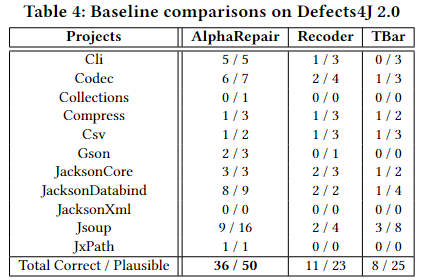
观察到AlphaRepair能够获得最多的36个正确补丁(比顶部基线多3.3倍)。虽然TBar等基于模板的工具能够为Defects4J 1.2生成大量正确的补丁,但它可以为Defects4J 2.0生成的正确补丁数量有限。基于学习的工具(如Recoder)也会因转移到更难的评估数据集而受到影响,因为编辑是从Defects4J 2.0中可能不存在的训练数据集学习的。相比之下,AlphaRepair没有对特定的bug数据集进行任何微调,这使得它不太容易受到传统基于模板或基于学习的工具的通用性问题的困扰。
QuixBugs.通过对该数据集进行评估来展示AlphaRepair 的多语言修复能力,该数据集包含Java和Python版本的bug程序。下表显示了最先进的Java和Python APR工具的结果

观察到AlphaRepair能够在Java和Python中获得最高数量的正确补丁(28和27)。我们还观察到,AlphaRepair是基线中唯一可以直接用于多语言修复的工具(CoCoNuT训练了两个单独的模型)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











