







 CoCoNuT是一种新的程序修复技术,结合集成学习和上下文感知的神经机器翻译模型。它解决了传统修复技术依赖硬编码规则的问题,能适应多种编程语言。通过引入新的上下文感知NMT架构,CoCoNuT分别处理错误代码和上下文,使用CNN提取分层特征,并通过集成学习结合不同模型来修复更多错误。在评估中,CoCoNuT成功修复了多种编程语言的多个错误,其中包括其他技术未能修复的错误。
CoCoNuT是一种新的程序修复技术,结合集成学习和上下文感知的神经机器翻译模型。它解决了传统修复技术依赖硬编码规则的问题,能适应多种编程语言。通过引入新的上下文感知NMT架构,CoCoNuT分别处理错误代码和上下文,使用CNN提取分层特征,并通过集成学习结合不同模型来修复更多错误。在评估中,CoCoNuT成功修复了多种编程语言的多个错误,其中包括其他技术未能修复的错误。
CoCoNuT:使用集成方法结合上下文感知神经翻译模型进行程序修复
论文思维导图

1. 摘要
自动生成和验证 (G&V) 程序修复技术 (APR) 通常依赖于硬编码规则,因此只能修复遵循特定修复模式的错误。这些规则需要大量的手动工作才能发现,并且很难使这些规则适应不同的编程语言。
为了应对这些挑战,我们提出了一种新的 G&V 技术——CoCoNuT,它使用集成学习结合卷积神经网络 (CNN) 和新的上下文感知神经机器翻译 (NMT) 架构来自动修复多种编程语言中的错误。为了更好地表示错误的上下文,我们引入了一种新的上下文感知 NMT 架构,它分别表示有错误的源代码及其周围的上下文。 CoCoNuT 使用 CNN 而不是递归神经网络 (RNN),因为可以堆叠 CNN 层以提取分层特征并在不同的粒度级别(例如,语句和函数)更好地模型源代码。此外,CoCoNuT 利用超参数调整的随机性来构建修复不同错误的多个模型,并使用集成学习将这些模型组合起来以修复更多错误。
我们对四种编程语言(Java、C、Python 和 JavaScript)的六种流行基准测试的评估表明,CoCoNuT 正确修复了(即,第一个生成的补丁在语义上等同于开发人员的补丁)509 个错误,其中 309 个错误由我们比较的 27 种技术都没有。
2. 介绍
一般生成和验证的大致流程:首先,候选补丁是使用一组转换或突变生成的(例如,删除一行或添加子句)。其次,通过编译和运行给定的测试套件对这些候选对象进行排序和验证。G&V工具返回编译并通过显示故障的测试用例的最高级的修复
现有修复技术的两大缺陷:1、正确补丁的数量很少 2、针对编程语言的类型需要特别定制而无法同时适应多种编程语言的修复
在本文中使用的基于 NMT 的程序修复技术的两大优势:1、NMT可以捕获我们手工难以捕获的复杂关系(输入和输出之间的复杂关系以及正确代码和错误代码之间的复杂关系) 2、NMT虽然需要使用依赖于编程语言并需要领域知识的硬编码修复模式,但是对于不同的编程语言,它可以自动重新学习,而不需要人为干预
目前 NMT所面临的挑战以及我们的解决方案:
- 挑战1:上下文的表示——如何修复一个错误语句依赖与它的上下文关系,而如何在NMT修复模型中有效表示上下文关系是很重要的。为此我们提出的一个解决方法:上下文感知的NMT架构模型——该模型使用的是两个不同的编码器,一个处理错误代码行,一个处理上下文代码,这样的好处有三:1、错误线路的编码器需要处理的输入序列很短,这可以使得NMT更好抽离出错误代码序列之间的复杂关系,也不会受到上下文序列的噪声干扰 2、上下文线路的编码器也可以专心处理上下文关系而不会受到错误代码行的噪声干扰 3、两条线路相互独立,可以拥有不同的复杂度(如错误处理线路需要更深的网络来捕获更复杂关系而上下文处理线路需要更长的卷积层来捕获长距离的代码关系),这大大增加了NMT模型的执行效率
- 挑战2:捕获错误修复的多样性——之前的NMT的单层结构使得该模型只使用一个最佳的超参数无法更好地捕获修复其他类型的错误。我们提出的解决方法:集成学习——组合不同复杂程度的模型,这些模型捕获错误代码和干净代码之间的不同关系。这使我们的技术能够学习不同的修复策略来修复不同类型的错误
我们所提出的方法 CoCoNuT 的概述:由全卷积(FConv)模型和新的上下文感知的不同复杂度的NMT模型组成。每个上下文感知模型使用两个独立的编码器(一个用于错误行,一个用于上下文)捕获关于修复操作及其上下文的不同信息。将这些模型结合起来,可以让CoCoNuT学习不同的修复策略,这些策略用于修复不同类型的bug,同时克服现有NMT方法的局限性
我们的贡献:
- 一种新的上下文感知 NMT 架构,分别表示上下文和错误输入。该架构独立于我们的全自动工具,可用于解决需要长期上下文的其他领域的一般问题(例如,语法错误纠正)
- CNN(即 FConv [20] 架构)在 APR 中的第一个应用。我们表明,在相同数据集上训练时,FConv 架构优于 LSTM 和 Transformer 架构。
- 一种结合上下文感知和 FConv NMT 模型的集成方法,以更好地捕捉错误修复的多样性。
- CoCoNuT 是第一个可以轻松移植到不同编程语言的 APR 技术。由于使用了 NMT 和新的标记化,我们几乎不需要手动操作,就可以将 CoCoNuT 应用于四种编程语言(Java、C、Python 和 JavaScript)
- 在四种编程语言的六个基准上对 CoCoNuT 进行全面评估。CoCoNuT 修复了 509 个错误,其中 309 个错误尚未被现有的 APR 工具修复
- 使用注意力图来解释为什么某些修复是由 CoCoNuT 生成或不生成的
3、方法
该技术包含三个阶段:训练、推断、验证,如下图所示:
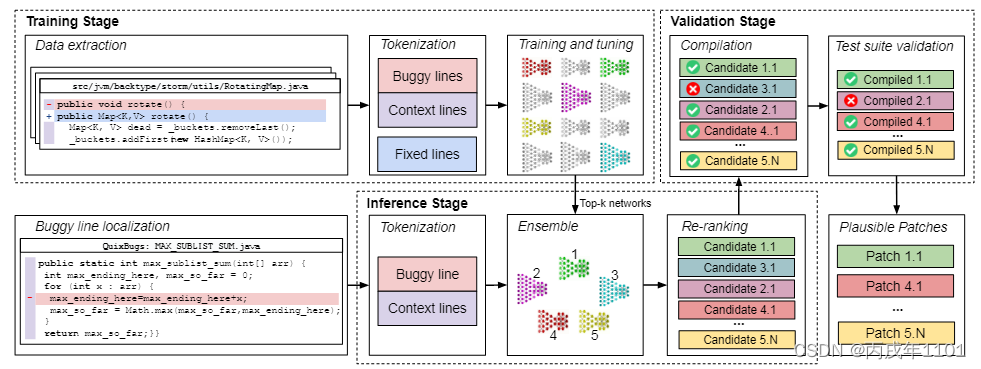
- 训练阶段:1、从开源项目中抽取相关代码数据:错误、上下文、修复行;2、处理这些代码行以获取token序列并送入NMT网络中,使用不同的超参数集调整网络;3、训练前k个模型直到收敛前以获得前k个模型的集合,每个模型有不同的超参数且可以修复不同的错误
- 推断阶段:输入错误行以及上下文信息,然后序列化输入并将其送入前k个最佳模型中,每个模型输出一个补丁列表,并且通过编译这些补丁项目来对补丁进行排序和验证
- 验证阶段:在可编译修复上运行测试套件以过滤不正确的补丁。最终输出是通过验证阶段的候选补丁列表。
3.1 其他挑战
在这个三个阶段的过程中,我们还将面临其他挑战:
-
挑战3:神经网络层的选择——自然语言文本通常是从左到右顺序读取的,但是代码不一定是顺序读取的,例如在含有条件语句的代码中,可能会跳过条件块执行,所以传统的循环神经网络使用LSTM层来进行代码修复可能不会有很好的效果。我们的解决方法——使用卷积层的新上下文感知 NMT 架构:堆叠不同大小内核的卷积层来实现不同层次的粒度关系,较大内核的卷积层模拟长期关系(如函数之间的关系),较小内核的卷积层模拟短期关系(如语句之间的关系),且为了进一步跟踪输入和上下文编码器中的长期依赖性,我们使用了多步注意机制。
-
挑战4:大词汇量——程序代码比自然语言所存在的词汇量大得多,而且经常会有不常见的标记,如一些工作者自定义的函数和变量等。我们的解决方法:使用新的标记化方法——减少了词汇量且在测试集中使不常用的词汇量始终低于2%
3.2 数据提取
通过在开源项目上手工输入关键字来过滤无关信息,获得需要的代码信息,使得所得的训练样本保持一个合理的噪声,其中使用了错误行所在的函数来表示上下文信息
3.3 输入表示和标记化
使用类似于词级标记化(即空格分隔)的标记化方法:将运算符和变量分开,且考虑到词汇量大且很多词汇采用下划线或者驼峰式表示法,故引入新的标记()来标记驼峰式拆分发生的位置;最后抽象字符串和数字文字,但是训练中常见的数字除外(0和1)
3.4 上下文感知的NMT体系结构
该步骤的架构主要存在两个创新:1、两个独立编码器的使用;2、RNN中使用卷积层而不是LSTM层
训练模式下的训练效果:通过训练来生成带有上下文的错误线路到修复线路的转换的最佳表示,这是通过不断地调整输入实例转为修复行的参数权重来完成的,多次的传递训练可以获得最佳的权重集
训练模式下的训练效果:通过训练来生成带有上下文的错误线路到修复线路的转换的最佳表示,这是通过不断地调整输入实例转为修复行的参数权重来完成的,多次的传递训练可以获得最佳的权重集
编码器和解码器:编码器的目的是提供输入序列的固定长度向量化表示,而解码器则将这种表示转换为目标序列(即补丁行)。两个模块的结构相似,由三个主要块组成:嵌入层、几个卷积层和门控线性单元(GLU)层。
- 嵌入层:将输入和目标标记表示为向量,出现在相似上下文中的标记具有相似的向量表示
- 几个卷积层:卷积核大小表示考虑到的周围标记的数量,堆叠具有不同内核大小的卷积层为网络提供了不同抽象级别;编码器使用的卷积层的输入是输入序列中前一个和下一个标记的信息;而解码器使用的是期限前生成的标记的信息(图中可以看出编码器和解码器输在卷积层中的输入形状的不同)
- GLU层:决定网络应该保留哪些信息
- 多步注意机制:使用注意力机制连接编码器的和解码器中每个卷积层的输出,当使用多个卷积层时会产生多个注意力图,注意力图表示的是输入标记对特定输出的影响,可以帮助解释生成特定输出的原因
- 令牌生成:结合了注意力层、合并器和解码器的输出
- 束搜索:使用一种称为波束搜索的通用搜索策略来生成和排列大量候选补丁,每次迭代该算法先检查最有可能的标记,然后根据下一个预测步骤的总似然得分对它们进行排名,最后搜索算法输出最有可能的序列,这些序列是根据每个序列的可能性进行排名的
3.5 集成学习
它结合了有或者没有上下文的模型,以及具有不用超参数的模型,其中超参数是使用随机搜索来选择随机的参数集来训练模型,但是这种随机搜索是根据我们的硬件条件在一个范围内来选择的,且只调整一个时期的超参数,我们根据每个模型在单独的验证集上的性能保留最佳的模型
3.6 补丁验证
首先从模型生成的标记列表中生成一个完整的补丁,对于抽象的标记,我们从发生错误的原始文件中提取表示代码,生成修复后就将其插入错误位置并进入验证步骤;验证步骤就是要过滤未编译或未通过触发测试用例的补丁
3.7 推广到其他语言
该步骤所需的主要是获取新的输入数据,我们可以从其他语言的开源项目中获得,然后重新训练前K个模型而实现



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











