







SQVDT:一种用于源代码安全评估的可扩展定量漏洞检测技术
0.论文思维导图

1.相关知识
1.1 MapReduce
MapReduce是一个分布式运算程序的编程框架,是用户开发基于Hadoop的数据分析应用的核心框架。它是一个范例,可以在Hadoop集群中的数百台服务器上实现巨大的可扩展性。作为一个处理组件,它是Hadoop的核心,它可以将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。术语MapReduce指的是Hadoop执行的两个不同的任务。
第一个任务是Map:它获取数据并将其转换成另一种形式的数据,其中每个元素都分解成一些值对
第二个任务是Reduce:将map的输出作为输入,并将这些值对组合成一些更小的元组集
详细可参考文章:MapReduce入门(一)—— MapReduce概述 + WordCount案例实操
在本文的实验中,将此框架设置为单节点Hadoop安装和多节点Hadoop安装。在每台机器上做了一些Hadoop、HBase、Zookeeper、HDFS NameNode、DataNode等等的配置,包括设置Java路径、Zookeeper路径、Hadoop路径、HBase路径、IP地址等等。在检测过程中,线程控制主节点模块,主节点模块调用控制层的函数完成检测过程。此外,由于检测任务对应于一个线程,因此可以随时进行任务监控。
1.2 代码克隆
代码克隆是指从其他系统复制的代码片段。有四种不同类型的代码克隆,分别是:
- 类型1——精确克隆:相同的代码片段,但是可能在空白、布局和注释方面有一些变化
- 类型2——重命名克隆:在标识符、文字、类型、空白、布局和注释方面有一些变化的语法上等价的片段
- 类型3——重构克隆:语法上类似的代码,带有插入、删除或更新的语句
- 类型4——语义克隆:语义等价,但语法不同的代码
1.3 补丁文件
补丁文件可以理解为新旧文件的差异文件,它是源代码形式的一系列指令,描述如何在应用程序中更改一个文件或者一组文件,如下图补丁文件CVE-2018-1000019所示,该补丁文件是为了修复Linux内核版本3.18中的崩溃和内存损坏问题
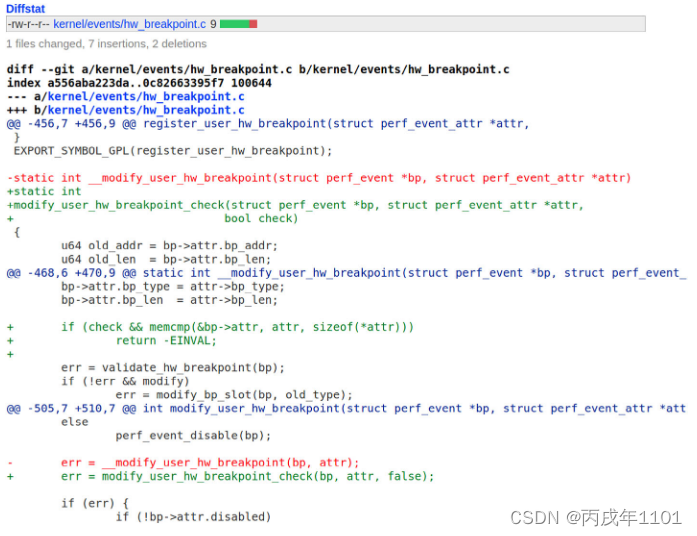
在一个补丁文件中,有如下符号需要我们了解:
- “+”:表示代码添加
- “-”:表示代码删除
- “@@”:表示要进行更改的起始行和结束行,上图的补丁文件在三个不同位置进行了更改
- “- - -a”:表示旧文件(应用补丁之前)的地址
- “+++b”:表示新文件(应用补丁之后)的地址
2.论文详解
2.1 摘要
漏洞检测和利用正成为安全的一个非常重要的部分,特别是在恶意软件代码交付、入侵系统、创建补丁、改进源代码或更新软件方面。应用程序中的漏洞,包括浏览器、媒体播放器、在线服务、文档阅读器等等。经常被利用并造成严重的损害。在这篇文章中,我们提出了一种漏洞检测技术来检测软件中的漏洞,以及源代码级别的共享库。我们通过跟踪和定位来自不同web源的补丁文件,根据它们的CVE号爬取易受攻击的源代码,并建立了2931个易受攻击文件的指纹索引。然后我们开发了一种基于代码克隆检测技术的漏洞检测方法,检测了数千个GitHub开源项目中的数百个漏洞,这些漏洞是以前没有注意到的。我们在最近推出的一些非常著名的软件中检测到漏洞,包括最新的Linux版本,HTC-kernel,FindX-8.1-kernel,以及7-TB的C/C++源代码代码(152,823个开源项目)。在本研究中,我们讨论了通过我们的方法检测到的一些非常高严重性级别(CVSS)的漏洞。此外,我们对这些漏洞进行了实证评估和验证,包括项目内克隆漏洞、复制内核克隆漏洞和库使用克隆漏洞。我们的技术非常快速、高效、可靠、实用、可扩展,并且可以在工业水平上实施。与最先进工具的比较表明了我们方法的有效性
2.2 贡献
• 通过跟踪补丁文件提取和构建漏洞源代码基准。
• 开发了一种基于代码克隆检测技术的漏洞检测方法。
• 检测一些非常著名的操作系统的漏洞。
• 对这些检测到的漏洞进行经验评估和验证研究。
• 基于补丁的静态分析对这些漏洞的影响。
在7-TB的源代码中显示许多检测到的漏洞的结果(152,823个项目)
2.3 实现步骤
SQVDT 背后的核心思想是检测任何软件中易受攻击的源代码,以测试安全性。目标是通过使用代码克隆检测技术来检测目标系统中的易受攻击的源代码,其中已经有了易受攻击的源代码数据集的指纹签名集。所开发的漏洞检测方法工作在文件级粒度,其中主要是检测相似的源代码文件。主要架构下图所示,在图的左侧,为获取易受攻击的代码数据集,并从中提取不同的特征来构建其指纹,在图的右侧,为获取一个主题系统(测试项目),通过对其应用不同的过滤器来检测和定位易受攻击的源代码。
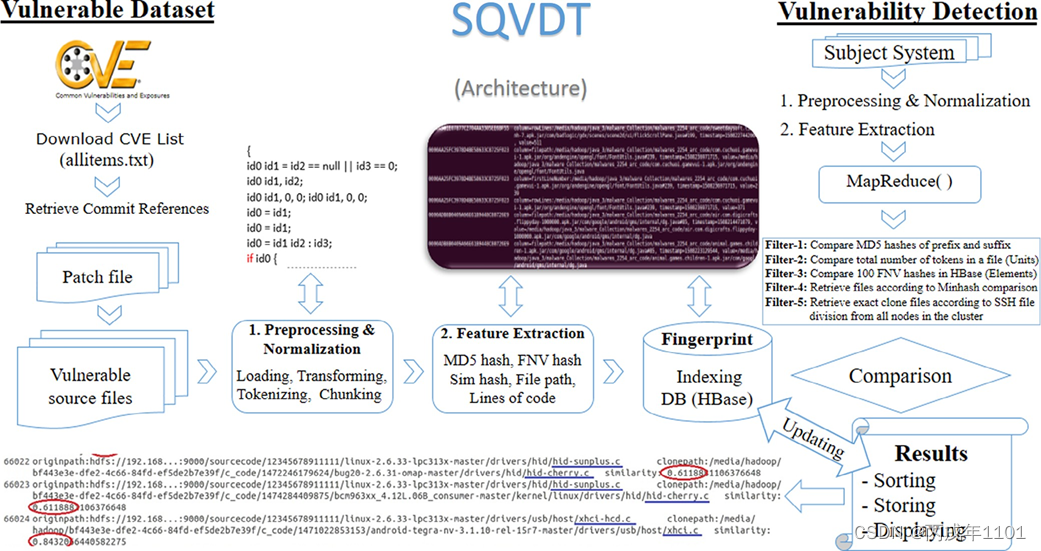
2.3.0 易受攻击代码提取
本文利用了CVE平台来搜集易受攻击的代码和一些补丁文件,在CVE平台中,它有一个CVE列表,包括描述、公共参考和标识号,由于CVE站点显示了不同的公共引用,我们可以从那里探索或下载针对每个CVE的提交代码。
首先编写一个网络爬虫来从不同的网络资源下载易受攻击的文件,但是CVE网站上的参考链接是为了方便用户,帮助区分漏洞的,其中一些参考链接并不能查看补丁文件,或下载易受攻击的文件,所以我们需要对一些参考站点进行过滤,只爬取那些提供补丁文件的参考链接站点,如:Kernel.org git repositories、GitHub repository、Bugzilla、Openssl等
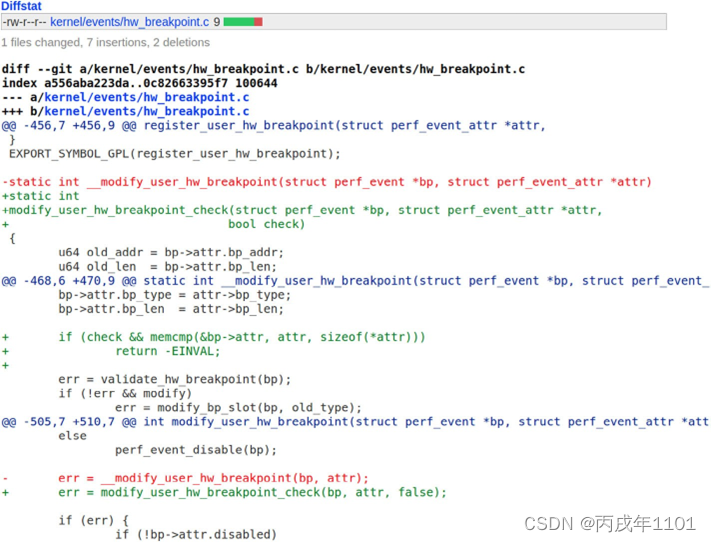
如下图CVE-2018-1000199漏洞的补丁文件,它可以在 kernel.org 上查看并且下载,且可以通过补丁文件中的--- a kernel/events/hw_breakpoint.c来查看并下载补丁前的源文件代码
2.3.1 源代码预处理(阶段1)
该阶段为第一阶段,主要是通过跟踪其原始源代码文件(在应用补丁前)从补丁文件中提取易受攻击的代码(在本文中默认补丁文件中需要删除的代码为易受攻击的代码),然后在删除一些不需要的代码,即一些注释、空格等;最后源代码转换成特定单元(令牌),大致流程如下图所示:

首先该图上侧显示了源代码路径(即 --- a ······)以及易受攻击文件中显示所做的更改(即 @@ -28,22 ········)
下侧的最左边显示了补丁文件的代码,中间显示了易受攻击的代码片段(即将补丁文件中需要删除的代码行进行提取的操作),最右侧显示预处理的代码
预处理的过程如下:
1、使用词法分析器技术进行标记化,为每个标记分配特定的 id,即忽略空格和注释等,只关注变量和函数名以及操作符,然后使用 id + 他们在该行代码中出现的次数作为标识符(如 wo为第一段代码的第一个变量,则标记为id0,忽略int标识,rubf为第一段代码第二个变量,则标记为id1,····依次类推)
2、将所有字符串替换为NULL,并且整数值乘以0,浮点数乘以0,布尔值为真等等,如图中代码memset(sndbuf,0,7)先变为id0 id1 0 7,再转换为id0 id1 0 0,即将整数值7乘以 0,
整个预处理阶段目的是为了清理源代码,为检测过程做准备,这样预处理的方式,使得变量名以及一些函数名得到了统一,更容易区分该代码是否来自于同一源代码文件(如有些恶意软件开发人员通过粘贴复制带有脆弱漏洞的源代码,并且修改一些标识符,使得脆弱代码难以检测,该方式就可以避免这种情况)
2.3.2 从源代码中提取特征(阶段2)
该阶段提取的特征是作为指纹来帮助我们在目标系统和漏洞代码数据集之间执行比较,所以该步骤是漏洞检测的核心步骤。
在该实验中,提取的特征作为漏洞数据集的指纹存储在HBase(一种开源的NoSQL数据库,具体可参考文章 HBase 简介)中,所提取的特征有如下两个:
- MD5 哈希提取:对每个文件前缀15个令牌和后缀15个令牌进行加密并生成哈希值 h1,h2,然后将这两个哈希值进一步结合,记作h1&h2,并作为一个 Row_Key 保存到 HBASE 的大表中,这两个位置的哈希值作为每个源代码文件的唯一指纹,这有助于我们在漏洞检测期间比较源代码文件
- FNV 散列提取:这一步我们主要是使用 FNV 哈希算法来提取特征,该算法的特点是速度快且可以在很小的冲突下散列大量代码。在这个步骤中,首先我们将每个文件的总令牌分为10等份,p0,p1,p2,·····,p9,然后对每个分区应用 FNV 散列来生成 FNV 散列值,总共十个FNV散列,可以帮助我们进行比较和检测文件之间的相似度。然后我们从每个文件的每部分中选择 10 个最小的哈希,这样就收集到了 100 个哈希值,然后将他们添加到一个值,即拼接起来形成一个长整型,这就作为了另一个特征,这显示了每个文件的完整性
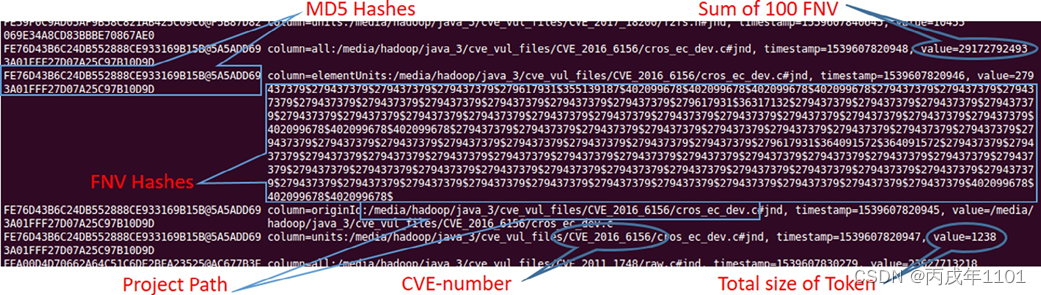
下图为一个已收集的特征的例子:
2.3.3 指纹索引(阶段3)
根据漏洞源代码的CVE号对其执行索引,它允许针对单个文件或整个系统查找所有易受攻击的文件。此外,当文件被删除、添加或修改时,我们可以更新指纹索引信息。对提取特征的指纹索引是该方法中的主要数据结构。
由于使用的是 HBASE 作为存储介质,所有的指纹索引信息都存储在 HBase 的大表中,可以随时更新、删除或编辑任何文件的任何索引信息,索引信息包括了MD5哈希值、易受攻击文件的路径、FNV哈希和存储在HBase中的每个源文件的总令牌大小。索引信息包含每个易受攻击文件的所有这些元组作为指纹,以下为索引标签,也可参考上图:
Row_key:前缀(H1)和后缀(H2)的MD5哈希值Origin_id:文件的路径或位置Element:文件的100个FNV哈希值Units:有关文件内令牌的大小All:100个FNV散列的和
2.3.4 漏洞检测(阶段4)
如框架图中最右侧的过程所示,首先将项目代码上传到 SQVDT 中,它会自动识别项目的主题,包括项目文件夹中的文件类型、大小等。然后 MapReduce() 将该主题系统平均分配给集群中的每个节点进行漏洞检测。所有过滤出的主题系统的有效文件路径都存储在 HDFS,方便 MapReduce 处理。通过对其应用不同的过滤器,即MD5散列值、组块单元计算、FNV散列、Minhash和其他值运算,从主题系统中提取所有相关特征。过滤器将主题系统的值与指纹的索引值进行比较。当主题系统和指纹数据集的特征变得100%相似时,我们定位它,检索它,并将其显示为弱点
具体步骤:
1、准备项目文件:通过 HDFS 文件系统,我们将要测试的项目上传到 Hadoop 中进行漏洞检测
2、预处理和规范化:该步骤主要是清理源代码,将源代码转为令牌序列
3、创建块并生成哈希:分别提取MD5哈希,然后分块并提取FNV哈希值,以便于保存为指纹的相同哈希进行比较
4、进行过滤:该步骤包含5个过滤器,每个过滤器都是在上一个过滤器的基础上,再次过滤
- 过滤器1:通过比较保存在HBase索引表中的哈希值来检测来自目标系统的易受攻击的文件,哈希值匹配的情况下,进行下一个过滤器
- 过滤器2:对目标系统的每个文件中的令牌总数进行计数,然后将它们与HBase中存储的指纹索引(单位)进行比较
- 过滤器3:将主题系统的文件中的100个FNV散列(元素)与指纹进行比较
- 过滤器4:Minhash 进一步评估精确克隆的结果。Minhash算法帮助我们在结果文件之间进行进一步的比较,以找到精确的克隆文件
- 过滤器5:检测器使用SSH协议(安全外壳)将主题系统文件发送到集群中的每台连接的机器。主题系统的这些文件分成块,生成它们的MD5散列并执行最终的比较任务
5、显示给用户:在得到结果后,检测器对它们进行评估、组合并显示给用户。同时,它将结果保存为记录,以供进一步评估和使用
















 8720
8720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











