






 本文介绍使用LSTM循环神经网络预测上证指数的方法。探讨了模型的设计思路、数据预处理过程及预测结果分析。
本文介绍使用LSTM循环神经网络预测上证指数的方法。探讨了模型的设计思路、数据预处理过程及预测结果分析。
一、为什么使用LSTM
循环神经网络与传统神经网络模型最大不同之处是加入了对时序数据的处理,将某支股票的长期因子数据作为时间序列,取过去一段时间内的数据作为输入值。这样做最大的好处便是保持了信息的持久化,这和我们的直观感受也是相符的。另外LSTM通过三个门的控制很好解决了循环神经网络的梯度爆炸或梯度消失问题。
二、预测前提条件
- 历史会重演
上证指数从定性上来说,是一种非线性、非平稳的序列,这种特性要求模型学习它的非线性特性和非平稳带来的周期、趋势等特性。
三、预测目标
上证指数下一个交易日的指数预测
四、样本数据
沪深300指数数据,数据时间:2005-1~2018-8,其中3000+训练集,300+测试集。
- 为什么使用沪深300?
沪深300指数与大盘相关性很大,成分分别来自深市和沪市具有优势的上市公司,最主要的是有相应的沪深300ETF可以交易,方便后续回测。
五、数据预处理
- 数据标注
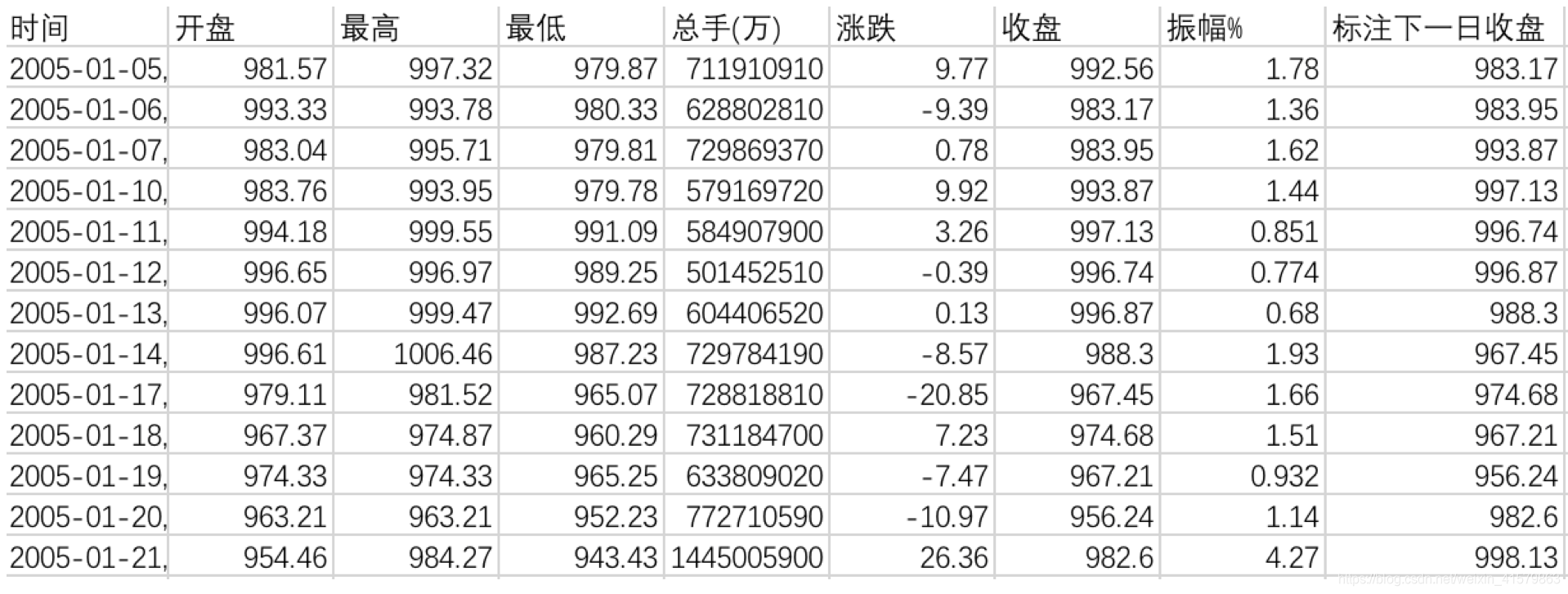
- 数据清洗
剔除样本里的异常数据,本实验未进行此操作。
- 数据标准化
将特征值减去均值、除以标准差。(均值和标准差来自训练集,千万不要使用未来数据哦)
数据一定要进行标准化,不标准化由于输入特征的差异很大,影响模型调整权重,模型会很难收敛。
六、模型
- 输入
开盘、最高、最低、总手(万)、涨跌、收盘、振幅 共7个指标,序列长度使用历史10天
- 输出
下一个交易日的收盘价
- batch size
128 (太小loss曲线波动会比较大,太大模型拟合很慢)
- 隐藏神经元个数
64
- 学习率
0.001
- 损失函数
mse = tf.reduce_sum(tf.square(y_ -y))
数据应该有个验证集,用来评价模型的,此次试验没有划分出来,所以用测试集评价模型的好坏很可能拟合了测试的数据。
七、测试结果
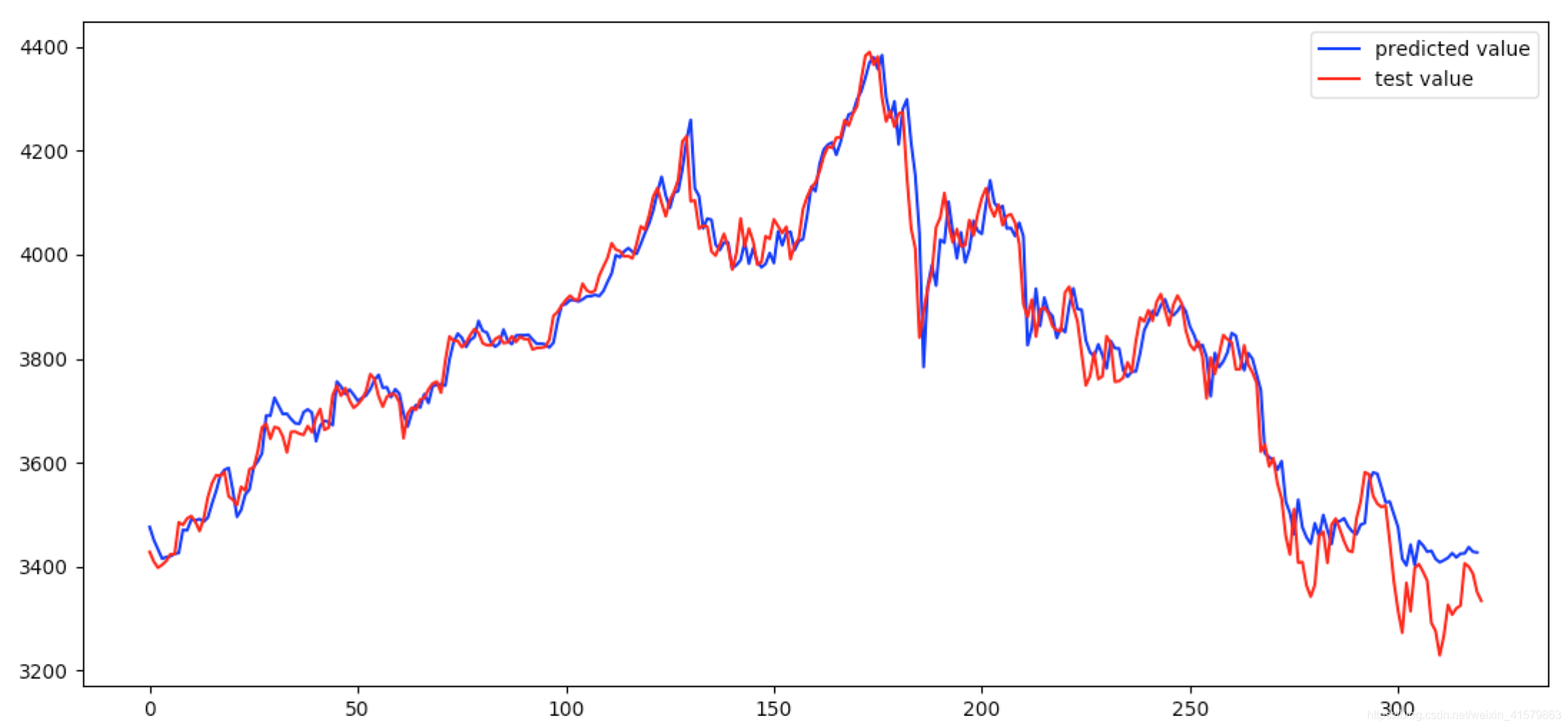
测试效果直观上感觉很好,但是这种情况更好好好分析。毕竟输入里带了上一个交易日的收盘价,预测下一个交易日收盘价,模型再差输出也会在上一个收盘价附近。
首先分析一下测试集每日的指数波动情况

再使用模型预测一下测试集每日指数,并绘制波动情况

从纵轴就可以看出测试集真实的波动相比预测值要小,虽然模型最终loss很小但是相比真实的波动误差还是比较大的。
八、回测结果
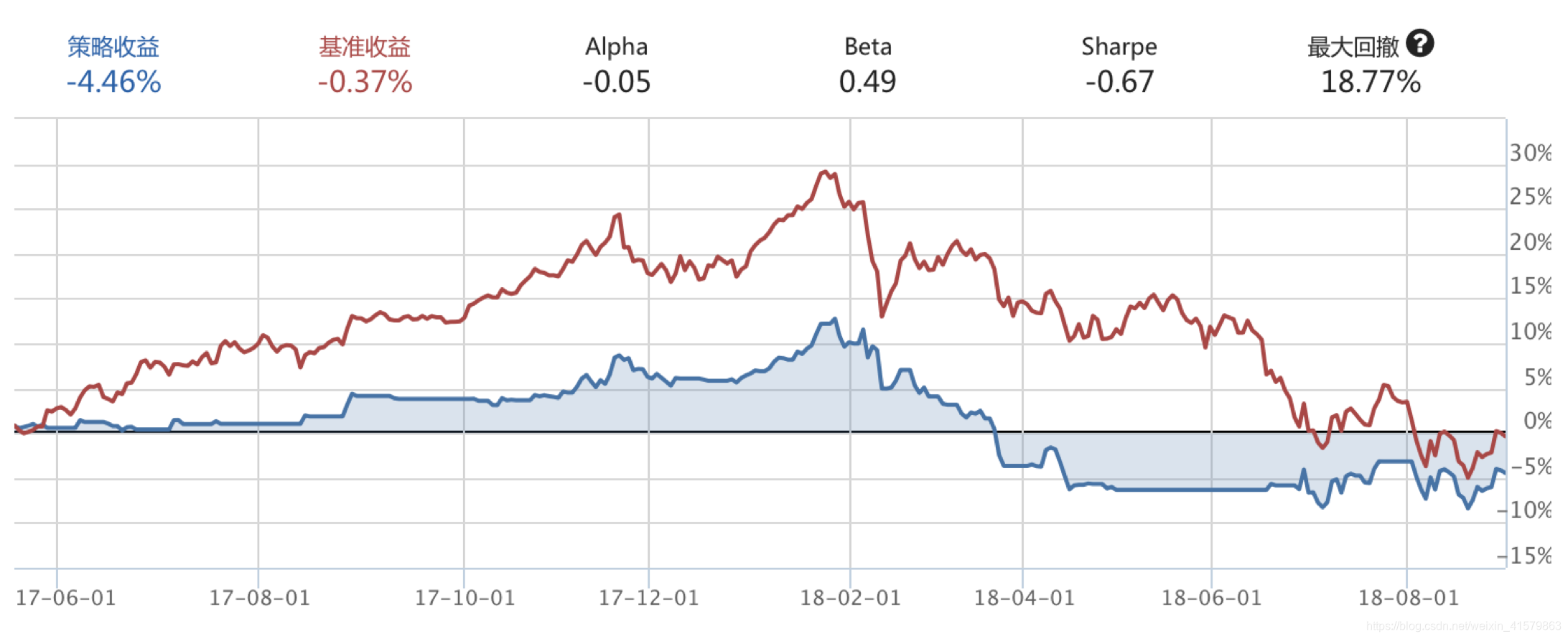
从回测上来看,模型未带来alpha,比基准收益差,也验证了上面的分析。
总结:实验是去年做的,也有些时间了,也有部分内容缺失,从价格预测价格上来看本身就不太靠谱,实验的出发点是历史会重现,首先这个问题就很难证明,另外模型要学习周期和趋势的特性,但是也存在很多很难确定的参数,例如使用历史的多久的数据作为输入,预测未来多久的收盘价等。

















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









