







LSTM长短期记忆神经网络的学习与实现
「公开课干货分享」LSTM长短期记忆神经网络的学习与实现
以下是训练过程:
from pandas_datareader.pandas_datareader import wb
import torch.nn
import torch
import torch.optim
import csv
from IPython.display import display
import pandas as pd
import numpy
import matplotlib.pyplot as plt
class Net(torch.nn.Module):
def __init__(self,input_size,hidden_size):
super(Net,self).__init__()
self.rnn = torch.nn.LSTM(input_size,hidden_size)
self.fc = torch.nn.Linear(hidden_size,1)
def forward(self, x):
x = x[:,:,None]
x, _ = self.rnn(x)
x = self.fc(x)
x = x[:,:,0]
return x
countries=['BR', 'CA', 'CN', 'FR', 'DE', 'IN', 'IL','JP', 'SA', 'GB', 'US']
dat = wb.download(indicator='NY.GDP.PCAP.KD',country=countries,start=1970,end=2016)
df = dat.unstack().T
df.index = df.index.droplevel(0)
year_num, sample_num = df.shape
countries = df.columns
years = df.index
# with open('F:/tracker_programe/lstm_test/1970_2016.csv', 'w') as f:
# writer = csv.writer(f)
# for row in df:
# for col in row:
# writer.writerow(col)
# print(df)
net = Net(input_size=1, hidden_size=5)
print(net)
df_scaled = df / df.loc['2000']
years = df.index
train_seq_len = sum((years >= '1971')&(years <= '2000'))
test_seq_len = sum(years > '2000')
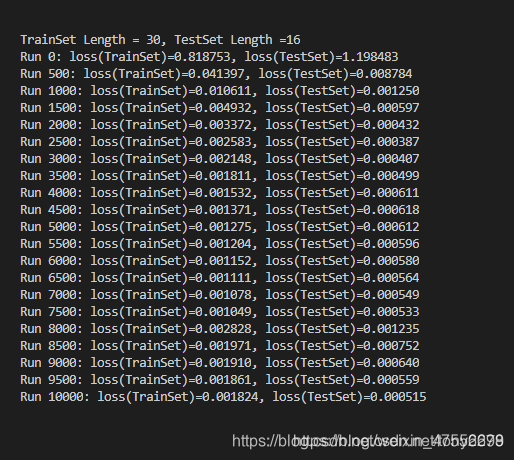
print('TrainSet Length = {:.0f}, TestSet Length ={:.0f}'.format(train_seq_len, test_seq_len))
inputs=torch.tensor(df_scaled.iloc[:-1].values,dtype=torch.float32)
labels=torch.tensor(df_scaled.iloc[1:].values,dtype=torch.float32)
criterion = torch.nn.MSELoss()
optmizer = torch.optim.Adam(net.parameters())
for step in range(10001):
if step:
optmizer.zero_grad()
train_loss.backward()
optmizer.step()
preds = net(inputs)
train_preds = preds[:train_seq_len]
train_labels = labels[:train_seq_len]
train_loss = criterion(train_preds,train_labels)
test_preds = preds[-test_seq_len]
test_labels = labels[-test_seq_len]
test_loss = criterion(test_preds,test_labels)
if step % 500 ==0:
print('Run {:.0f}: loss(TrainSet)={:.6f}, loss(TestSet)={:.6f}'.format(step, train_loss, test_loss))
preds=net(inputs)
df_pred_scaled=pd.DataFrame(preds.detach().numpy(), index=years[1:], columns=df.columns)
df_pred=df_pred_scaled*df.loc['2000']
display((df_pred.loc['2001':]-df['2001':])/df['2001':])
# Code borrow from:凌空的桨
# https://blog.csdn.net/baidu_36669549/article/details/85267766


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









