






时常在用像FC, CNN, Transformer这样的结构来组成一些网络,解决各种问题,但很少去探索这些东西到底在做些什么?通过一些深层堆积到底表达了一个什么样的数学结构?它们之间的关系是什么?下面我就个人的一些理解来讨论一下,若有不正确,也请指教一下。
1. 全连接FC
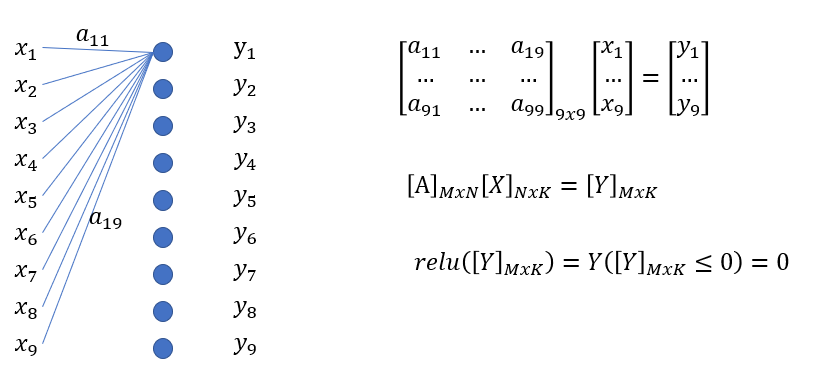
FC的示意
这里我以输入和输出均为9为示例,原因是后面画cnn时用的是3x3,对应起来。
图中的全连接有9个神经元,每个input x都和一个神经元连接,每个连接线都是一个要学习的参数,这样很容易把x和y的关系用矩阵表达出来,像图上那样。所以一个全连接层就是一个MxN的矩阵,其中N为Input X的长度,M为output Y的长度。全连接层的矩阵[A]里所有的元素都不同,都需要学习。全连接是处理个人为一维的input,也就是个体X是一个向量。这里说个体X是一个向量是区别后面图像,图像虽然有rgb x 长 x宽 这三个维度,本质上拉直也是一维向量。
写成更一般的形式就是图中第二行,其中K表示个体的个数,可以理解为训练时的batch size,这里是用同一个矩阵来处理所有的个体向量。
那么relu等在做一个什么事?如果用一个常见的relu,表达式由第三行表示,就是把一些小于0的元素都乘以0,大于0的元素都乘以1,与上述结果的Y矩阵点乘。所以这个矩阵元素都是0,1,但0,1的位置在哪里我还不知道,取决于Y,所以这里我也很难用一个矩阵来表达这样的操作,我就先用一个函数att()表示。这里att表示attention,也就是整个MxK维度上给Y加权重,权重值不是0就是1,可以先记着,与后面的transformer来对比。
至于dropout,其实也是一个加权重,比如我把第4个神经元drop掉,就把矩阵第4行全用0,其它地方用1乘就行了,那么本质上和relu是一样的,但它比较明确的是要drop就是drop一行,至于drop哪一行就随机了。
所以综上看,FC相关的就两个基本构成,一个是需要学习的矩阵A,一个是att()函数。一层的FC+relue可以表示成 , 两层就是
,至于它到底在模拟什么函数,可以有自己的看法。
不过在这里,我的感觉倒不能说relu什么的本身加了非线性,感觉更像一个分类函数,就像对于类别1,它的表达式是怎样的,类别2,表达式是怎样的。
我们可以想象一个二层的网络FC+relu+FC吧,已经训练好了,对于不同的input在做一个预测。
首先对某个样本X1, 是训练好的,
是确定的向量了,那它什么地方小于0,什么地方大于0都确定了,所以relu也就确定了,可以用一个矩阵R1来表示,而
也是训练好的,所以输出可以用
表示,这是一个线性的,无论输入是什么A2和A1已经固定,只有和x1拥有相同R1的输入,会和x1有一样的转化矩阵。但对于一些Input,由于
中大于0和小于0的地方可能又不同,所以R就不同。
对于上面的例子,R理论有 29 (因为矩阵是9x9的)种,所以仅仅对这个例子就有 这样的线性表达式,当然如果层数多了,维度大了,而且还有各种relu的形式,可能一个网络能表达的线性表达式已经大到无可附加了,所以就处理各种不同的问题了。
同时也可以感觉到,att()其实就是一个函数的分类器。但为什么神经网络什么关系都能模拟这样的结论,我现在就还没体会到了,也可能是无线种分类就等于连续模拟吧。但其实也可以理解,这种函数的分类有点像微积分,对于不同的段用不同的表达,当分段无穷大时,就趋近于连续了。
2. 卷积网络CNN
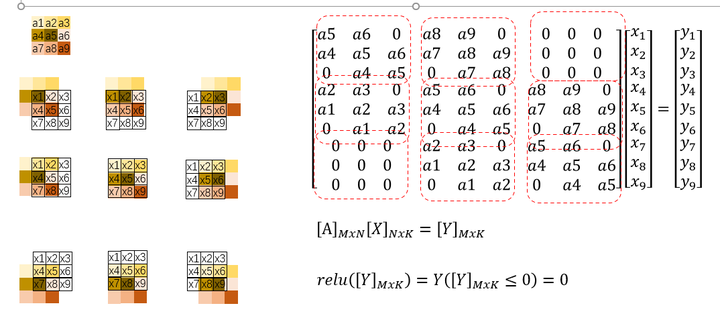
CNN示意
这里我们以一个3x3的input输入为例子,input是x1~x9, 卷积核3x3用a1~a9来表示,图中每个a的颜色不同。
我们可以看出y1用到的input是x1,x2,x4,x5,对于卷积核里的元素是a5, a6, a8, a9,那个y1的表达式可以用图中矩阵的第一行来表示,我们依次移动卷积核来看其它Y的表达是怎样的,最后就得到图中的矩阵。
可以看出,卷积的本质也是一个矩阵,只不过这个矩阵里有特定的位置是0,而特定的参数也被放在特定的位置上,并且我们可以看出有多服用的参数与其位置也被决定了,所以CNN本质上是一种reduced form的FC,那这个矩阵的维度是由输出长度(这个和你的kernel, padding等设置都有关)有关,而学习的元素的个数与kernel设计有关,两者设置好了,相应的位置也被确定了。
同里relu也是一个att()函数,而poolling和up sampling等可以表达为一个特定矩阵(不需要学习的矩阵)。所以很多CNN堆叠起来表达的也就是类似于 这样的式子,只不过这里的A是特殊设计的,有约束或都是先验知识的介入,同时要学习的参数少了。
至于其它的基于它组成的一些元素和个体,也可以用这样的表达,如resnet可以用 来表达,channel attention可以用
表达,当然上面表达肯定不准确,只是提供一个思路而已。
3. Transformer
tranformer和FC是怎样的关系?首先它们都在处理一维向量的个体,不同的是FC处理时认为不同的个体之间是无关的,但transformer认为不同个体之间是有关的,要考虑这个关系,有点个XY联合分布其中X和Y是否独立的那个意思。
首先Input是一个长度为L个数为K的一组向量, input(LxK),在embedding后变成了一个长度为M个数为K的矩阵。有时候embedding会用一个FC层来学习,这里也可以用一个 的矩阵来表示为
其实本质上就是把每个单词原来是L维度来表示,现在用M维度来表示。positioning encoding我们就不说了,不改变矩阵。
后面我们简单的说一下KQV了,这三个可学习元素的构成还是用FC来构成,所以其表达就可以用矩阵来表示。V是直接作用于输入的向量组,它的结果其实就是不同向量组的另一种表达方式,而K,Q学习了一个attention的东西,当这个结果作用到V时,其实就是把比如第一个向量的最终输出写成所有向量输入的线性组合,而这个线性组合的因子就是attention或是score,最后接一个FC其实又是一个矩阵,所以一个tranformer block的表达为
这里的 相比于relu等一方面需要不同向量之间的联系,也就是一定要一批一批进入,另一方面也有更多的形式,接近于无限,因为它不只限于0,1构成,而是0~1之间的任意数都有可能。这样它可以分段模拟的函数更趋近于无限。
至于Multi-head attention和one head的区别在于,KQV其实都可以用相同大小的矩阵表示,由于Multi-head是分组attention,所以如果one head的K比如说是一个100x100个这样的矩阵,每个元素都有值,都要学习,那么multi-head如果把它分成10组,它也是一个100x100的矩阵,只不过只有10个10x10大小的块有要学习的值,且以块的方式占据这100*100的对角方位,其它地方为0了。其实上也是一种reduced form的one head block.
4. 反向传播
其实这些元素都可以用矩阵的形式表达还方便理解反向传播了。















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









