






在机器学习算法的帮助下我们能够处理体量巨大的数据,我们可以向数据询问一系列的问题,希望机器学习能给出答案。比如:某个数据点和哪些相似?通过对这些数据的分析能否总结出某种模式?给出历史趋势数据的前提下,能否判断未来走势? 诸如此类的问题都适用于在机器学习领域寻找答案。
问题来源
今天的议题是怎么把数据分类。比如,你正在为一家医疗影像设备公司工作,假如你已经找到了识别肿瘤细胞的方法,但是如果能有一种方法可以找出肿瘤细胞群的中心位置就更好了,这样就可以使用机器人精准地达到目的地并清除它们。我们需要找出一种聚类算法,这就是今天要特别讨论的 k-means。
聚类算法
聚类算法通常来讲就是要按照相似性给数据分类。如果你是一个电商经营者,就可以用聚类算法识别出各种购物者的类型。你可能会发现有一种顾客在浏览三五个产品页面之后就会下单购买,另外一组用户可能需要浏览多达15个页面还要看很多评论才决定购买,而且会是一单高价值的购买行为,另外你可能还会注意到有一组冲动消费型的用户,他们不用浏览太深入就会发生多次小额购买行为。一旦完成了对这些线上消费者的人口调查,你就能更好地优化站点提高销售额。因为知道了自己的客户中存在冲动型消费者,你就可以针对性地添加一些功能刺激这部分消费者。
k-means
和近邻算法(k-nearest-neighbor)一样,k-means 中的 k 也是一个数量值,是算法中的重要参数。需要特别指出的是,这里的 “k” 就是我们要在数据中找出来的簇(分组)的数量。不幸的是,很难在问题解决前知晓这个数量值,所以 k-means 算法通常需要在**另外一个算法的帮助下找到最恰当的 k 值**。
问题是 k-means 算法会把数据分割成 k 个独特的簇, 但是算法不会告诉你 k 值是否正确。比如,你的数据在理想情况下应该被分成5个簇,但是如果人为地把 k 设定为3,那么你就会得到3个簇,当然这些簇的规模肯定大了一些,相对于理想状态下的5个簇,精确度也下降了。
这个算法有优点也有短板,为了使用 k-means 算法你需要预先知道k的值,或者用另外的算法帮你猜测这个值。 k-means 只是帮你把数据分到不同的类别里,你还需要做些额外的工作找到簇的合适数目。
在今天例子中我们先设定簇的数目为3,下一篇文章将会讨论自动猜测 k 值的算法,最常用到的就是**误差分析法**结合**反复调用 k-means 算法以优化结果**,使误差最小化。
过程
虽然 k-means 算法简单,但是如果用在多维数据集上会表现出它强大的生命力。今天我们会处理一组2维数据,下次我们再把它做的复杂些。
算法过程如下:
- 以散点图的方式,可视化数据。
- 创建 k 个新的数据点,随机分布在图上,把这些数据点作为簇的“重心”,也称“簇重心备选者”。
- 重复下面的过程:
- 把距离重心最近的那些数据点分配给它
- 移动重心的位置到所有属于它的数据点的平均位置上
- 如果重心的位置在最后一步中移动了,继续重复上诉过程,否则退出。
这是一个迭代过程。可能会迭代两三次甚至数十次,但是最终你的簇重心会靠近目的地并停止移动,最后会得到你想要的簇集合。
局限性
该算法和很多我们在这个系列中将要讲到算法的一样,容易陷入**局部最优解**。如果你多运行下面的例子几次,就会发现每次得到的结果都会有差别,这意味着一些结果陷入了不同的局部最优解。
算法从一些随机的,本身就容易受局部最优影响的种子开始,因为永远不知道算法具体的开始位置和结果的走向,种子的状态会导致局部最优还是全局最优?这些都无从知晓。就像遗传算法一样,能跳出局部最优解的一个方法就是使“解”发生一点儿突变。在此 k-means 例子中, 我们会在算法中加入一条规则,就是当发现重心数据点经过一轮迭代后没有发生移动,那么就在一个在随机方向上推一把。结果就是它可能又回到了原来的位置,也可能找到了一个新的解。这个推动不要大到让计算从回起点,但是也要足够把它踢出某个局部最优区域。另外一个使用的技巧被称之为“机器委员会”,如果你的算法能结束的很快或者能使用并行计算,那么这个技巧很管用。其实很简单,我们运行 k-means 算法3次,5次,51次或10000次,选择那些最经常得到的解。“机器委员会” 是指一些人选择在不同硬件上运行并行算法,一个字面上的机器委员会能给这些“解”投票。
代码
我们开始代码部分,和至今为止的其他例子不同,我会放弃面向对象的方法而采用直接了当的策略。解决问题的方法有很多,我喜欢OOP,但是重点是不要太依赖于习惯,还有就是我们在例子中使用的数据只是二维的,我愿意把这个算法写成可以处理任何维度的数据。现在来看看我们要使用到的数据,非常简单的数组,每个数据中的两个值分别表示x,y。
var data = [
[1, 2],
[2, 1],
[2, 4],
[1, 3],
[2, 2],
[3, 1],
[1, 1],
[7, 3],
[8, 2],
[6, 4],
[7, 4],
[8, 1],
[9, 2],
[10, 8],
[9, 10],
[7, 8],
[7, 9],
[8, 11],
[9, 9],
];
接下来我们定义两个方法,给定一个点的列表,我想知道其中在x和y两个方向上的最大值和最小值,还有在两个方向上的跨度(循环数组,计算数组内部 X 和 Y的最值,然后求范围)。比如在X方向上是从1到11,在Y方向上是从3到7,了解这些有利于我们随机产生簇重心时参考。
我们应该在头脑中始终保持一个理念,就是要让函数在处理不同维度的数据时具有通用性:
// 给定一个n维数组extremes,获取这个数组在不同维度的范围数组 ranges 例如上面的数组 [1, 11];
function getDataRanges(extremes) {
var ranges = [];
for (var dimension in extremes) {
ranges[dimension] = extremes[dimension].max - extremes[dimension].min;
}
return ranges;
}
// 把每一个维度的参数提取成为公共数据,获取公共数组的最值,再使用上面的函数获取不同维度的范围。在这个范围中进行差值,默认k,计算默认中心的平均值。
function getDataExtremes(points) {
var extremes = [];
for (var i in data) {
var point = data[i];
for (var dimension in point) {
// 设置默认的最值
if (!extremes[dimension] ) {
extremes[dimension] = {min: 1000, max: 0};
}
// 如果一个值小于最值,进行取代
if (point[dimension] < extremes[dimension].min) {
extremes[dimension].min = point[dimension];
}
if (point[dimension] > extremes[dimension].max) {
extremes[dimension].max = point[dimension];
}
}
}
// 最终返回这个数组的最值集合
return extremes;
}
getDataExtremes() 函数用来遍历每一个数据点并在所有维度上找出最大值和最小值(需要注意的是,这里有个一个硬编码的数值“1000”,你需要根据具体情况做改变)。
getDataRanges() 函数用来辅助返回每个维度的范围(最大值减去最小值)。
下一步我们定义 k 个簇并初始其随机的重心位置
function initMeans(k) {
if (!k) {
k = 3;
}
while (k--) {
var mean = [];
for (var dimension in dataExtremes) {
mean[dimension] = dataExtremes[dimension].min + (Math.random() * dataRange[dimension]);
}
means.push(mean);
}
return means;
};
用该方法我们可以在数据集范围之内随机地生成几个新的数据点,一旦我们拥有了这些像种子一样的重心,就可以进入k-means循环过程了。如前所述,该循环过程包括首次为重心分配数据集里离该重心最近的那些点给它,然后移动重心位置到达这些点的平均重心位置,重复此过程直至重心停止移动。
function makeAssignments() {
for (var i in data) {
var point = data[i];
var distances = [];
for (var j in means) {
var mean = means[j];
var sum = 0;
for (var dimension in point) {
var difference = point[dimension] - mean[dimension];
difference *= difference;
sum += difference;
}
distances[j] = Math.sqrt(sum);
}
assignments[i] = distances.indexOf( Math.min.apply(null, distances) );
}
}
上面的函数会被我们的遍历函数调用以计算每个点之间的欧几里德距离和簇的重心位置。需要注意的是,该算法会遍历每一个点到簇重心的距离,这是一个计算时间复杂度为O(k*n) 的算法,复杂度不是很恐怖,但是如果数据集比较庞大或者簇的数目较多,可能计算就比较密集了。不过可以通过一些途径来优化,我们会在后续文章中谈到。有一个我们现在就可以着手处理的是Math.sqrt()的效率问题,其实这个调用不必出现在对每个点的迭代计算过程中,一旦确定了分配列表,本例中这个列表就是一系列点的索引,我们就可以用所有点位置的平均值来更新簇重心的位置了。
译者注:
欧几里德距离是指在欧式空间中两点间的距离,计算公式如下,假设p,q两点为欧式空间中的两个点,其各自的空间坐标为: p(p1,p2,p3,... pn)
q(q1,q2,q3,... qn)
则两点间的距离可表示为:
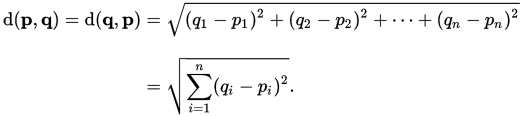
function moveMeans() {
makeAssignments();
var sums = Array( means.length );
var counts = Array( means.length );
var moved = false;
for (var j in means) {
counts[j] = 0;
sums[j] = Array( means[j].length );
for (var dimension in means[j]) {
sums[j][dimension] = 0;
}
}
for (var point_index in assignments){
var mean_index = assignments[point_index];
var point = data[point_index];
var mean = means[mean_index];
counts[mean_index]++;
for (var dimension in mean){
sums[mean_index][dimension] += point[dimension];
}
}
for (var mean_index in sums){
// console.log(counts[mean_index]);
if ( 0 === counts[mean_index] ) {
sums[mean_index] = means[mean_index];
// console.log("Mean with no points");
// console.log(sums[mean_index]);
for (var dimension in dataExtremes){
sums[mean_index][dimension] = dataExtremes[dimension].min + ( Math.random() * dataRange[dimension] );
}
continue;
}
for (var dimension in sums[mean_index]) {
sums[mean_index][dimension] /= counts[mean_index];
}
}
if (means.toString() !== sums.toString()) {
moved = true;
}
means = sums;
return moved;
}
moveMeans() 方法在开始处调用 makeAssignments() 。一旦分配工作结束,我们需要初始化两个数组:"sums" 和 "counts"。既然我们要计算算数平均值,我们就需要知道所有点在每个维度上的总和还有点的数量。
我们启用三个遍历过程:
一:遍历每个簇重心,初始化数组sums在每个维度上的值为0,以及数组数量counts也为0。所以sums数组是一个多维数组,原因就在于我们处理的是每个簇中的每个点在每个维度上的数据。
二:遍历每个被分配的数据点计算出每个簇重心拥有的数据点的数量,并且遍历数据点的所有维度填充 sums 数组。到此,我们拥有了为簇重心计算新位置的所有数据。遍历结果,为每个簇重心计算新的平均位置,并把重心移动到该位置。
三:检测簇重心是否还有数据被分配给它,如果没有,我们就给它一个随机的新位置,就是我们之前说的踢它一脚。
最后,巡视所有的簇重心是否还有移动情况,并返回真或假。使用如下 setup 函数开始执行算法:
function setup() {
canvas = document.getElementById('canvas');
ctx = canvas.getContext('2d');
dataExtremes = getDataExtremes(data);
dataRange = getDataRanges(dataExtremes);
means = initMeans(3);
makeAssignments();
draw();
setTimeout(run, drawDelay);
}
function run() {
var moved = moveMeans();
draw();
if (moved) {
setTimeout(run, drawDelay);
}
}
我们需要的设定都在setup()中初始化完成,之后 run() 函数检测算法是否停止了,并根据时钟的间隔设定循环执行,我们也就能实时看到算法的运行情况了。
k-medians
使用加权平均,结果可能受到极值影响,使用中值进行聚类效果更好。
k-means算法存在一个问题,其实并不是算法本身的问题,而是算数平均值自身存在的缺陷,就是当数据中出现了某些数据飞地(偏离整体数据很远),会给算数平均值带来不利影响。比如,你所在的公司有五个人每年的薪水是5万元,但是有另外一个人每年的薪水高达100万,那么薪水中间值会是5万(能代表公司的薪水情况),而平均值达到了20万(完全不能代表公司薪资情况)! 这种问题当然也会在k-means算法中发生。如果你拿到的数据中有飞地情况,你会发现k-means算法得到的结果很糟糕,一个解决办法就是使用 k-medians 代替 k-means, 二者算法相似,只是用中值代替平均值,这样可以滤掉数据飞地的影响。另外,我认为在计算效率上也会比平均值法更高效。
结果
k-meeans 算法对于我们定义的整洁干净的数据来说运行的非常完美。很显然,如果数据脏乱,也会像其它算法一样遇到困难。如果不厌其烦地多运行几次我的代码,你也会遇到陷于局部最优解的问题。这就需要通过“机器委员会”的技巧来解决了:通过一次次的运行,那些经常得出的结果就是我们要的答案。















 6997
6997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









