






- 生成
l=[['green',1],['blue',2]]
df=pd.DataFrame(l)
df.columns=['color','class']
- 读取
y = train_data["Survived"] #生成 pandas.core.series.Series
y= train_data["Survived"].tolist() #生成list
pandas.core.frame.DataFrame
test_data.head() #头部5行
读取指定列
y=train_data['label'] #读属性label这一列
y=train_data[['label','name']] #多个属性列,产生
读取行
y=train_data.iloc[1] #读第二行
y=(train_data.iloc[1])['label'] #读第二行列标签=label处
#也可以整体读取好多行
index=np.arange(0,100)
new_df=df.iloc[index]
- 与文件相关
pd.read_csv('E:\\SAR\\exp3_2\\SAR_datasets_info.csv',names=['','']) #否则第一个会被当成header
pd.read_csv('E:\\SAR\\exp3_2\\SAR_datasets_info.csv',names=None) #否则第一个会被当成header
df.to_csv('E:\\SAR\\exp3_2\\SAR_datasets_info_train.csv',index=False) #index不写入
- 长度
df.shape
#行数df.shape[0]
#列数df.shape[1]
- 排序
根据值排序
df=df.sort_values(by='a') #如果有列名
df=df.sort_values(by=0) #如果没有列名
df=df.sort_values(by=['a','b'],ascending=(False,False))#多列排名,a的优先级高于b
- 随机分割训练集和验证集
import pandas as pd
df=pd.read_csv('E:\\SAR\\exp3_2\\SAR_datasets_info.csv')
index=np.arange(0,df.shape[0])
np.random.shuffle(index) #直接对index打乱,无需赋值
train=index[0:int(len(index)*0.8)]
valid=index[int(len(index)*0.8):]
tdf=df.iloc[train]
vdf=df.iloc[valid]
tdf.to_csv('E:\\SAR\\exp3_2\\SAR_datasets_info_train.csv',index=False)
vdf.to_csv('E:\\SAR\\exp3_2\\SAR_datasets_info_valid.csv',index=False)
y=pd.get_dummies(df) #对列中非数字部分进行二值化,若已经是数字就不会改变了

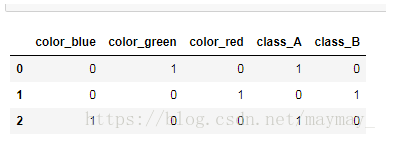
- groupby
bert_scores=df.groupby(['query','tags']).agg({'bert_3':'mean'})















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









