







目录
引入库(数据分析常用三件套)
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline读取文件(excel、csv)
//读取excel文件
data = pd.read_excel("C:\del\desktop\111.xlsx",sheet_name="Sheet1")
//读取csv文件
data = pd.read_csv("Data_Path")Tips:注意,由于python语言会将“\”当作转义字符,因此在填写文件地址时,一定要将“\”字符转换成“/”,特别是当出现下面这个报错的时候,那就是地址写错了!!!
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escapec
查看数据集
df.head(10) //查看前10行的数据
df.shape //显示数据集的大小,如行和列的总数
df.info() //查看每个变量的数据类型,返回变量、数据类型、内存使用量和关于每个变量的缺失值情况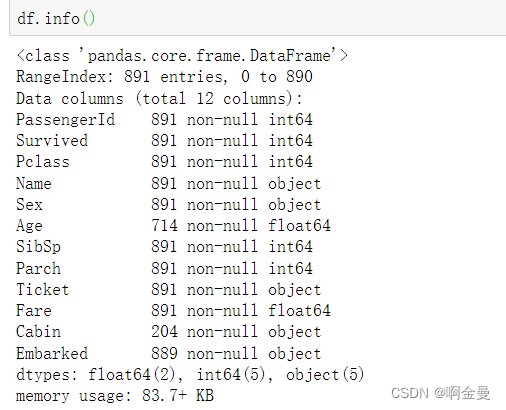
也可以使用isnull方法检查 "Age" 和 "Cabin" 两列中缺失的数值

填充缺失值
很多时候我们需要将缺失值替换成有效的数值。
虽然可以通过 isnull() 方法建立掩码来填充缺失值,但是 Pandas 为此专门提供了一个fillna() 方法,它将返回填充了缺失值后的数组副本。
用一个单独的值来填充缺失值:
data.fillna(0)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2085
2085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









