







10年前的经典论文,GAN,提出了生成对抗学习网络的概念。
图像生成式网络,理解的话,就是从噪声或者是mask中,生成或者复原图像。
嗯,说起生成网络,这几天,NLP方面的话,包括GPT为代表的文本生成类模型在通用的任务上表现不错,而目前以SD为主干的图像生成网络也是比较火热的。应用上看看DALLE系列。
嗯,本文是笔者对GAN网络的浅显的理解,有个人局限性,仅供分享,参考。
图像生成的本质:
图像生成,从字面上就可以理解,生成一张图像。而把这张图拆解一下,以256*256*3的自然图像为例。其中,256*256代表图像的尺寸,3代表图像通道数,一般可以为GBR,或者其他?即三原色构成。
那这幅图就是由256*256*3个像素点构成,而不同点位上的像素点的值这里我们设定为 整数 0-255代表,不同的数值代表不同的灰度。那这张图,就是由256*256*3 以及256种可能的灰度构成。
在这里,如果我们需要一个全黑的图像,那我们就使得3个通道中所有的像素点的值都为0;如果是全红,那就使得GBR中,第三个通道R的数值为255,其余通道数值为0;以此类推。通过对同一像素点位的3个通道的数值分别在(0-255)进行赋值,就可以得到不同颜色的点。
而就像小朋友进行涂色游戏一样,我们使用不同的颜色在不同的区域赋值,组合起来,就能生成一张256*256*3的自然图像了。
而虽然我们并不能直观的看到,但是深度网络可能会学习到不同自然图像中各个像素点位的独立的以及不同像素点中的关联信息,从而完成目前CV中的分类,分割,检测等任务。
而图像生成,则是网络通过学习,获取在256*256*3的空白画布,或者是mask,或者是其他被遮掩的图像中,各个像素点位上可能的像素值。
在此之前,会有人尝试通过计算不同图像中,各个点位上的像素点值的概率分布(或者是其他复杂概率模型),从而确定实际像素点的值。也有人尝试使用神经网络进行计算生成。而这篇论文中,作者提出了生成对抗的思想,用于实现图像生成。
供参考:
生成模型综述——深度学习第二十章(一) - 知乎 (zhihu.com)
生成对抗网络主要思想:
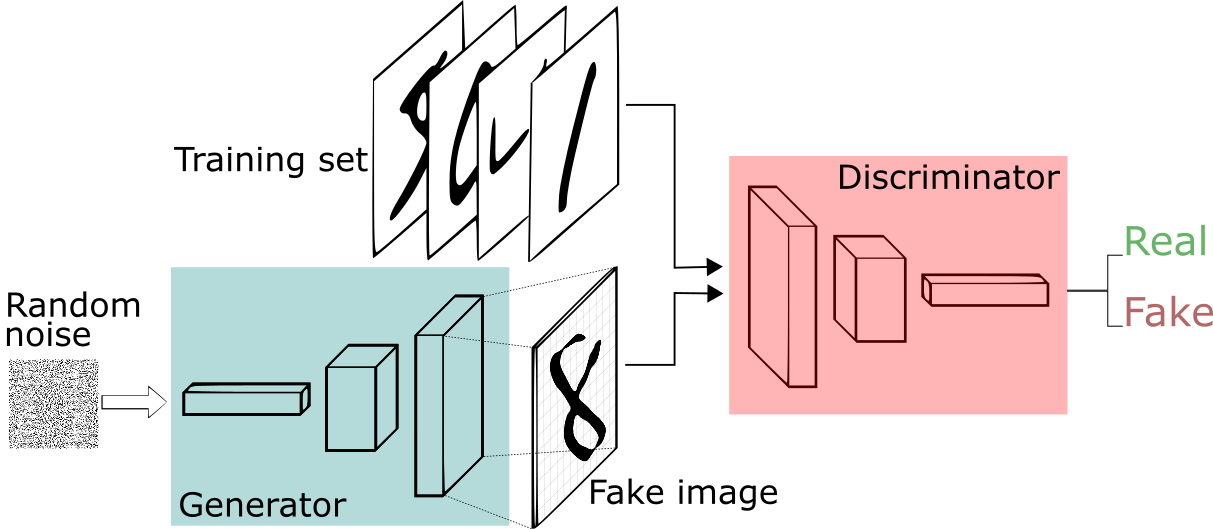
从论文名称中很好理解,生成对抗就是又有生成,还有对抗。那生成就是会有一个生成器,以及对抗的对象——判别器,去进行对抗。从图示可以看到,从左到右就是整个网络结构,其中。Generator是生成器,负责从随机噪声中生成图像。Discriminator是判别器,输入有两个来源,一个是生成器生成的Fake image,另外一个则是训练数据。输出判别结果,一般为0-1的概率值,概率值越大,是真的可能性越高。
最终,如果GAN训练成功,生成器将能够产生与真实数据几乎不可区分的样本,而判别器将在判断真假方面变得无能为力,即对于任何输入样本,输出一个接近0.5的概率,表明它无法确定样本是真是假。
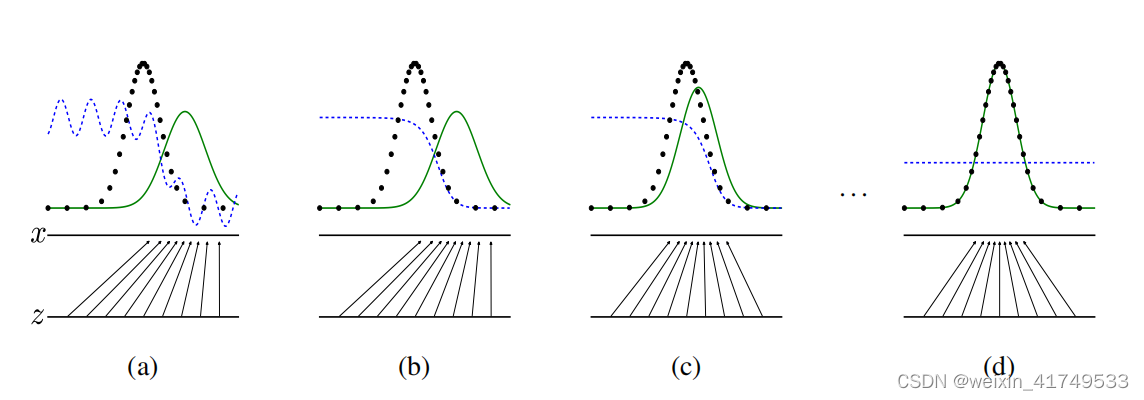
生成对抗网络:
















 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









