





 本文提出了一种新型生成对抗网络生成器架构,借鉴风格迁移,实现了高级属性的自动学习和无监督分离,同时提供了更精细的控制和随机变化的处理。新架构在性能和插值质量上有显著提升,并介绍了评估方法。
本文提出了一种新型生成对抗网络生成器架构,借鉴风格迁移,实现了高级属性的自动学习和无监督分离,同时提供了更精细的控制和随机变化的处理。新架构在性能和插值质量上有显著提升,并介绍了评估方法。
Tero Karras
NVIDIA
tkarras@nvidia.com
Samuli Laine
NVIDIA
slaine@nvidia.com
Timo Aila
NVIDIA
taila@nvidia.com
We propose an alternative generator architecture for
generative adversarial networks, borrowing from style
transfer literature.
我们提出了一种用于生成对抗网络的替代生成器架构,该架构借鉴了风格迁移文献中的理念。新的架构导致了高级属性(例如,在人脸训练中的姿态和身份)的自动学习和无监督分离,以及生成图像中的随机变化(例如,雀斑、头发),并且它能够实现直观的、特定规模的合成控制。
新的生成器在传统的分布质量指标方面提升了现有技术水平,明显改善了插值属性,并且更好地解构了变化的潜在因素。为了量化插值质量和解构,我们提出了两种新的自动化方法,适用于任何生成器架构。
最后,我们引入了一个新的、高度多样化和高质量的人脸数据集。
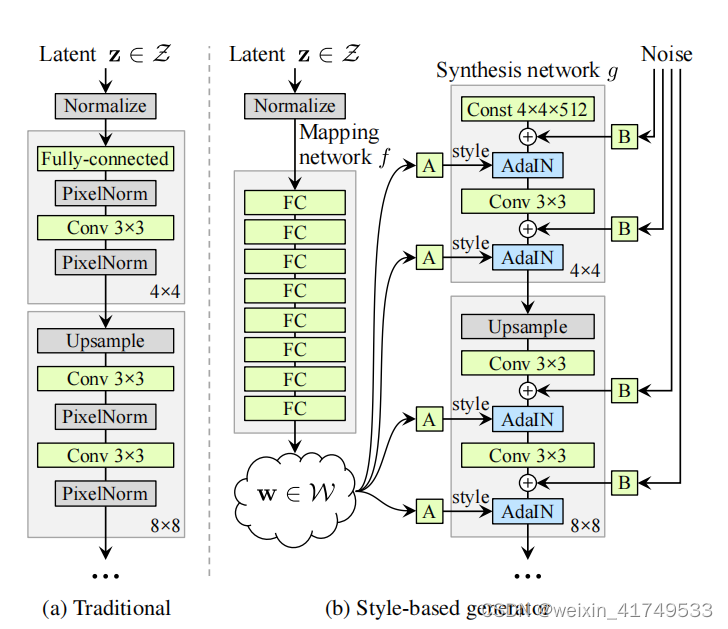
模型结构:
Our generator starts from a learned constant input and adjusts the “style” of the image at each convolution layer based on the latent code, therefore directly controlling the strength of image features at different scales.
论文中,设计了一个新的生成器,通过在每个卷积层中加入可调整的风格,以及噪声,从而得到不同风格的生成结果。
. While a traditional generator [
30
] feeds the latent code though the input layer only, we first map the input to an intermediate latent space W, which then controls the generator through adaptive instance normalization (AdaIN) at each convolution layer. Gaussian noise is added after each convolution, before evaluating the nonlinearity. Here “A” stands for a learned affine transform, and “B” applies learned per-channel scaling factors to the noise input. The mapping network
f consists of 8 layers and the synthesis network
g consists of 18 layers— two for each resolution (
4
2
−
1024
2 ). The output of the last layer is converted to RGB using a separate
1
×
1 convolution, similar to Karras et al. [
30
]. Our generator has a total of 26.2M trainable parameters, compared to 23.1M in the traditional generator.
传统的生成器[30]只通过输入层提供潜在代码,我们首先将输入映射到一个中间潜在空间W,然后在每个卷积层通过自适应实例归一化(AdaIN)来控制生成器。在每次卷积之后,先加入高斯噪声,然后再计算非线性。这里的“A”代表学习到的仿射变换,而“B”将学习到的每通道比例因子应用于噪声输入。映射网络f由8层组成,合成网络g由18层组成,每个分辨率为2层(4 2−10242)。最后一层的输出使用单独的1×1卷积转换为RGB,类似于Karras等人的[30]。我们的生成器共有26.2M的可训练参数,而传统只有23.1M。
. The AdaIN operation is defined as
其中:
x_i是来自内容图像的特征图在某个层的第i个通道的特征激活。µ(x_i)和σ(x_i)分别是x_i的均值和标准差,这些统计量是逐通道(对于每个特征图的实例)计算的。y_s,i和y_b,i是缩放和偏移参数,它们是从风格图像中学习而来的。这些参数适应了风格图像的特征分布,其中y_s,i对应于风格图像特征的标准差,y_b,i对应于均值。

Properties
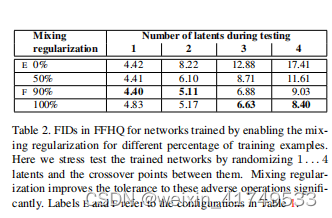
1、Style mixing
To further encourage the styles to localize, we employ mixing regularization, where a given percentage of images are generated using two random latent codes instead of one during training. When generating such an image, we simply switch from one latent code to another — an operation we refer to as style mixing— at a randomly selected point in the synthesis network. To be specific, we run two latent codes
z
1
,
z
2 through the mapping network, and have the corresponding
w
1
,
w
2
control the styles so that
w
1 applies before the crossover point and
w2 after it. This regularization technique prevents the network from assuming that adjacent styles are correlated。
为了进一步鼓励样式的本地化,我们采用了混合正则化的方法,即在训练过程中使用两个随机的潜在代码而不是一个潜在代码来生成给定百分比的图像。当生成这样的图像时,我们只需在合成网络中随机选择的点上从一个潜在代码转换到另一个潜在代码——我们称之为样式混合的操作。具体来说,我们通过映射网络运行两个潜在码z1,z2,并让相应的w1,w2控制样式,使w1在交叉点之前应用,w2在交叉点之后应用。这种正则化技术防止了网络假设相邻的样式是相关的。
2、Stochastic variation
There are many aspects in human portraits that can be regarded as stochastic, such as the exact placement of hairs, stubble, freckles, or skin pores. Any of these can be randomized without affecting our perception of the image as long as they follow the correct distribution. Let us consider how a traditional generator implements stochastic variation. Given that the only input to the network is through the input layer, the network needs to invent a way to generate spatially-varying pseudorandom number from earlier activations whenever they are needed. This
consumes network capacity and hiding the periodicity of generated signal is difficult — and not always successful, as evidenced by commonly seen repetitive patterns in generated images. Our architecture sidesteps these issues altogether by adding per-pixel noise after each convolution.
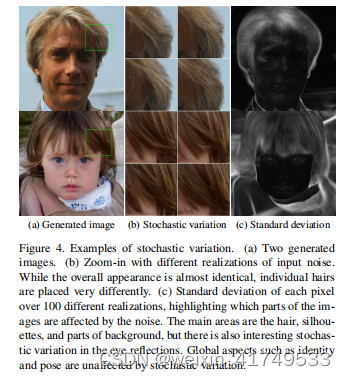
Figure
4
shows stochastic realizations of the same underlying image, produced using our generator with different noise realizations. We can see that the noise affects only the stochastic aspects, leaving the overall composition and high-level aspects such as identity intact. Figure
5
further illustrates the effect of applying stochastic variation to different subsets of layers. Since these effects are best seen in animation, please consult the accompanying video for a demonstration of how changing the noise input of one layer leads to stochastic variation at a matching scale。
在人类肖像中有很多方面可以被认为是随机的,比如头发、胡茬、雀斑或皮肤毛孔的精确位置。任何这些都可以随机化,而不影响我们对图像的感知,只要它们遵循正确的分布。让我们考虑一下传统的生成器是如何实现随机变化的。鉴于网络的唯一输入是通过输入层,网络需要发明一种方法来产生空间变化的伪随机数,从任何需要时的早期激活开始。这消耗了网络容量,隐藏生成信号的周期性是困难的——而且并不总是成功的,生成图像中常见的重复模式就证明了这一点。
我们的架构通过在每次卷积后添加每像素的噪声,完全避开了这些问题。图4显示了相同的底层图像的随机实现,使用我们的生成器产生了不同的噪声实现。我们可以看到,噪声只影响随机的方面,而保持整体的组成和高水平的方面,如身份不变。图5进一步说明了随机变化对不同层子集进行随机变化的效果。由于这些效果在动画中表现得最好,请参考附带的视频来演示如何改变一层的噪声输入会导致匹配尺度上的随机变化。
3、
Separation of global effects from stochasticity
The previous sections as well as the accompanying video demonstrate that while changes to the style have global effects (changing pose, identity, etc.), the noise affects only inconsequential stochastic variation (differently combed hair, beard, etc.). This observation is in line with style transfer literature, where it has been established that spatially invariant statistics (Gram matrix, channel-wise mean, variance, etc.) reliably encode the style of an image [
20
,
39
] while spatially varying features encode a specific instance. In our style-based generator, the style affects the entire image because complete feature maps are scaled and biased with the same values. Therefore, global effects such as pose, lighting, or background style can be controlled coherently. Meanwhile, the noise is added independently to each pixel and is thus ideally suited for controlling stochastic variation. If the network tried to control, e.g., pose using the noise, that would lead to spatially inconsistent decisions that would then be penalized by the discriminator. Thus the network learns to use the global and local channels appropriately, without explicit guidance.
前面的部分以及伴随的视频表明,虽然风格的改变会产生全局效果(改变姿势、身份等),噪音只影响无关紧要的随机变化(不同梳头的头发、胡须等)。这一观察结果与风格转移文献相一致,其中已经建立了空间不变统计量(格兰克矩阵、通道均值、方差等)。可靠地编码一个图像[20,39]的样式,而空间变化的特征编码一个特定的实例。在我们的基于样式的生成器中,样式会影响整个图像,因为完整的特征映射会使用相同的值进行缩放和偏置。因此,诸如姿势、灯光或背景风格等全局效果可以被一致地控制。同时,噪声被独立地添加到每个像素中,因此非常适合于控制随机变化。如果网络试图控制,例如,使用噪声的姿态,这将导致空间上不一致的决定,然后将受到鉴别器的惩罚。因此,网络在没有明确指导的情况下,学习适当地使用全局和本地通道。
一篇很好的解释链接:
StyleGAN 和 StyleGAN2 的深度理解 - 知乎 (zhihu.com)















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









