







文章目录
对于商品的管理来说, 新增 商品,需要 增加 SPU 和 SKU; 修改 商品,需要 修改 SPU 和 SKU (新增 与 修改,和上篇博客中管理的 tb_template、tb_spec、tb_para 模板、规格、参数表,还和 tb_sku 某款商品中某类商品的信息表、 tb_spu 某款商品中某类商品的信息表 有关);审核,需要 修改审核状态;上架下架,需要 修改上架下架状态。
而 删除商品,分为 :
- 逻辑删除:修改了删除状态,“找回商品”,找回的一定是逻辑删除的商品。
- 物理删除:真实删除了数据
一、SPU 与 SKU
1、SPU 与 SKU 的概念
- SPU:Standard Product Unit ,标准产品单位,描述某一款商品的公共属性。SPU 是商品信息聚合的最小单位,是一组 可复用、易检索 的 标准化信息 的集合,该集合 描述了一个产品的特性,是对 同款商品的公共属性 抽取。通俗点讲,属性值、特性相同的货品 就可以称为一个 SPU,比如 华为 nova6SE 手机是一个 SPU 。
- SKU: stock keeping unit,库存量单位,即库存进出计量的单位, 可以是以 件、盒、托盘 等为单位。 SKU 是物理上不可分割的最小存货单元。在使用时要根据不同业态,不同管理模式来处理。在服装、鞋类商品中 使用 最多 最普遍。是 某个库存单位的商品独有属性 (某个商品的独有属性),比如 华为nova6SE 红色 64G 就是一个 SKU。
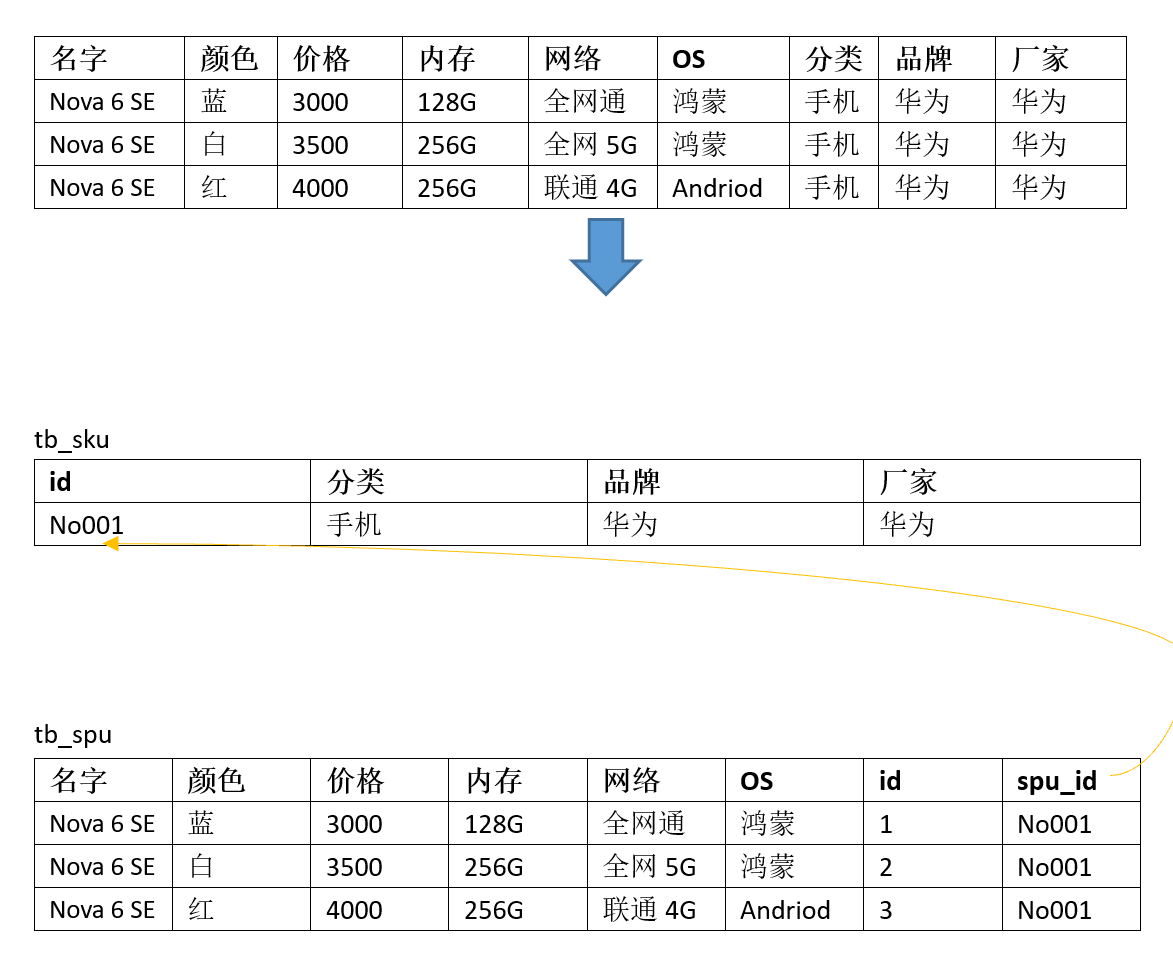
把重复的属性值抽取出来,更节省空间,不过缺点是,需要进行管理时,要将两个表关联起来。
2、tb_spu、tb_sku 表结构分析
- tb_spu 表
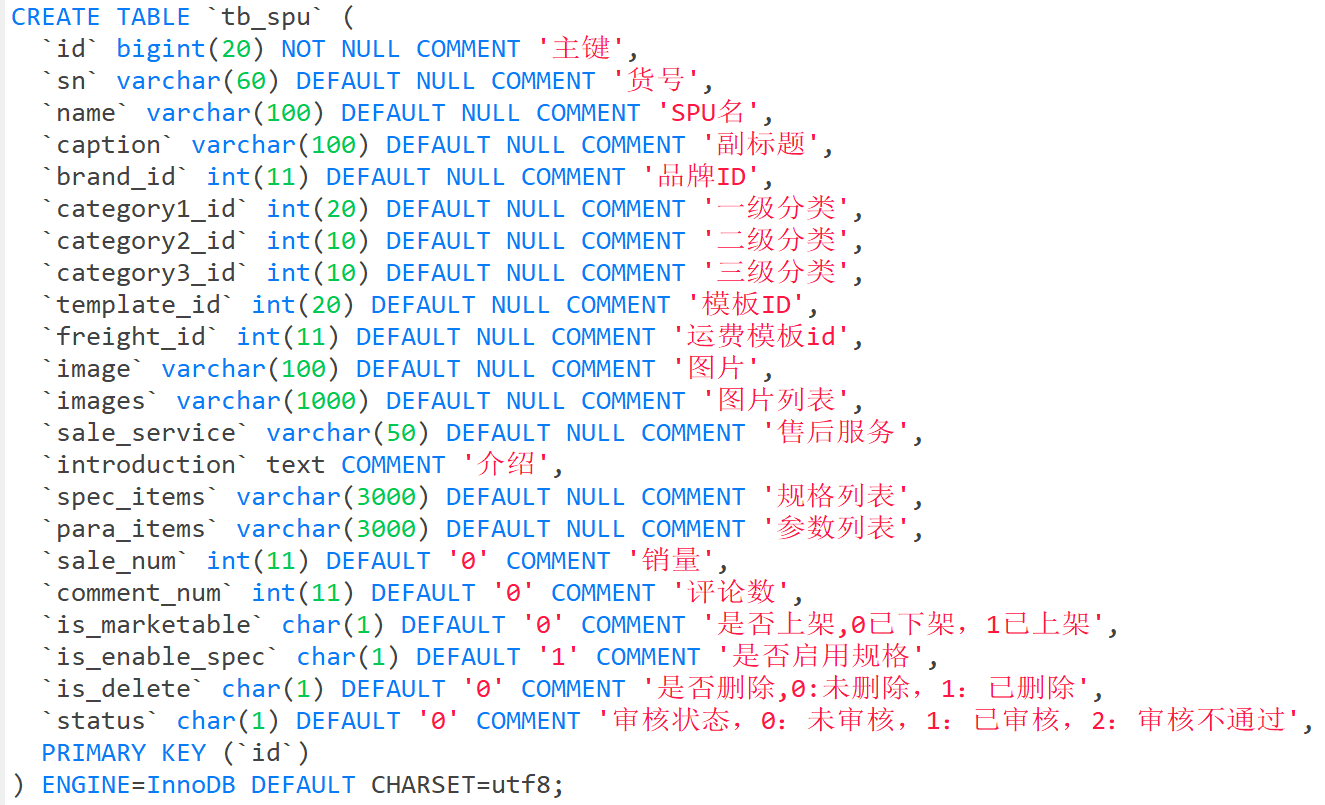
可以看到,对于同款商品来说,这些属性都是公共属性。
其中,在 tb_category 分类表中,parent_id=0 的记录就是 “一级分类”:
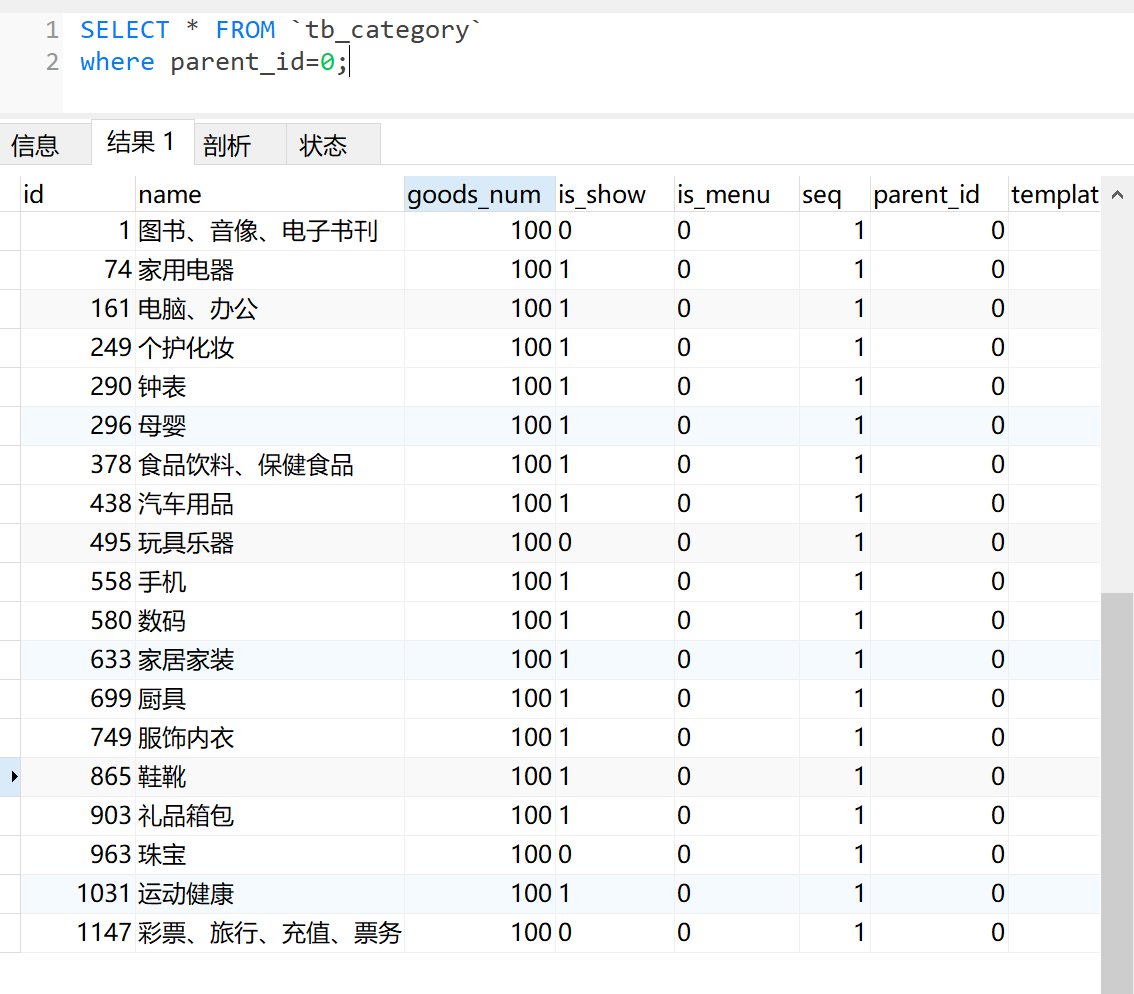
二级分类是将选中的一级分类作为子分类,继续查询,比如 ” 865 鞋靴”,查询它的子分类:
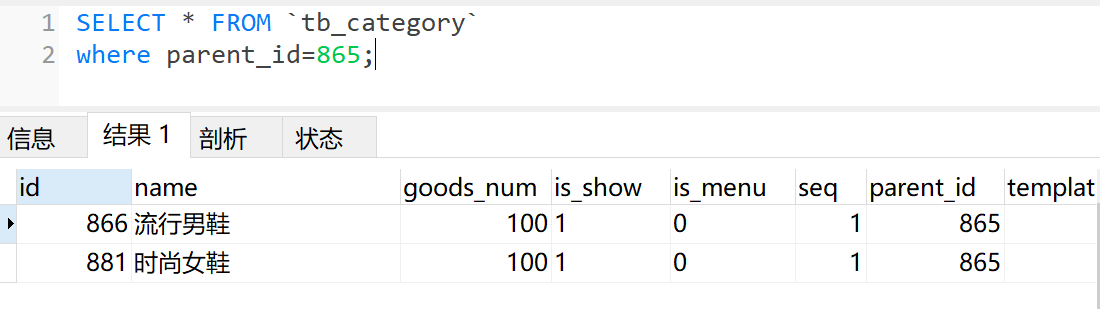
同理,再看看 866 流行男鞋的子分类,这是 “三级分类”:
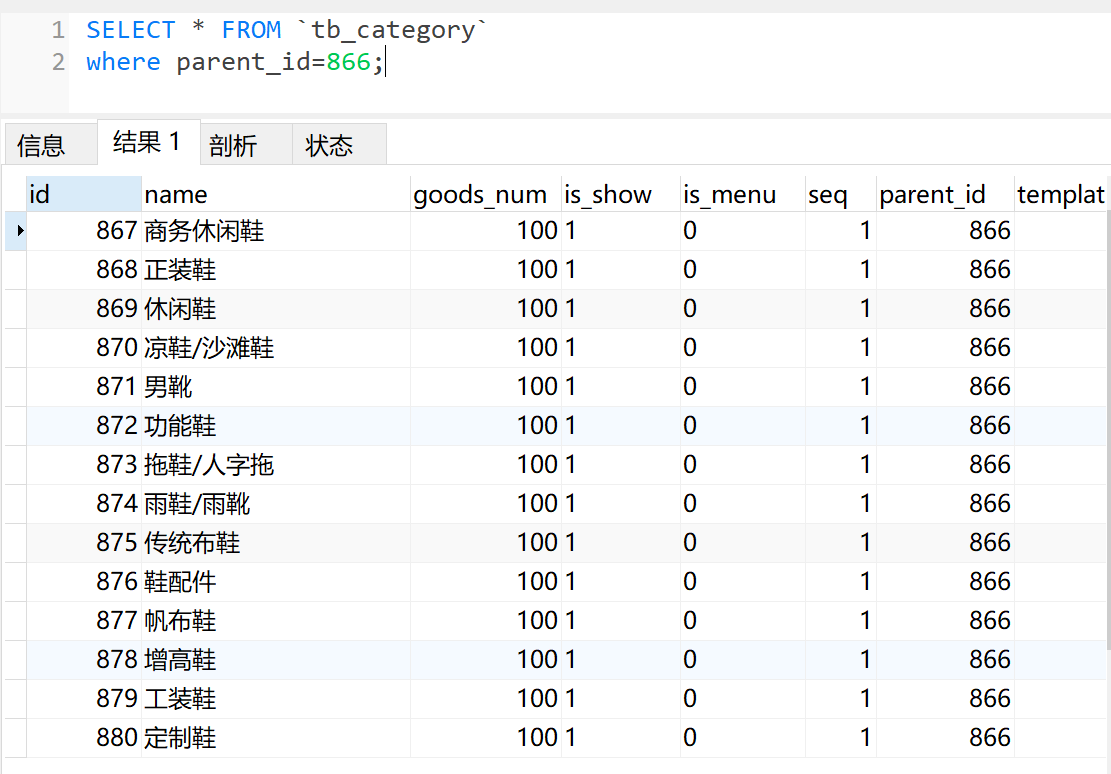
总得来说,就是通过父节点 ID 去查询子分类。
- tb_sku 表

tb_spu 和 tb_sku 两张表通过 spu_id 进行外键关联。
二、商品管理
在新增 和 修改 商品中,主要是对规格 和 参数 的选择。
规格 ,比如说 尺寸、网络(3G?4G?5G?)、颜色,是根据模板 ,比如说 手机、电视,选择出来的,使用者选择的分类 比如说 11536 手机配件,可以查出它属于模板 手机。总得来说,就是 category —> template——>spec。
参数,类似于我们点开“商品详情” 时展示的参数,也是通过 template 选择出来的。
1、代码生成
上一篇实战中写了很多增删改查方法,现在我们使用一个开源的 基于 Framemarker 模板引擎的 代码生成器,即便是一个工程几百个表,也可以瞬间完成代码的构建,用户只需要建立数据表结构,运行 main 方法就可以快速构建生成微服务工程的 pojo、Service、Controller 各层,并且可以生成 swagger API 模板等。用户通过自己开发模板,也可以生成 php、C#、C++、数据库存储过程等其他编程语言的代码。
开源地址:https://github.com/shenkunlin/code-template.git
把它 clone 下来,然后放在 ChangGou 项目中。
需要修改配置文件 application.properties 里的路径:
#pojo包路径
pojoPackage=com.changgou.goods.pojo
#Dao包路径
mapperPackage=com.changgou.goods.dao
#service接口包路径
serviceInterfacePackage=com.changgou.goods.service
#service接口实现包路径
serviceInterfaceImplPackage=com.changgou.goods.service.impl
#controller包路径
controllerPackage=com.changgou.goods.controller
#feign包路径
feignPackage=com.changgou.goods.feign
#是否启用swagger
enableSwagger=true
#swagger-ui 的路径
swaggeruipath=com.changgou.swagger
#服务名字,用于生成feign
serviceName=goods
#数据源配置
url=jdbc:mysql://192.168.211.132:3306/changgou_goods
uname=root
pwd=123456
driver=com.mysql.jdbc.Driver
然后运行 main 方法即可,它就会为我们生成 dao、service、feign、swagger 包及代码,不过是在 code_template 下生成的,而且因为缺少依赖,会爆红,所以我们需要把这些代码拷贝到 changgou-parent 项目中:(feign 暂时不拷)
可以看到,这些方法只是对于该表的增删改查,查包括条件查询、分页查询 和 分页条件查询,不过对于多表关联的情况,并没有实现关联查询,这部分还是需要手写的。
一会儿会用到 ID 生成,我们可以使用 idWorker,在启动类 GoodsApplication 中添加以下代码,用于创建 IdWorker,并将它交给 Spring 容器。
public IdWorker idWorker(){
return new IdWorker(0,0);
}
IdWorker 是个实体类,在它的注释中看到,它用于生成 分布式自增长 ID,整体上按照时间自增排序,并且整个分布式系统内不会产生 ID 碰撞(由 datacenter 和 机器ID 作区分), 并且效率较高,经测试,snowflake 每秒能够产生26万ID左右,完全满足需要。
2、查询分类品牌数据
- 根据父 ID 查询所有子分类
按照上文对三个级别分类,需要在 CategoryService 中补充 根据 父 ID 查询所有子分类的方法。
在接口中新增方法:
/* 根据分类的父节点 ID 查询 所有子节点集合*/
List<Category> findByParentId(Integer id);
实现:
public List<Category> findByParentId(Integer pid) {
Category category=new Category();
category.setParentId(pid);
return categoryMapper.select(category);
}
提供控制层代码:
@GetMapping(value = "/list/{pid}")
public Result<List<Category>> findByParentId(@PathVariable Integer pid){
List<Category> categories= categoryService.findByParentId(pid);
return new Result<>(true, StatusCode.OK,"查询子节点成功!",categories);
}
刚进入界面时需要查询 pid=0 也就是父节点的数据,然后根据父节点会去查询子节点。
- 根据分类 ID 查询品牌集合
我们可以通过 brandId 连结 category_brand 和 brand 表。
在接口中添加方法:
/**
* 根据分类 ID 查询品牌集合,
* @param categoryid
* @return
*/
List<Brand> findByCategory(Integer categoryid);
实现:
public List<Brand> findByCategory(Integer categoryid) {
return brandMapper.findByCategory(categoryid);
}
在 dao 层提供方法:
public interface BrandMapper extends Mapper<Brand> {
@Select("select tb.* from tb_brand tb, tb_category_brand tcb where tb.id=tcb.brand_id and tcb.category_id=#{category};")
List<Category> findByCategory(Integer categoryid);
}
控制层:
@GetMapping(value = "/category/{id}")
public Result<List<Brand>> findBrandByCategory(@PathVariable(value = "id")Integer categoryId){
//调用Service查询品牌数据
List<Brand> categoryList = brandService.findByCategory(categoryId);
return new Result<List<Brand>>(true,StatusCode.OK,"查询成功!",categoryList);
}
- 模板查询
当 用户 选中了 分类 后,需要根据分类的 ID 查询出 对应的模板数据,并将模板的名字进行显示。可以通过 template_id 将 category 表 和 template 表进行连结。
在接口中添加方法:
Template findByCategoryId(Integer id);
实现:
public Template findByCategoryId(Integer id) {
Category category = categoryMapper.selectByPrimaryKey(id);
return templateMapper.selectByPrimaryKey(category.getTemplateId());
}
或者可以自己写 sql 语句,在 dao 层添加方法:
@Select("select tem.* from tb_template tem,tb_category cat where tem.id=cat.template_id and cat.id=#{cateId}")
Template findByCategory(Integer cateId);
控制层:
@GetMapping(value = "/category/{id}")
public Result<Template> findByCategoryId(@PathVariable(value = "id") Integer id) {
//调用Service查询
Template template = templateService.findByCategoryId(id);
return new Result<Template>(true, StatusCode.OK, "查询成功", template);
}
- 规格查询、参数查询
都是通过 template_id 连结 分类表 和 规格 / 参数表。通过分类查询模板对应的规格、参数信息,代码就不展示了,为了后续前端页面调用不出错,路径保持一致即可。
可以访问路径验证一下效果:




3、新增商品
因为在新增商品时,需要 spu、sku 的信息,而且 sku 是集合的形式,所以,我们在 pojo 包封装一个 Javabean ,把 spu 和 List 作为属性:
public class Goods implements Serializable {
private Spu spu;
private List<Sku> skuList;
/* 构造方法和getter、setter 方法略*/
因为在 tb_spu 和 tb_sku 表中,ID 都不是自增的,所以需要使用 IdWorker 产生 ID 。
先在 SpuService 中新增方法:
void saveGoods(Goods goods);
实现:
public void saveGoods(Goods goods) {
Spu spu = goods.getSpu();
spu.setId(idWorker.nextId());
// 商品一发布就上架
spu.setIsMarketable("1");
spuMapper.insertSelective(spu);
// Sku 集合
List<Sku> skuList = goods.getSkuList();
for (Sku sku : skuList) {
sku.setId(idWorker.nextId());
// name 由 spu name、规格组成
String spuName = spu.getName();
// 在数据库里规格字段:{"电视音响效果":"立体声","电视屏幕尺寸":"20英寸","尺码":"165"}
// 是 json 形式,需要把它转换成 map
// 防止空指针
if (StringUtils.isEmpty(sku.getSpec())) {
sku.setSpec("{}");
}
Map<String, String> specMap = JSON.parseObject(sku.getSpec(), Map.class);
for (Map.Entry<String, String> entry : specMap.entrySet()) {
spuName += "" + entry.getValue();
}
Date date = new Date();
sku.setCreateTime(date);
sku.setUpdateTime(date);
sku.setSpuId(spu.getId());
// 三级分类
sku.setCategoryId(spu.getCategory3Id());
// 品牌名称是要通过查询才能得到的,所以需要先查询品牌信息
Brand brand = brandMapper.selectByPrimaryKey(spu.getBrandId());
sku.setBrandName(brand.getName());
// 将 sku 添加到数据库中
skuMapper.insertSelective(sku);
}
}
暂不提供控制层。
在修改商品信息前需要先查询出商品信息。
4、查询商品
根据 ID 查询商品详细信息,这里的 ID 应该是 spu 的 ID(在前端页面选中商品图片时,这时是大的分类,比如 华为手机,就相当于选中了商品的 spu,所以应该根据 ID 进行查询,等到商品选定后,就需要进入商品详情页,对规格、参数 等进行细选,比如 颜色、网络、内存。前端页面选中图片后,我们后端就需要给前端传商品大类 和 详情的规格、参数等信息,也就是说 spu 和 sku 都需要提供的,那就是 Goods 类对象咯):
在 spuService 中添加方法:
Goods findGoodsById(Long id);
实现:
public Goods findGoodsById(Long id) {
// 查询 spu
Spu spu=spuMapper.selectByPrimaryKey(id);
// 查询 sku
Sku sku=new Sku();
sku.setSpuId(id);
List<Sku> skuList=skuMapper.select(sku);
Goods goods=new Goods(spu,skuList);
return goods;
}
控制层:
@GetMapping("/goods/{id}")
public Result<Goods> findGoodsById(@PathVariable(value = "id")Long spuid) {
Goods goods=spuService.findGoodsById(spuid);
return new Result<>(true,StatusCode.OK,"查询商品成功",goods);
}
运行结果;
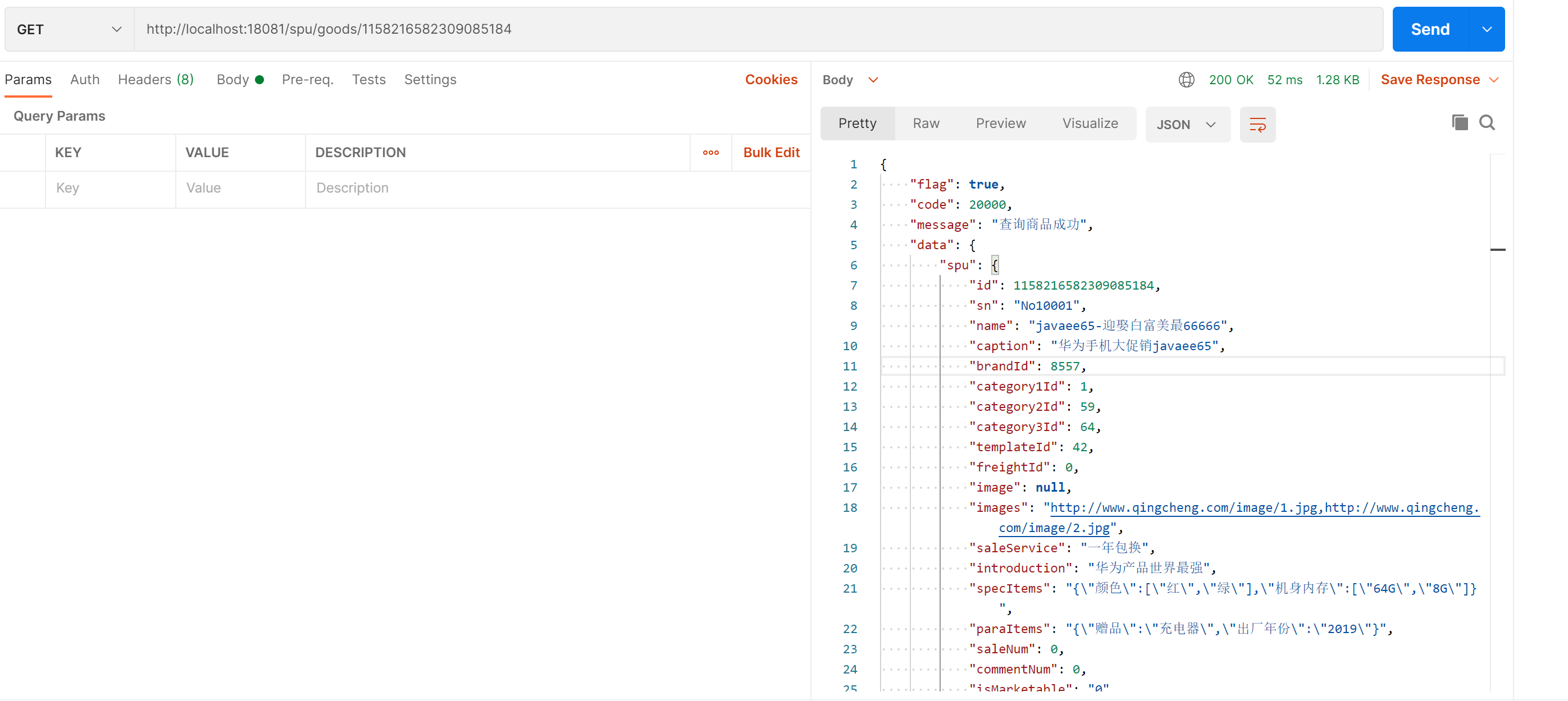
5、修改商品
思路是 先删除原先全部的 sku ,再把现在选择的 sku 进行添加。
添加商品的页面不只是第一次添加商品的时候会访问的,后续也可以进行商品信息的更新的。所以在上面的 saveGoods 方法里添加逻辑,判断是第一次添加商品,还是后续更新商品:
// 修改商品需要先删除原先全部的 sku,再进行添加
// 区分是直接添加商品,还是因为修改商品才进行添加
// 根据 spu ID 是否为空
if (spu.getId() == null) {
// 直接添加商品
spu.setId(idWorker.nextId());
// 商品一发布就上架
spu.setIsMarketable("1");
spuMapper.insertSelective(spu);
}else{
// 修改商品
spuMapper.updateByPrimaryKey(spu);
// 将原先 spu 对应的 sku 全部删除
Sku sku=new Sku();
sku.setSpuId(spu.getId());
spuMapper.delete(spu);
}
剩下的代码部分不变,是对 sku 的处理,为集合中的每一个 sku 设置主键、名字、分类、品牌等属性,并把每一“个”商品对应的 sku 信息插入数据库中。
6、审核商品
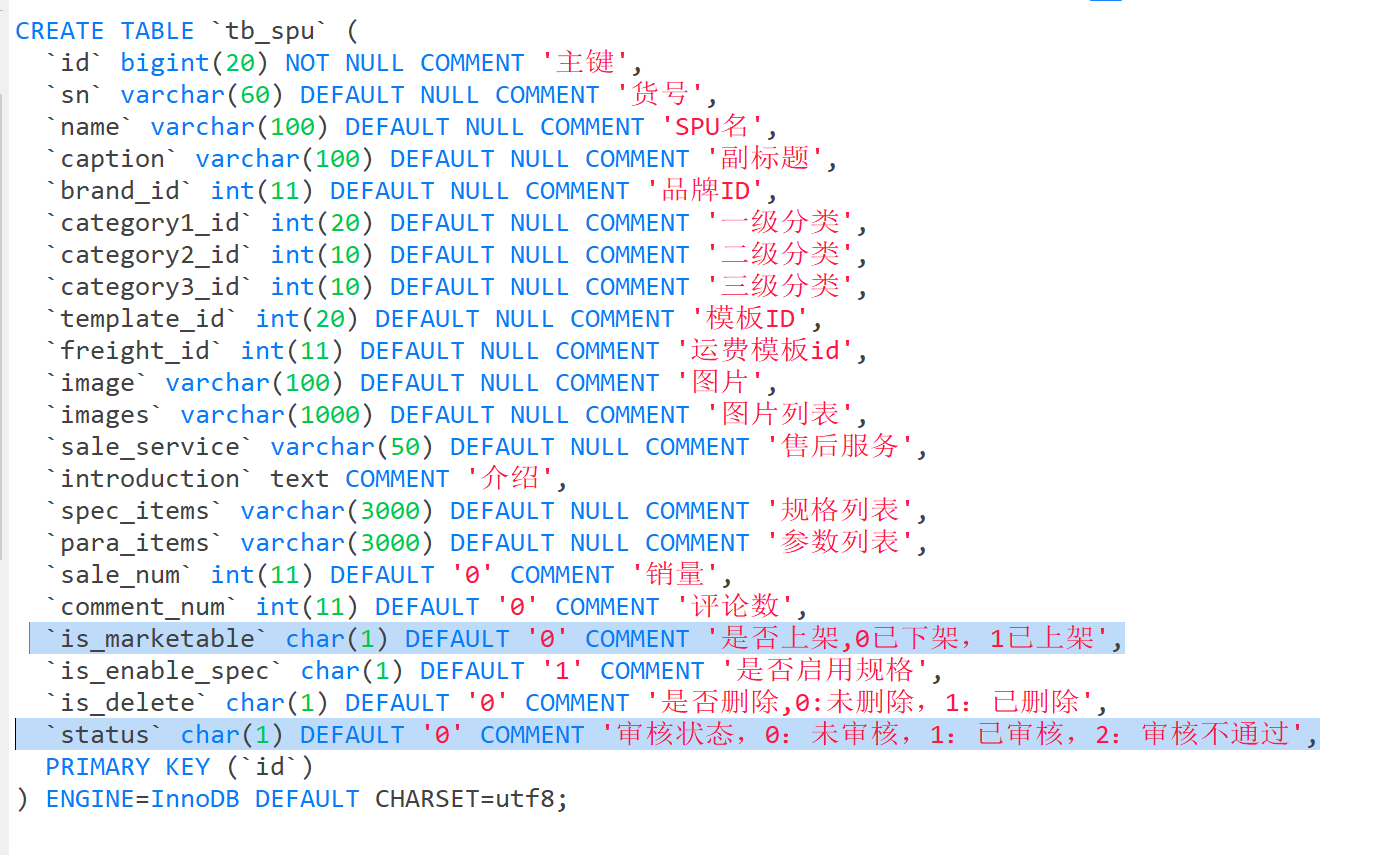
从 tb_spu 表中可以看到,默认情况下是 已下架、未审核状态。(审核状态是在spu 表里的,说明审核是以一款商品为单位的,而不是一个一个商品进行审核。)
审核商品的需求是这样的:
- 需要校验是否是被删除的商品,如果未删除,则修改审核状态为1,即 “ 已审核”,并设置为”已上架“;
下架商品的需求是这样的:
- 需要校验是否是被删除的商品,如果未删除,则设置为 ”已下架“。
(也就是说,审核和下架的前提都是商品未被删除,即 商品要存在,这个前提成立的话,审核和下架就能通过。)
在 spuService 中添加方法:
public void audit(Long spuId);
实现:
public void audit(Long spuId) {
// 先查询商品
Spu spu=spuMapper.selectByPrimaryKey(spuId);
// 判断商品是否被删除
if(spu.getIsDelete().equalsIgnoreCase("1")){
throw new RuntimeException("不能对已删除的商品进行审核");
}
// 审核通过,并自动上架
spu.setStatus("1");
spu.setIsMarketable("1");
spuMapper.updateByPrimaryKeySelective(spu);
}
控制层:
@PutMapping("/audit/{id}")
public Result audit(@PathVariable Long id) {
spuService.audit(id);
return new Result(true, StatusCode.OK, "审核通过" );
}
7、下架商品
在 spuService 中添加方法:
public void pull(Long spuId);
实现:
public void pull(Long spuId) {
// 先查询商品
Spu spu=spuMapper.selectByPrimaryKey(spuId);
// 判断商品是否被删除
if(spu.getIsDelete().equalsIgnoreCase("1")){
throw new RuntimeException("此商品已删除");
}
spu.setIsMarketable("0");
spuMapper.updateByPrimaryKeySelective(spu);
}
控制层:
@PutMapping("/pull/{id}")
public Result pull(@PathVariable(value = "id") Long id) {
spuService.pull(id);
return new Result(true, StatusCode.OK, "下架成功");
}
8、上架商品
实现类:
public void put(Long spuId) {
Spu spu=spuMapper.selectByPrimaryKey(spuId);
// 检查是否删除
if(spu.getIsDelete().equals("1")){
throw new RuntimeException("此商品已删除!");
}
// 检查是否进行了审核
if(!spu.getStatus().equals(1)){
throw new RuntimeException("未通过审核的商品不能上架!");
}
// 上架状态
spu.setIsMarketable("1");
spuMapper.updateByPrimaryKeySelective(spu);
}
控制层:
@PutMapping("/put/{id}")
public Result put(@PathVariable Long id){
spuService.put(id);
return new Result(true,StatusCode.OK,"上架成功");
}
9、批量上架
前端传递一组商品 ID,后端进行批量上下架处理。思路是 从 tb_spu 表中先查询出符合 ID 集的记录,然后检查这些记录是否未删除、通过审核。 (我感觉“通过审核” 和 “上架”的逻辑重复了。只要通过审核就自动上架了啊,为什么还会有专门的上架操作?)
在 service 层添加方法:
public int putMany(Long[] ids);
实现:
public int putMany(Long[] ids) {
// 未删除 已审核的才能上架
// update tb_sku set IsMarkable=1 where id in(ids) and isdelete=0 and status=1
Example example=new Example(Spu.class);
Example.Criteria criteria=example.createCriteria();
criteria.andIn("id", Arrays.asList(ids));
criteria.andEqualTo("is_delete",0);
criteria.andEqualTo("status","1");
Spu spu=new Spu();
// 上架
spu.setIsMarketable("1");
spuMapper.updateByExampleSelective(spu,example);
}
控制层:
@PostMapping("/put/many")
public Result putMany(@RequestBody Long[] ids){
int count=spuService.putMany(ids);
return new Result(true,StatusCode.OK,"成功上架"+count+"个商品")
}
运行结果:

去数据库里查这条记录:
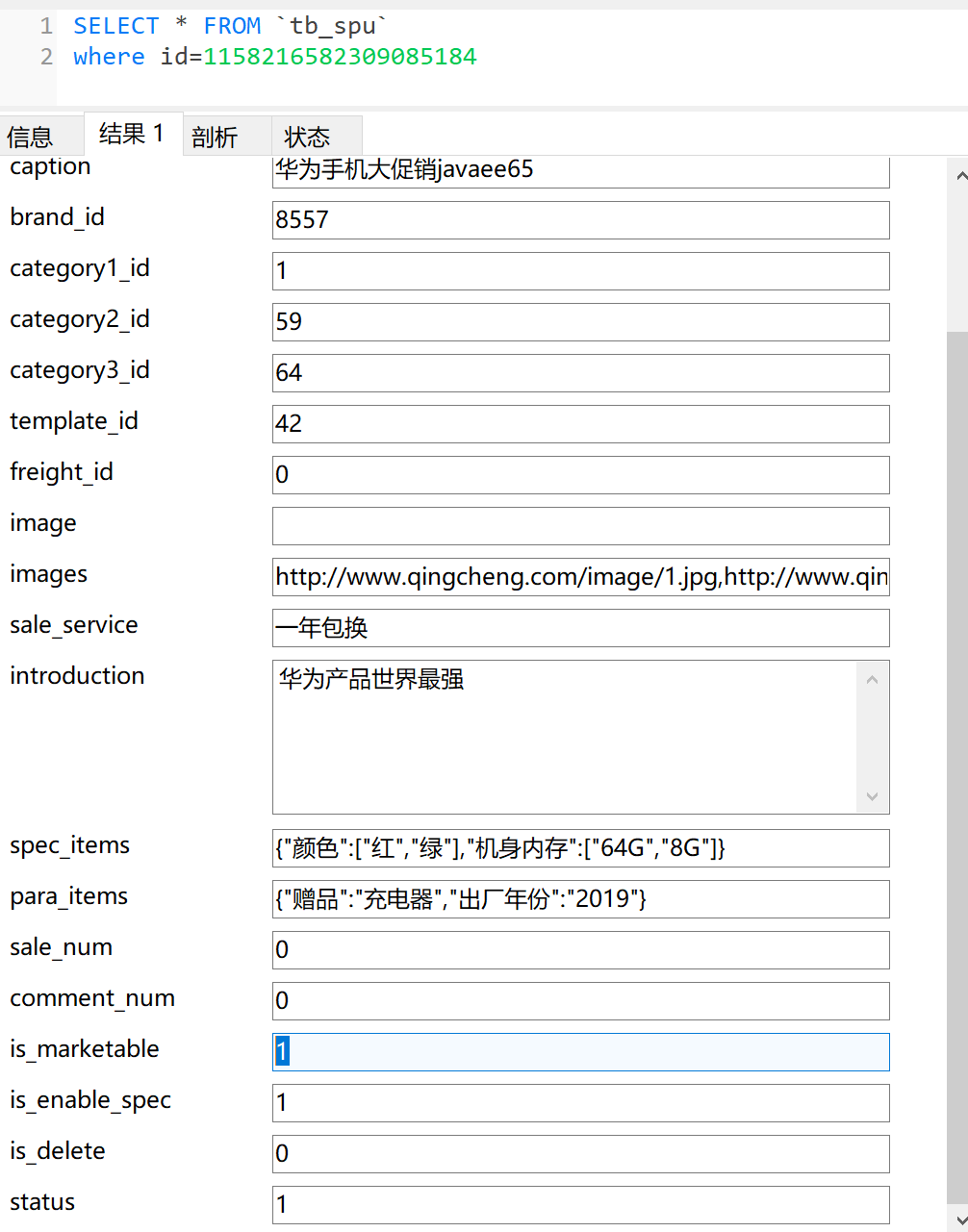
10、批量下架
下架和上架的代码大同小异,这里只贴实现:
public int pullMany(Long[] ids) {
// 未删除 已上架的才能下架
// update tb_sku set IsMarkable=0 where id in(ids) and isdelete=0 and status=1
Example example=new Example(Spu.class);
Example.Criteria criteria=example.createCriteria();
criteria.andIn("id", Arrays.asList(ids));
criteria.andEqualTo("isMarketable","1");
criteria.andEqualTo("isDelete",0);
Spu spu=new Spu();
// 下架
spu.setIsMarketable("0");
return spuMapper.updateByExampleSelective(spu,example);
}
11、删除商品
商品列表中的删除商品功能,并非真正的删除,只是将删除标记的字段设置为1。在回收站中有恢复商品的功能,将删除标记的字段设置为 0。在回收站中有删除商品的功能,是真正的物理删除。
- 逻辑删除商品
在 service 层提供方法:
public void logicDelete(Long spuId);
实现:
@Transactional
@Override
public void logicDelete(Long spuId) {
Spu spu=spuMapper.selectByPrimaryKey(spuId);
// 检查是否是已下架商品
if(!spu.getIsMarketable().equalsIgnoreCase("0")){
throw new RuntimeException("必须先下架再删除!");
}
spu.setIsDelete("1");
// 需要把这个商品置为未审核
spu.setStatus("0");
spuMapper.updateByPrimaryKeySelective(spu);
}
控制层:
@DeleteMapping("/logic/delete/{id}")
public Result logicDelete(@PathVariable Long id) {
spuService.logicDelete(id);
return new Result(true, StatusCode.OK, "逻辑删除成功!");
}
- 还原被删除的商品
添加方法:
public void restore(Long spuId);
实现:
public void restore(Long spuId) {
Spu spu=spuMapper.selectByPrimaryKey(spuId);
// 检查是否是未删除的商品
if(!spu.getIsDelete().equalsIgnoreCase("1")){
throw new RuntimeException("此商品未删除!");
}
// 逻辑恢复
spu.setIsDelete("0");
// 设置为未审核
spu.setStatus("0");
spuMapper.updateByPrimaryKeySelective(spu);
}
控制层:
@PutMapping("/restore/{id}")
public Result restore(@PathVariable Long id){
spuService.restore(id);
return new Result(true,StatusCode.OK,"数据恢复成功!");
}
- 物理删除商品
public void delete(Long id);
实现(原先代码生成器帮我们生成了,现在需要加上物理删除的前提):
public void delete(Long id) {
// 检查是否被逻辑删除,必须先逻辑删除,才能被物理删除
Spu spu=spuMapper.selectByPrimaryKey(id);
if(!spu.getIsDelete().equalsIgnoreCase("1")){
throw new RuntimeException("此商品不能删除!");
}
spuMapper.deleteByPrimaryKey(id);
}
🎉 补充:为什么要实现 Serializable 接口
实现序列化 Serializable接口 ,可以将一个对象的状态 (各个属性值)保存起来,然后在适当的时候再获得。
序列化的过程就是对象写入字节流 (序列化) 和从字节流中读取对象(反序列化), 允许一个对象在虚拟机之间传送 (或者经过一段空间,如在RMI中;或者经过一段时间,比如数据流被保存到一个文件中)。对象序列化可以对对象进行深层复制。
Java 对象序列化 将那些实现了 Serializable接口的对象 转换成一个字节序列,并能够以后将这个字节序列完全恢复为原来的对象。利用对象的序列化,可以实现轻量级持久性,这意味着一个对象的生存周期并不取决于程序是否正在执行,它可以生存于程序的调用之间。通过将一个序列化对象写入磁盘,然后在重新调用程序时恢复该对象,就能够实现持久性的效果。
三、总结
spu 是某款商品公有的属性,sku 是某个商品独有的属性。在前端页面中先选定大的商品,比如 华为Nova6SE,然后再选择一些颜色、规格、网络等,也就是说对商品进行操作,既需要 spu ,又需要 sku,所以封装一个 javabean,把 spu 和 List作为属性。这一篇还是增删改查,而且有代码生成器给我们写好了增删改查。要注意的是一些细节上的逻辑设计,比如说 :
审核商品需要先判断商品是否被删除,审核通过需要改变审核状态,并自动上架;
上架商品需要先判断商品是否被删除,是否被审核;
下架商品需要先判断商品是否被删除,需要先被删除才能下架的;
逻辑删除商品需要先判断商品是否已下架,并把商品设置为未审核状态(否则上架时是没经过审核的,这样的情况在这个情景下没有差别,但是如果审核的逻辑比较复杂,是不能不审核就上架的。)
恢复商品需要先判断商品是否已删除,并把商品设置为未审核状态。
物理删除商品需要先判断是否进行果逻辑删除。

















 2196
2196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









