







 本文详细介绍了如何在XGBoost中处理非数值型特征,包括标签编码、独热编码、目标编码、频率编码和Embedding编码方法。同时探讨了参数调优策略,如子样本比例、列采样比例以及防止过拟合的EarlyStopping技术。此外,还比较了网格搜索和随机搜索的调参方法。
本文详细介绍了如何在XGBoost中处理非数值型特征,包括标签编码、独热编码、目标编码、频率编码和Embedding编码方法。同时探讨了参数调优策略,如子样本比例、列采样比例以及防止过拟合的EarlyStopping技术。此外,还比较了网格搜索和随机搜索的调参方法。
文章目录
1.概述
XGBoost 非常重要,尤其在分类、回归和排名问题上表现卓越。其实际使用场景包括金融风控、医学诊断、工业制造和广告点击率预测等领域。XGBoost以其高效的性能和鲁棒性,成为许多数据科学竞赛和实际项目中的首选算法,极大提高模型准确性并降低过拟合风险。
以下是使用XGBoost算法的一些常见问题:
2.数据准备
在处理数据时候,数据中有一些非数值型的特征,应该怎么处理才能在XGBoost中使用呢?
一般情况下,在XGBoost中处理非数值型特征通常需要进行特征工程的处理,因为XGBoost是一种基于树模型的算法,只能处理数值型的特征。
以下是一些非数值特征转换的使用技巧:
2.1标签编码
将非数值型特征映射为整数。对于每个类别,分配一个唯一的整数值。这可以通过scikit-learn的LabelEncoder来实现。
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
data['categorical_feature'] = label_encoder.fit_transform(data['categorical_feature'])
2.2独热编码
将非数值型特征转换为二进制形式,以表示每个类别是否存在。这可以通过pandas的get_dummies函数来实现。
data = pd.get_dummies(data, columns=['categorical_feature'])
2.3 目标编码
使用目标变量的统计信息(例如均值)代替类别标签。这有助于保留类别之间的关系,并且对于高基数分类特别有用。
target_mean = data.groupby('categorical_feature')['target'].mean()
data['categorical_feature_encoded'] = data['categorical_feature'].map(target_mean)
什么是高基数分类?
高基数分类是指分类任务中类别数量非常大的情况。在机器学习和统计学中,分类任务涉及将输入数据分为不同的类别或标签。当类别数量很大时,就会出现高基数分类的情况。
在传统的分类问题中,类别数量相对较少,而高基数分类通常指的是类别数量远远超过传统分类问题的情况。例如,文本分类问题中,如果要将文档分为成千上万个类别,那么这就是一个高基数分类问题。
高基数分类问题面临一些挑战,包括数据稀疏性、计算复杂性和模型训练的困难。处理高基数分类问题通常需要特殊的方法和技术,以确保模型的性能和效率。这可能涉及到使用特殊的算法、特征工程、降维技术等。
2.4 频率编码
使用每个类别的出现频率来替代类别标签。这也有助于保留类别之间的相对关系。
freq_encoding = data['categorical_feature'].value_counts(normalize=True)
data['categorical_feature_encoded'] = data['categorical_feature'].map(freq_encoding)
2.5 Embedding编码
对于高基数的非数值型特征,可以使用嵌入(Embedding)层来学习表示。这在神经网络中较为常见,可以通过PyTorch实现。
import torch
import torch.nn as nn
class EmbeddingNet(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super(EmbeddingNet, self).__init__()
self.embedding = nn.Embedding(num_embeddings, embedding_dim)
def forward(self, x):
return self.embedding(x)
# 使用例子
embedding_model = EmbeddingNet(num_embeddings=len(data['categorical_feature'].unique()), embedding_dim=10)
embedded_data = torch.tensor(data['categorical_feature'].values, dtype=torch.long)
result = embedding_model(embedded_data)
2.6 自定义变换
根据业务逻辑,可以使用其他自定义的方法来将非数值型特征转换为数值型特征。
在实际应用中,可以根据数据的性质和问题的要求选择合适的方法。同时,建议使用交叉验证等技术来评估不同的编码方式对模型性能的影响。
尤其是在使用XGBoost等模型时,需要根据具体问题和数据集的特点进行权衡和选择。
3. 参数调优
在XGBoost中,子样本比例和列采样比例是两个重要的超参数,分别用于控制每棵树的训练数据和特征的采样比例。
这两个参数的调整可以对模型的性能产生显著影响。
- 子样本比例(subsample):
定义: 表示每棵树的训练样本的比例。取值范围在0到1之间。
作用: 控制每棵树对训练数据的采样比例,可以防止过拟合。
调整方法: 如果模型过拟合,可以减小该值;如果模型欠拟合,可以适度增加。
params = {
'subsample': 0.8 # 例如,设置子样本比例为0.8
}
- 列采样比例(colsample_bytree):
定义: 表示每棵树的特征采样比例。取值范围在0到1之间。
作用: 控制每棵树对特征的采样比例,可以增加模型的多样性。
调整方法: 如果特征维度较高,可以适度减小该值;如果模型对特征过拟合,可以增大该值。
params = {
'colsample_bytree': 0.9 # 例如,设置列采样比例为0.9
}
- 其他相关参数:
XGBoost还有其他与采样相关的参数,例如colsample_bylevel(每层的列采样比例)和colsample_bynode(每个节点的列采样比例)。这些参数可以根据实际情况进行调整。
params = {
'colsample_bylevel': 0.8, # 例如,设置每层的列采样比例为0.8
'colsample_bynode': 0.7 # 例如,设置每个节点的列采样比例为0.7
}
- 调参流程:
1)通过交叉验证等方式,尝试不同的子样本比例和列采样比例的组合。
2)可以使用Grid Search或Random Search等调参方法,寻找最优的超参数组合。
4. 防止过拟合和欠拟合
Early Stopping (早停)是用来防止过拟合的一种技术,它在训练模型过程中监控模型的性能指标,并在模型性能停止提升时提前停止训练,从而防止模型在训练集上过度拟合,提高模型的泛化能力。
在 XGBoost 中,Early Stopping 的主要目标是监控验证集(validation set)的性能,并在性能不再提升时停止训练。
下面总结是在 XGBoost 中如何使用 Early Stopping 的一般步骤:
-
准备数据集: 将数据集划分为训练集和验证集,通常采用交叉验证的方式。
-
定义模型: 使用 XGBoost 的 Python 接口(xgboost 包)定义一个基本的模型,设置好基本参数,如 learning rate、max depth 等。
-
配置 Early Stopping 参数: 设置 Early Stopping 相关的参数,主要包括
early_stopping_rounds和eval_metric。early_stopping_rounds表示在验证集上连续多少轮(boosting rounds)性能没有提升时停止训练。eval_metric是用来评估模型性能的指标,例如,可以选择使用 ‘logloss’ 作为评估指标。 -
训练模型: 使用训练数据集拟合模型,同时传入验证数据集,以便监控模型在验证集上的性能。
-
应用 Early Stopping: 在训练过程中,当连续指定的轮数上验证集上的性能没有提升时,训练将提前停止。这是通过设置
early_stopping_rounds参数实现的。
5. 特征工程
引入交叉特征,通常是指通过将不同特征的组合作为新特征引入模型,以捕捉特征之间的相互作用关系。这样的特征工程手段有助于提高模型性能,因为它们能够更好地捕捉数据中的非线性关系和交互效应。通过引入交叉特征,模型能够更好地适应数据的复杂性,从而提高对目标的预测能力。
特点:
-
捕捉非线性关系: 通过引入交叉特征,模型能够更好地捕捉不同特征之间的非线性关系,从而提高模型的表达能力。
-
增加信息量: 交叉特征能够引入新的信息,帮助模型更好地理解数据中隐藏的模式和规律。
-
处理特征之间的交互效应: 数据中的特征通常不是孤立存在的,它们之间存在着复杂的交互效应。通过引入交叉特征,模型能够更好地捕捉这些交互效应,提高模型的泛化能力。
-
增加模型复杂度: 交叉特征的引入增加了模型的复杂度,使其更能够适应复杂的数据结构,提高了对未见数据的预测能力。
实际中,交叉特征的选择和创建需要根据具体问题和数据的特点来进行,可以使用领域知识或特征重要性等方法来指导特征工程的过程。
6.模型输出
模型中每棵树的结构和决策路径是什么,该怎么理解呢?
每棵树的结构和决策路径是由多个决策节点和叶子节点组成的。XGBoost采用了梯度提升算法,通过迭代地训练一系列的
决策树,并将它们组合起来形成一个强大的集成模型。
-
决策节点(Split Node):在每棵树的节点上,都存在一个决策条件,该条件基于输入特征的某个阈值。决策节点将数据集划分成两个子集,按照特征值是否满足该条件进行划分。
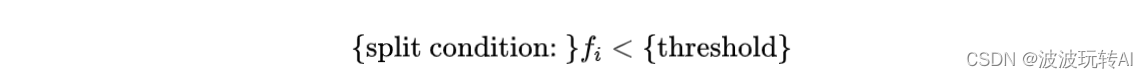
-
**叶子节点(Leaf Node):**在树的末端,叶子节点包含一个预测值。当输入样本通过树的决策路径达到某个叶子节点时,该叶子节点的预测值将被用于最终的模型预测。
-
**树的结构:**XGBoost中的每棵树都是深度有限的,通过限制树的深度可以有效防止过拟合。树的结构是由决策节点和叶子节点的层次组成,形成了一个二叉树结构。树的深度通常由超参数来控制。
-
**决策路径:**每个样本在树上通过一条决策路径,从根节点开始,根据每个节点上的决策条件逐步向下移动,直到达到叶子节点。决策路径就是样本在树上经过的一系列决策节点,这些节点的决策条件构成了样本的决策过程。
-
**理解决策路径:**通过分析每棵树的结构和决策路径,我们可以了解模型是如何对输入特征进行组合和加权的。重要的特征将在树的上层节点上出现,而不太重要的特征可能在树的深层节点上出现。决策路径也反映了模型是如何对不同特征进行组合以做出最终预测的。
7. 调参策略
网格搜索与随机搜索有什么不同?
网格搜索(Grid Search)和随机搜索(Random Search)都是常用的调参方法,它们的主要区别在于搜索参数空间的方式。
- 网格搜索
原理: 网格搜索是一种穷举搜索的方法,它在预定义的参数空间内,通过在每个参数的所有可能组合上进行搜索。通过指定不同的参数组合,网格搜索遍历所有可能的组合,以找到最优的参数。
优点: 简单直观,能够穷尽搜索空间,找到全局最优解的可能性较高。
缺点: 计算开销较大,尤其是当参数空间较大时,需要花费大量的时间和计算资源。
- 随机搜索
原理: 随机搜索通过在参数空间内随机采样一组参数,然后评估模型性能。这个过程重复多次,直到达到指定的搜索次数或时间。相比于网格搜索,随机搜索更注重随机性,通过随机采样更广泛地探索参数空间。
优点: 计算开销相对较小,能够在较短时间内找到较好的参数组合。
缺点: 不一定能找到全局最优解,但可以在较短时间内找到一个较好的局部最优解。
- 选择方法的考虑因素
计算资源: 如果计算资源充足,可以考虑使用网格搜索,以确保穷尽搜索空间。如果计算资源有限,可以选择随机搜索。
参数空间: 如果参数空间较小,网格搜索可能是一个不错的选择。如果参数空间较大,随机搜索更具优势。
时间效率: 如果时间有限,随机搜索可能更适合,因为它在相对短的时间内能够找到较好的参数组合。















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









