






目录
1、简介
你是否曾经有过这样的时刻:猜测另一个人的年纪?下面这个简单的神经网络模型也许可以帮助你。
下面这个你即将运行的demo将会从网络照相机中获取动态的视频流,并给获取到的人脸打上年龄和性别的标签。想象一下,如果我们把一个这样的网络照相机放在你的门口,检测每一个经过的人的性别和年纪,是不是很酷?

我的运行环境是:windows,python3.5。当然,其他操作系统也是可以的。
2、工作流程
如下是整个工作的流程。
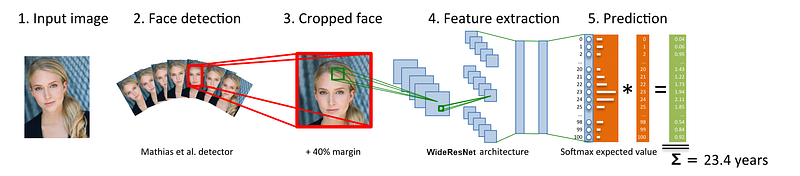
(1)输入图像
首先,通过cv2模块,从网络视频流中获取照片
# 0 means the default video capture device in OS
video_capture = cv2.VideoCapture(0)
# infinite loop, break by key ESC
while True:
if not video_capture.isOpened():
sleep(5)
# Capture frame-by-frame
ret, frame = video_capture.read()
(2)人脸检测
灰度化,再用cv2模块「CascadeClassifier」获取人脸
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.2,
minNeighbors=10,
minSize=(self.face_size, self.face_size)
)人脸检测的结果:一系列人脸的坐标[x, y, w, h]
(3)人脸分割
由于人脸检测可能不一定的框住整张脸,因此将人脸加上40%的周边,从而帮助获取整个脸部。
# placeholder for cropped faces
face_imgs = np.empty((len(faces), self.face_size, self.face_size, 3))
for i, face in enumerate(faces):
face_img, cropped = self.crop_face(frame, face, margin=40, size=self.face_size)
(x, y, w, h) = cropped
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 200, 0), 2)
face_imgs[i,:,:,:] = face_img我们把分割后的人脸输入到模型,接下来就是预测predict了。
(4)特征提取和年龄性别检测
对于年龄预测,模型的输出是101个值,年龄从0~100的概率预测值,这101个值的和为1。
所以,我们把概率乘以对应的年龄值再相加,就得到最后预测的年龄。
if len(face_imgs) > 0:
# predict ages and genders of the detected faces
results = self.model.predict(face_imgs)
predicted_genders = results[0]
ages = np.arange(0, 101).reshape(101, 1)
predicted_ages = results[1].dot(ages).flatten()最后,我们画一下结果图。
性别预测是一个二分类问题。模型的输出是1个范围在0~1的值,值越大,表示模型认为是「男性」的概率越大。
# draw results
for i, face in enumerate(faces):
label = "{}, {}".format(int(predicted_ages[i]),
"F" if predicted_genders[i][0] > 0.5 else "M")
self.draw_label(frame, (face[0], face[1]), label)
cv2.imshow('Keras Faces', frame)
if cv2.waitKey(5) == 27: # ESC key press
break完整的代码和预训练的模型参数见Github:https://github.com/Tony607/Keras_age_gender
3、深入理解
对于那些不满足于demo,想要知道更多关于模型如何建立和训练的同学,这部分可以满足你的要求。
数据集「IMDB-WIKI-500Kfaceimages」:https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
我们输入模型的每一张图片,都进行了上述的预处理:人脸检测和补充周边
神经网络的特征提取使用的是Wide Residual Networks精简版的WideResNet结构。使用CNN学习人脸特征,从不太抽象的边缘、角落特征到更加抽象的眼睛、嘴巴等特征。WideResNet更独特的地方在于,作者减少了原始residual模型的深度,增加了宽度,所以训练的速度快了几倍。具体论文:https://arxiv.org/abs/1605.07146
4、延伸阅读
模型的可能性是无穷尽的,它的输出很大程度上依赖于你给的输入。比如你给的输入是很多标注为很有吸引力的照片,那么,你就会教会模型从网络实时视频流中辨别一个人的魅力指数。
以下是一系列相关的项目,数据集:
Age/Gender detection in Tensorflow
IMDB-WIKI — 500k+ face images with age and gender labels
Data: Unfiltered faces for gender and age classification
Github: keras-vggface
Selfai: A Method for Understanding Beauty in Selfies














 5709
5709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









