







达观杯文本处理(四)--LR,SVM
1.逻辑回归(LR)模型,理论学习和实践
1.1 LR 模型
LR模型可以被认为就是一个被Sigmoid函数(logistic方程)所归一化后的线性回归模型!
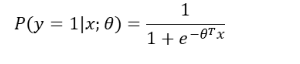
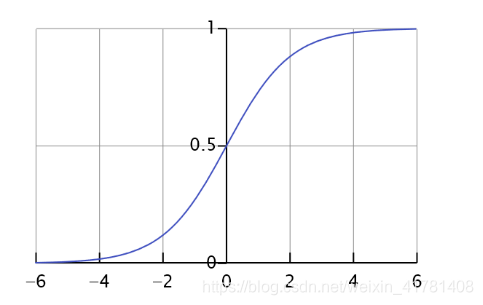
1.2 LR的代价函数(cost function)
根据线性回归模型的经验,我们会选择模型输出与实际输出的误差平方和作为代价函数,如下(公式1.2.1):
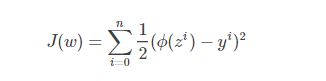
通过最小化代价函数,对参数组w进行求解。但是由于1.1.2属于非凸函数,存在很多的局部最小值,不利于整体求解,于是LR中做如下变通。根据概率的后验估计:
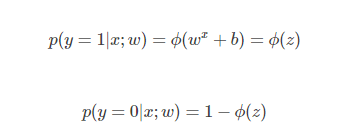
将上面两个公式可以合并为一个:
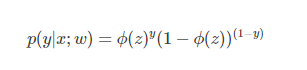
1.3 代码实现
因为在前一个模型保存的时候没有保存x_test,和y_test,所以在读取后又拆分了一次。然后使用逻辑回归来预测了一下。
import pickle
from sklearn.linear_model.< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3407
3407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









