







Python数据分析:文本分类
TF-IDF(词频-逆文档频率):
-
TF,Term Frequency(词频),表示某个词在该文件中出现的次数
-
IDF,Inverse Document Frequency(逆文档频率),用于衡量某个词普遍的重要性
-
TF-IDF = TF * IDF
TF = 当前词在该文档中出现的次数/文档中词的总数
IDF = log(总文档个数/当前词出现的文档个数)
-
例如,一个包含100个单词的文档中出现单词cat的次数为3,则TF=3/100=0.03,样本中一共有10000000个文档,其中出现cat的文档数为1000个,则IDF = log(10000000/1000)= 4
-
则TF-IDF = TF * IDF = 0.03 * 4 = 0.12
NLTK实现TF-IDF
- TextCollection.tf_idf()
from nltk.text import TextCollection
text1 = 'I like the movie so much '
text2 = 'That is a good movie '
text3 = 'This is a great one '
text4 = 'That is a really bad movie '
text5 = 'This is a terrible movie'
# 构建TextCollection对象
tc = TextCollection([text1, text2, text3,
text4, text5])
new_text = 'That one is a good movie. This is so good!'
word = 'movie'
tf_idf_val = tc.tf_idf(word, new_text)
print('{}的TF-IDF值为:{}'.format(word, tf_idf_val))
运行:
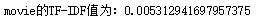
















 6084
6084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











