







方差挑选完毕之后,我们就要考虑下一个问题:相关性了。我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息。如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会给模型带来噪音。在sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。


原来的分数如下图所示,可以看出,模型的效果降低了,这说明我们在设定k=300的时候删除了与模型相关且有效的特征,我们的K值设置得太小,要么我们需要调整K值,要么我们必须放弃相关性过滤。当然,如果模型的表现提升,则说明我们的相关性过滤是有效的,是过滤掉了模型的噪音的,这时候我们就保留相关性过滤的结果

选取超参数K
那如何设置一个最佳的K值呢?在现实数据中,数据量很大,模型很复杂的时候,我们也许不能先去跑一遍模型看看效果,而是希望最开始就能够选择一个最优的超参数k。那第一个方法,就是我们之前提过的学习曲线:


通过这条曲线,我们可以观察到,随着K值的不断增加,模型的表现不断上升,这说明,K越大越好,数据中所有的特征都是与标签相关的。但是运行这条曲线的时间同样也是非常地长,接下来我们就来介绍一种更好的选择k的方法:看p值选择k。
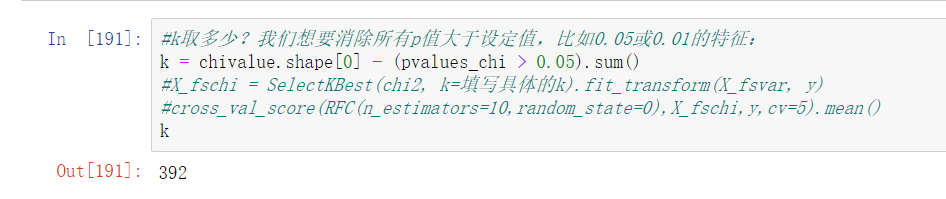
卡方检验的本质是推测两组数据之间的差异,其检验的原假设是”两组数据是相互独立的”。卡方检验返回卡方值和P值两个统计量,其中卡方值很难界定有效的范围,而p值,我们一般使用0.01或0.05作为显著性水平,即p值判断
的边界,具体我们可以这样来看:

从特征工程的角度,我们希望选取卡方值很大,p值小于0.05的特征,即和标签是相关联的特征。而调用SelectKBest之前,我们可以直接从chi2实例化后的模型中获得各个特征所对应的卡方值和P值。


下一节讲F检验和互信息法
资料参考:菜菜的机器学习















 2845
2845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









