







1 信息熵
一条信息的信息量与其不确定性有着直接的关系。
如何一件事情非常不确定,我们要搞清楚就需要了解大量的信息。如果一件事情了解较多,则只需要少量信息就可以搞清楚。
可以认为,信息量就等于不确定性的多少。
下面举一个例子来解释信息量如何进行度量:

但是对于冠军球队的猜测其实信息量可能是更少的,因为每支球队的夺冠概率不一样。因此我们可以先在概率高的球队中进行猜测。
香农指出,它的准确信息量应该是:
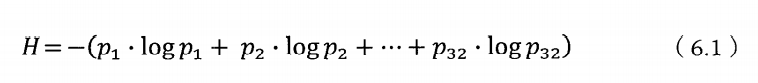
其中,p1,p2,…,p32分别是这32支球队夺冠的概率。香农把它称为“信息熵”,一般用符号H表示,单位是比特。
因此,对于任意一个随机变量X,它的熵定义如下:

变量的不确定性越大,熵就越大,要把它搞清楚,所需信息量也就越大。
2 信息的作用
信息和消除不确定性是相联系的。
信息是消除系统不确定性的唯一办法(在没有获得任何信息前,一个系统就像是一个黑盒子,引入信息,就可以了解黑盒子系统的内部结构)。如下图所示:
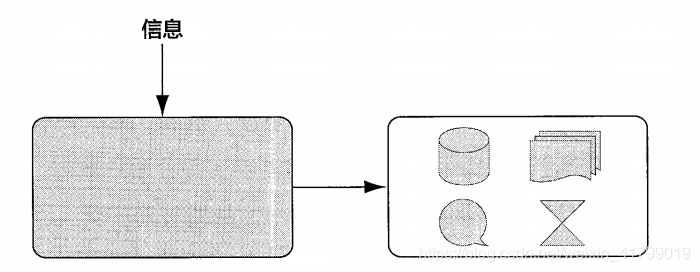
一个事物内部会存在不确定性,假定为U,而从外部消除这个不确定性唯一的办法就是引入信息I,即I>U才行。如果I<U,那么只能消除一部分不确定性。反之,如果没有信息,任何公式或者数字的游戏都无法排除不确定性。 知道的信息越多,随机事件的不确定性就越小。
在实际中,我们经常可以利用上下文的信息来预测一个句子中当前的词汇。因此,相关的信息其实也可以用来消除不确定性。这里就引入了条件熵的概念。
假定X和Y是两个随机变量,X是我们需要了解的。那么就知道了X的熵:

现在假定我们还知道Y的一些情况,包括它和X一起出现的概率,数学上称为联合概率分布P(X,Y)。同时我们还知道条件概率P(X,Y)。这时就可以定义在Y的条件下的条件熵为:
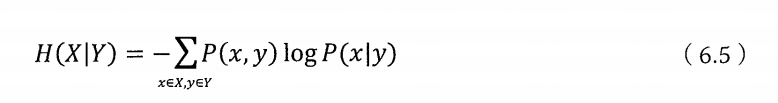
同时我们可以得到H(X)>=H(X|Y),从而也证明二元模型的不确定性会小于一元模型。
进行推广,我们还可以得到两个条件的条件熵:
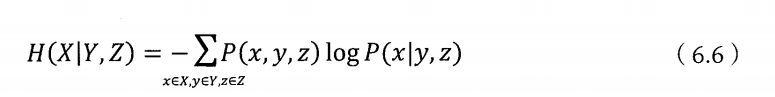
并且可以证明H(X|Y)>=H(X|Y,Z),也就是三元模型会比二元模型好。
那么上述的等号什么时候成立呢?如果引入的信息是无关的信息时,不能减少不确定性,这时等号就是成立的。
3 互信息
上一节中提到,当引入的信息和不确定性有关系时,就能消除不确定性。例子:“今天北京下雨”和“过去24小时北京的空气湿度”,这两个随机变量之间存在多大的相关性。为此,这里引入了“互信息”的概念来描述两个随机事件“相关性”的量化度量。
假定有两个随机事件X和Y,它们的互信息定义如下:
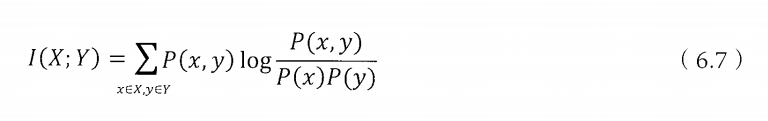
互信息其实就是等于消除的不确定性:

现在就很清晰了,所谓两个事件相关性的度量,就是在了解了其中一个Y的前提下,对消除另一个X不确定性所提供的信息量。
互信息的取值是在0到min(H(X),H(Y))之间的函数,当X和Y完全相关时,它的取值是H(X),同时H(X)=H(Y);当二者完全无关时,它的取值为0。
4 延伸阅读:相对熵
“相对熵”也叫做“交叉熵”,也可以用来衡量相关性,但是变量的互信息不同 ,它用来衡量 两个取值为正数的函数的相似性。定义如下:
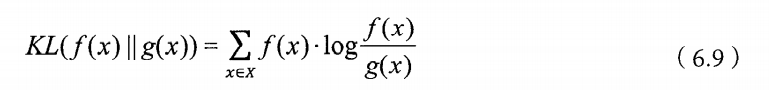
对于这个公式有以下三个结论:
- 对于两个完全相同的函数,它们的相对熵等于零。
- 相对熵越大,两个函数差异越大;反之,相对熵越小,两个函数差异越小。
- 对于概率分布或概率密度函数,如果取值均大于零,相对熵可以度量两个随机分布的差异性。
需要指出的是,相对熵是不对称的,即:
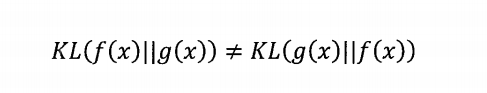
因此通常会两边取平均:
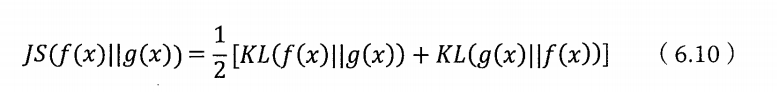
相对熵可以用来衡量两段信息的相似程度。例如如果一篇文章是照抄或改写的,那么它的相对熵就比较小,接近于零。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









