







1 文本和词汇的矩阵
在自然语言处理中,最常见的两个分类问题分别是,将文本按主题归类和将词汇表中的字词按意思归类。
显然,我们可以用上一节的余弦定理来进行计算得到结果,但是耗时会比较长。
因此,本节采用奇异值分解(SVD) 的方法来进行解决。
首先,可以用一个大矩阵来描述成千上万篇文章和几十上百万个词之间的关联性。在这个矩阵中,每一行代表一篇文章,每一列对应一个词,如果有N个词,M篇文章,则得到如下M*N的矩阵,

其中aij代表字典中第j个词在第i篇文章中出现的加权词频。通过这个,就可以将一个特别巨大的矩阵,分解成一个计算机可以存储的小矩阵。如

第一个矩阵X是对词进行分类的结果,每一行代表一个词,每一列表示一个语义相近的语义类,数值越大越相关。如

从矩阵可以看出,第一个词和第一个语义类比较相关,和第二个语义类不太相关,依次类推。
最后一个矩阵Y是对文本的分类结果,它的每一列对应一篇文本,每一行对应一个主题,数值越大越相关。如
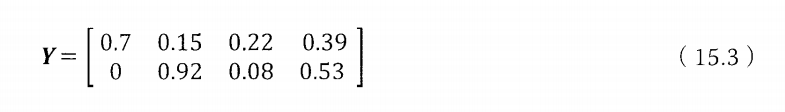
从矩阵可以看出,第一篇文本明显属于第一个主题,和第二个主题完全无关,依次类推。
中间的矩阵表示词的类和文章的类之间的相关性,如

从矩阵可以看出,第一个词的语义类和第一个主题相关,和第二个主题没有太多关系。第二个语义类则相反。
2 奇异值分解的方法和应用场景
这里就主要涉及的是SVD的原理,后续深入学习后补充上。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









