






py获取搜索数据
一、安装所需为软件
**(1)vscode
(2) navicat
(3) python3.8(测试及其正常使用)**
二、正常运行结果展示
1.vscode中正常运行
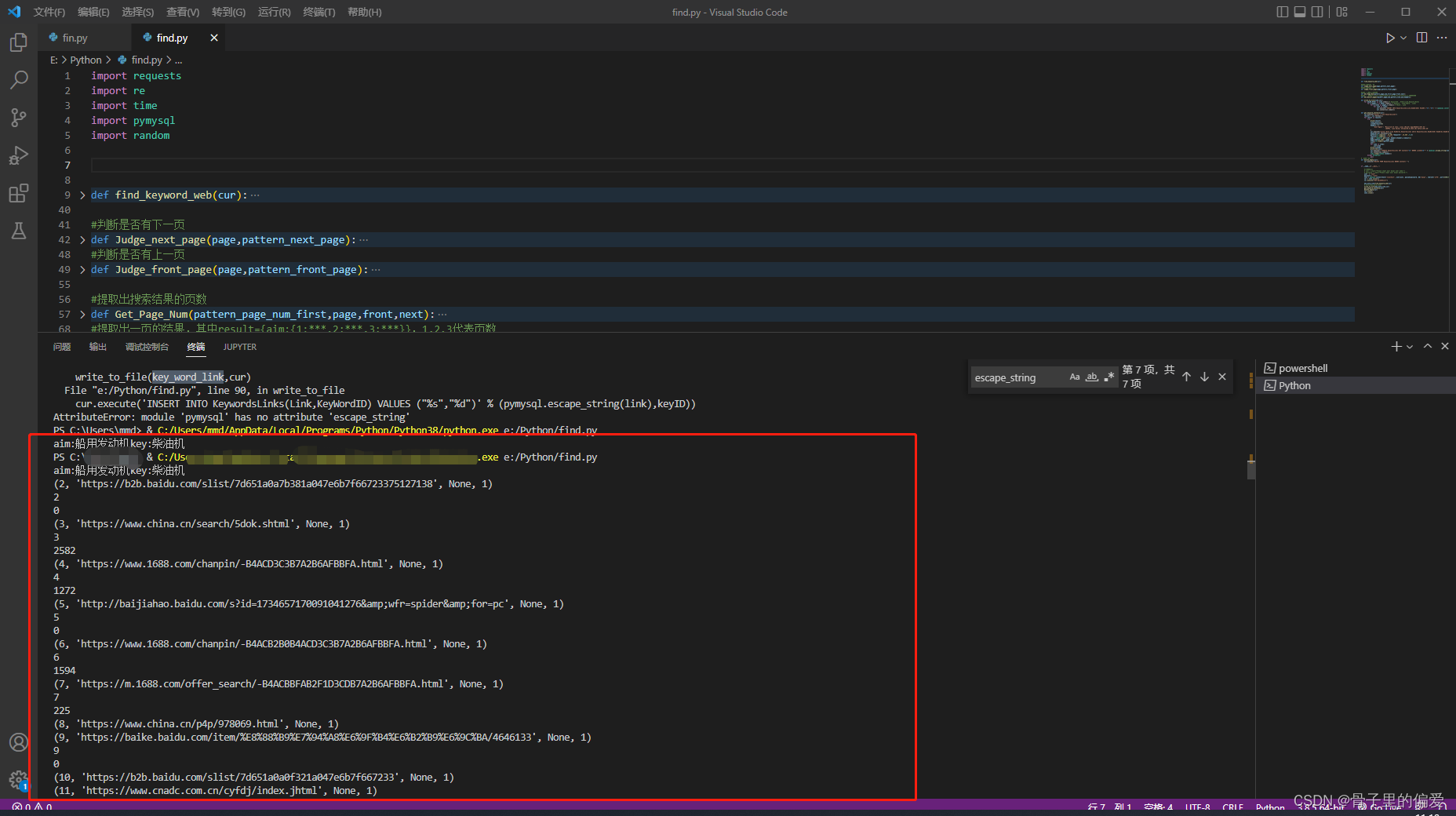
2.nvicat数据库中数据获取情况


注:爬取的数据目前仅支持链接,能够获取到你想要关键字的链接网址,能够精确查找,并保存在数据库中。
import requests
import re
import time
import pymysql
import random
def find_keyword_web(cur):
key_word_link={} #key_word_link:{key1:{aim1:{1:***,2:***,3:***},aim2:{***}},key2:{}},1,2,3代表页数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Cookie':'', #必须添加cookie,否则百度防爬取将会限制你的ip访问,如何获取在下面展示步骤
'sec-ch-ua-platform': "Windows",
'Referer': ''
}
pattern_link=re.compile(r'<h3 class="t">.*?href="(.*?)"',re.S)
pattern_next_page=re.compile(r'下一页',re.S)
pattern_front_page=re.compile(r'上一页',re.S)
pattern_page_num_first=re.compile(r'id="page">(.*?)</p>',re.S)
cur.execute("select * from KeyWords")
fr=cur.fetchall()
for line in fr:
key=line[1]
aim=line[2]
id=line[0]
key_word_link[id]={}
print("aim:"+aim+"key:"+key)
baseUrl = ''
page=1
data = {'wd': aim, 'pn': str(page - 1) + '0', 'tn': 'baidurt', 'ie': 'utf-8', 'bsst': '1'}
first_page=requests.get(baseUrl,params=data,headers=headers)#先爬一页来分析结构
next=Judge_next_page(first_page,pattern_next_page)#判断是否有下一页
front=Judge_front_page(first_page,pattern_front_page)#判断是否有上一页
page_num=Get_Page_Num(pattern_page_num_first,first_page,front,next)#提取出页数 //有问题的部分
key_word_link[id][key]=Get_Result_pages(baseUrl,page_num,pattern_link,aim,headers)
return key_word_link
#判断是否有下一页
def Judge_next_page(page,pattern_next_page):
items=re.findall(pattern_next_page,page.text)
if(len(items)==0):
return False
else:
return True
#判断是否有上一页
def Judge_front_page(page,pattern_front_page):
items = re.findall(pattern_front_page, page.text)
if(len(items)==0):
return False
else:
return True
#提取出搜索结果的页数
def Get_Page_Num(pattern_page_num_first,page,front,next):
aim=re.compile(r'href="(.*?)"',re.S)
item = re.findall(pattern_page_num_first, page.text)
str=item[0]
result=re.findall(aim,str)
length=len(result)
if(front==True) and (next==True):#多了一个链接
length=length-1
if(length==0):#只有一页
length=1
return length
#提取出一页的结果,其中result={aim:{1:***,2:***,3:***}},1,2,3代表页数
def Get_Result_pages(baseUrl,page_num,pattern_link,aim,headers):
result={}
result[aim]=[]
for i in range(page_num):
data = {'wd': aim, 'pn': str(i) + '0', 'tn': 'baidurt', 'ie': 'utf-8', 'bsst': '1'}
page = requests.get(baseUrl, params=data, headers=headers)
items = re.findall(pattern_link, page.text)
result[aim]=result[aim]+items
time.sleep(1)
return result
def write_to_file(link,cur):
for keyID,Other in link.items():# KeywordID , Other(Link,Keyword,Word)
for k,pages_v in Other.items(): # Keyword , other(Word , Link)
for w,links in pages_v.items(): # Word , Link
for link in links:
cur.execute('INSERT INTO KeywordsLinks(Link,KeyWordID) VALUES ("%s","%d")' % (pymysql.converters.escape_string(link),keyID))
cur.connection.commit()
def get_keyword_sentence(cur):
cur.execute("select * from KeywordsLinks")
results = cur.fetchall()
for result in results:
try:
print(result)
link=result[1]
LinkID=result[0]
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
cur.execute("select Word from KeyWords,KeywordsLinks where KeywordsLinks.KeyWordID= KeyWords.KeyWordID and KeywordsLinks.LinkID=(%d)" % int(LinkID))
keyword=(cur.fetchone())[0]
pattern=re.compile(r'.{5,20}'+keyword+r'.{5,20}',re.S)
replace=re.compile(r'<.*?>')
page = requests.get(link, headers=headers,timeout=1)
page=replace.sub('',page.text)
items=re.findall(pattern,page)
con=""
for item in items:
con+=item
print(LinkID)
print(len(con))
cur.execute("""UPDATE KeywordsLinks SET Content="%s" WHERE LinkID=%d""" % (pymysql.escape_string(con),LinkID))#escape_string将用户的输入进行转义,防止SQL注入
cur.connection.commit()
time.sleep(random.random())
except Exception:
pass
#删除表中的空值
def delete_empty(cur):
cur.execute("DElETE FROM KeywordsLinks WHERE Content=''")
if __name__=='__main__':
#连接数据库
# user = input("Please input your mysql user name:")
# password = input("Please input your mysql password:")
#user = "root"
#password = "" #密码修改成自己的一般为root或者123456
conn = pymysql.connect(host='localhost', user=user, passwd=password, db='mysql', charset='utf8', port=3306)#默认为127.0.0.1本地主机
cur = conn.cursor()
cur.execute("USE BaiduResult")
key_word_link=find_keyword_web(cur)
# print(key_word_link)
write_to_file(key_word_link,cur)
get_keyword_sentence(cur)
delete_empty(cur)
cur.close()
conn.close()
三、获取cookie的步骤:
(1)
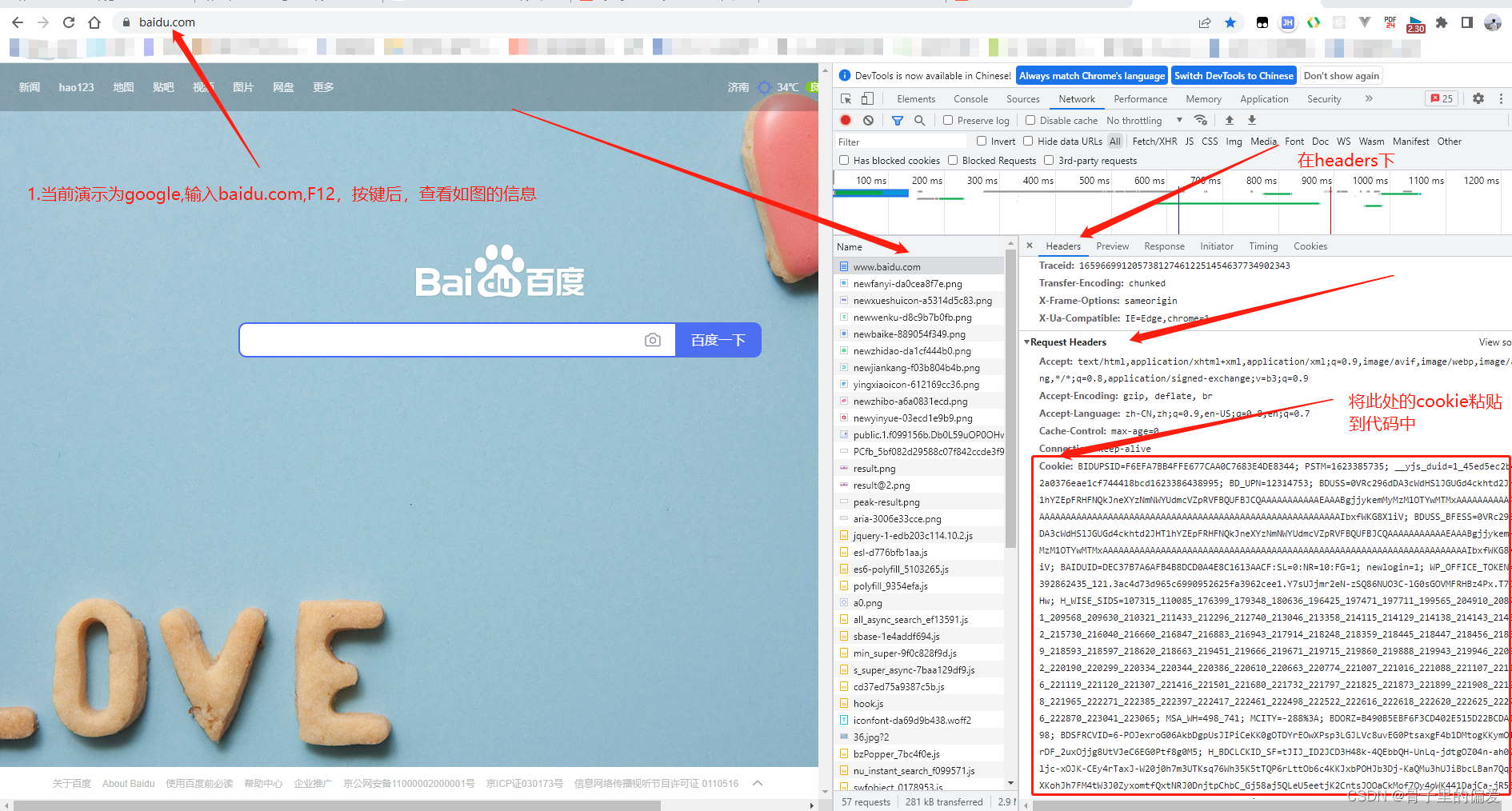
注:需要python3以上,注意安装pymysql时,注意85行,(pymysql.converters.escape_string(link),keyID)
四、演示

















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











