







 本文介绍了推荐系统的重要性和作用,详细讲解了基于用户的协同过滤(User-base CF)算法,包括原理和Java代码实现。通过计算用户相似度,推荐用户未评分但与他们兴趣相符的物品。
本文介绍了推荐系统的重要性和作用,详细讲解了基于用户的协同过滤(User-base CF)算法,包括原理和Java代码实现。通过计算用户相似度,推荐用户未评分但与他们兴趣相符的物品。
推荐算法——基于用户的协同过滤算法(User-base CF)的java实现
推荐系统
什么是推荐系统
平时见过的推荐系统
为什么要有推荐系统
推荐系统的目的:
-
帮助用户找到想要的商品(新闻/音乐/……)
帮用户找到想要的东西,谈何容易。商品茫茫多,甚至是我们自己,也经常点开淘宝,面对眼花缭乱的打折活动不知道要买啥。 -
降低信息过载
互联网时代信息量已然处于爆炸状态,若是将所有内容都放在网站首页上用户是无从阅读的,信息的利用率将会十分低下。因此我们需要推荐系统来帮助用户过滤掉低价值的信息。 -
提高站点的点击率/转化率
好的推荐系统能让用户更频繁地访问一个站点,并且总是能为用户找到他想要购买的商品或者阅读的内容。 -
加深对用户的了解,为用户提供定制化服务
可以想见,每当系统成功推荐了一个用户感兴趣的内容后,我们对该用户的兴趣爱好等维度上的形象是越来越清晰的。当我们能够精确描绘出每个用户的形象之后,就可以为他们定制一系列服务,让拥有各种需求的用户都能在我们的平台上得到满足。
推荐算法
-
基于流行度
基于流行度的算法非常简单粗暴,类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
-
协同过滤算法
协同过滤算法(Collaborative Filtering, CF)是很常用的一种算法,在很多电商网站上都有用到。CF算法包括基于用户的CF(User-based CF)和基于物品的CF(Item-based CF)。
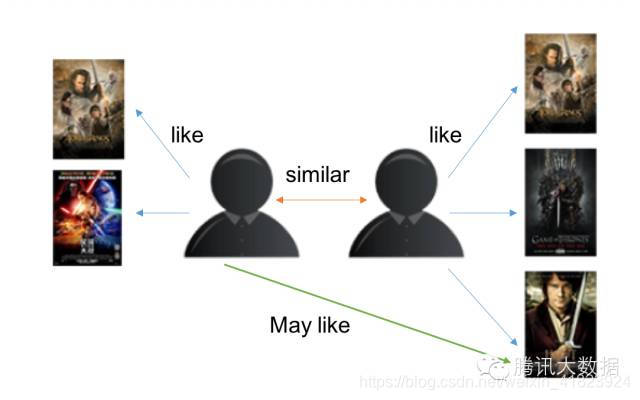
基于用户的CF原理如下:-
分析各个用户对item的评价(通过浏览记录、购买记录等);
-
依据用户对item的评价计算得出所有用户之间的相似度;
-
选出与当前用户最相似的N个用户;
-
将这N个用户评价最高并且当前用户又没有浏览过的item推荐给当前用户。
示意图:
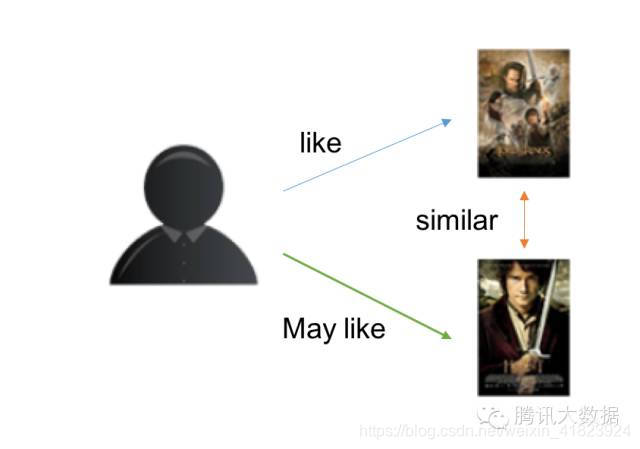
基于物品的CF原理大同小异,只是主体在于物品: -
分析各个用户对item的浏览记录。
-
依据浏览记录分析得出所有item之间的相似度;
-
对于当前用户评价高的item,找出与之相似度最高的N个item;
-
将这N个item推荐给用户。
示意图:
-
-
基于内容的算法
我们注册的时候经常看到这样的界面:
 这个算法就是基于用户的兴趣和物品的tag进行选择的算法。
这个算法就是基于用户的兴趣和物品的tag进行选择的算法。
举个栗子,现在系统里有一个用户和一条新闻。通过分析用户的行为以及新闻的文本内容,我们提取出数个关键字,如下图:
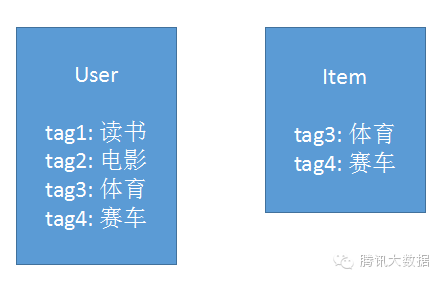 将这些关键字作为属性,把用户和新闻分解成向量,如下图:
将这些关键字作为属性,把用户和新闻分解成向量,如下图:
 之后再计算向量距离,便可以得出该用户和新闻的相似度了。
之后再计算向量距离,便可以得出该用户和新闻的相似度了。
-
基于模型的算法
基于模型的方法有很多,用到的诸如机器学习的方法也可以很深,比如Logistics回归预测等等 -
混合算法
现实应用中,其实很少有直接用某种算法来做推荐的系统。在一些大的网站如Netflix,就是融合了数十种算法的推荐系统。我们可以通过给不同算法的结果加权重来综合结果,或者是在不同的计算环节中运用不同的算法来混合,达到更贴合自己业务的目的。
基于用户的协同过滤算法(User-base CF)
算法介绍
User-based就是把与你有相同爱好的用户所喜欢的物品(并且你还没有评过分)推荐给你:
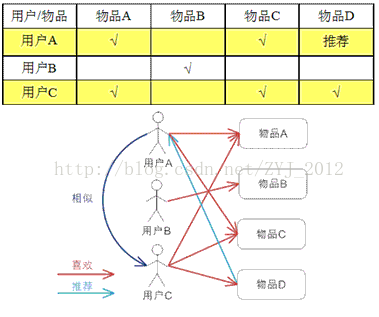
- 算法过程:
- 找到相似度高的用户
- 根据1步骤获取的信息,推荐源用户相对喜欢,并且未采取过的行为
- 计算用户相似度
下面这个是大名鼎鼎的Jaccard公式,很简单, 取2个用户的选择集的交集,跟2个用户的选择集的并集,进行计算。但很显然,若要计算整个用户集合,时间复杂度是O(n^2),太慢了。
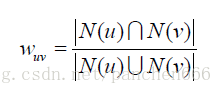
后续就有了利用倒排查表进行优化如下: 可以建立个5X5矩阵,以用户、行为为维度。
| 收藏 | 用户 |
|---|---|
| 1 | 1,2,3 |
| 2 | 2,3,5 |
| 3 | 1,3,5 |
| 4 | 3,4,5 |
| 5 | 2,3,4 |
下面这个公式可以完成之前提到的步骤二,p(u,i)-用户u对行为i的权重,S(u,k)表示和用户u相似的K个用户,N(i)表示采取过行为i的用户集合,W_uv表示用户u和用户v的相似度,R_vi表示用户v对行为i的权重。
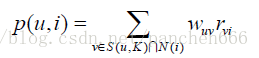
代码实现
public List<TopicView> RecommendTopic(Long uid){
List<Long> userList;
userList=userDao.getAllUserIDlist();
Integer N=userList.size();
// System.out.println("用户数量:"+N);
Long[][] sparseMatrix=new Long[N][N];//建立用户稀疏矩阵,用于用户相似度计算【相似度矩阵】
for(int i=0;i<N;i++){
for(int j=0;j<N;j++)
sparseMatrix[i][j]=(long)0;
}
Map<Long, Integer> userItemLength = new HashMap<> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5116
5116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









